
Grandes modelos de idiomas (LLMS) lida com o seguinte token com base nos dados de instalação, desempenho e, no entanto, sugerem que eles consideram essas informações. Isso levanta as questões que o LLMS participa de planejamento completo antes de produzir respostas completas. Compreender este item pode levar aos programas óbvios de IA, para melhorar a eficiência e fazer uma geração de oponentes.
Um desafio ao trabalhar com o LLMS prevê como as respostas são formadas. Esses modelos produz um texto em uma fileira, o que faz o controle do comprimento desinteressado, profundidade e precisão desafiadora. A falta de processos de planejamento especificados significa que, embora o LLM produza respostas como humano, tomando suas