
Os modelos de idiomas são mais caros para treinar e costurar. Isso levou aos investigadores a avaliar estratégias como o modelo, onde um pequeno modelo de aluno é treinado para repetir o desempenho do grande modelo de professores. A idéia é permitir uma remessa eficaz sem comprometer o desempenho. Compreender os termos após a auto-subsuposição e os recursos dos processos de computador podem ser relatados bem entre os alunos e os professores essenciais para melhorar a eficiência.
O tamanho crescente dos modelos de máquina lidera altos custos e desafios de sustentabilidade. O treinamento desses tipos requer recursos de reunião e procedimentos voluntários requer integração adicional. Os custos compatíveis podem ser dramaticamente, de acordo com bilhões de tokens diariamente. Além disso, grandes modelos apresentam desafios visíveis, como aumentar o uso de energia e as dificuldades no processo. A necessidade de reduzir os custos de monitoramento sem sacrificar os modelos moveu os pesquisadores a buscar soluções que estimam a função adequada e a eficiência.
Os métodos anteriores de lidar com as relações de siluths no treinamento de grandes modelos incluem treinamento e brilho de computação e brilho. O treinamento pronto para uso completo determina o tamanho da combinação mais eficaz do modelo e do conjunto de dados dentro do orçamento fornecido. Acesso excessivo ao uso de mais do que parâmetros altos, derrama modelos corretos e eficazes. No entanto, ambas as estratégias têm negociação, como permitir o tempo de treinamento e reduzir o desenvolvimento do desempenho. Embora as pressões e métodos de doseness tenham sido testados, eles geralmente levam a alívio com sucesso. Portanto, é necessária uma maneira mais organizada, como destilação, para melhorar a eficiência.
Os investigadores da Apple e da Universidade de Oxford envolveram a medição de medição do desempenho do modelo quebrado com base na distribuição do orçamento. Essa estrutura ordena a distribuição das fontes computacionais entre professores e modelos e garante eficiência. A pesquisa fornece diretrizes práticas para benefícios de alta qualidade e as melhores condições quando a destilação é pequena no monitoramento. Este estudo estabelece uma relação clara entre os parâmetros de treinamento, o tamanho do modelo e o desempenho do trabalho analisando os principais exames de remoção.
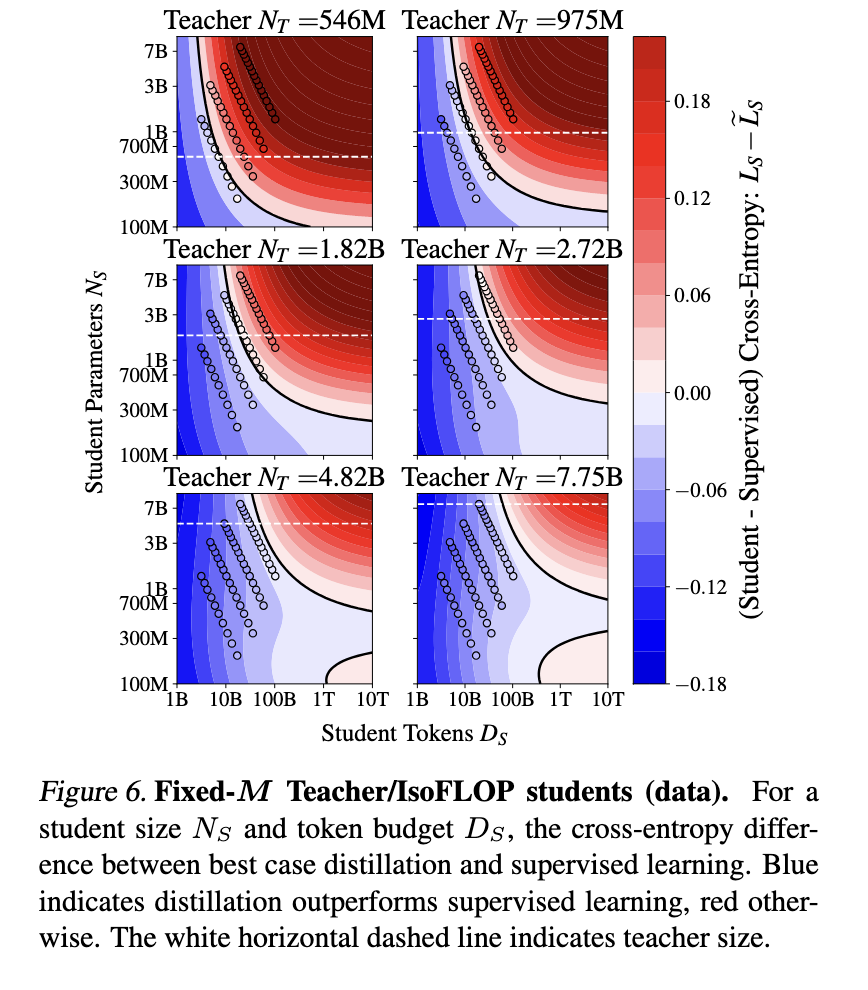
A lei de avaliação proposta descreve como o desempenho dos alunos depende da perda de professores informais, tamanho dos dados e parâmetros do modelo. Os estudos refletem as mudanças entre a aplicação da lei de dois poder, onde o poder do aluno está sujeito a habilidades de ensino relacionadas ao professor. A pesquisa também lida com um penomeno de gap, indicando que, às vezes, professores fortes produziram estudantes fracos. A análise revela que a lacuna se deve às diferenças na posição de aprendizado, e não no tamanho do modelo. Os investigadores mostram que, quando o computação é atribuído adequadamente, a destilação pode comparar ou exceder os métodos educacionais responsáveis por funcionamento eficaz.
As consequências mutuais confirmam a eficácia da medição da lei na criação de um desempenho de modelo. O estudo controlou testes nos modelos dos alunos de 143 a 12,6 milhões de parâmetros, treinados para usar 512 bilhões de tokens. As descobertas indicam que a destilação é alta e vantajosa quando o modelo do professor existe e tokens integrados ou treinados oferecidos ao leitor, não excede o limite do modelo. O aprendizado protegido continua sendo uma maneira mais eficaz quando o professor precisa de treinamento. Os resultados indicam que os estudantes treinados para usar a destilação do Arcouter-Foptillan podem atingir baixas perdas sob as treinadas usando aprendizado monitorado quando a computação é limitada. Especialmente, os testes indicam que a perda da cruz de um aluno está diminuindo como trabalho de acesso de um professor, seguindo um padrão visível que funciona bem.
As regras de assustação da destilação fornece fundamentação para a análise para melhorar a eficiência no treinamento exemplar. Estabelecer um processo de alocação de computador fornece informações importantes sobre a redução dos custos de medição, mantendo o modelo. Os resultados contribuem para uma ampla intenção de tornar o AIS muito eficaz nas aplicações reais de terra. Ao avaliar estratégias de treinamento e exportação, essa função permite o desenvolvimento de submodelos, mas a manutenção mais forte do alto desempenho pelo custo reduzido do computador.
Enquete o papel. Todo o crédito deste estudo é pesquisado para este projeto. Além disso, fique à vontade para segui -lo Sane E não se esqueça de se juntar ao nosso 75k + ml subreddit.
🚨 Recomendado para um código aberto de IA' (Atualizado)
Nikhil é um estudante de estudantes em Marktechpost. Perseguindo graduados integrados combinados no Instituto Indiano de Tecnologia, Kharagpur. Nikhl é um entusiasmo de interface do usuário / ml que procura aplicativos como biomotomentores e ciências biomédicas. Após um sólido na ciência material, ele examina novos empreendimentos e desenvolvendo oportunidades de contribuir.
✅ [Recommended] Junte -se ao nosso canal de telégrafo


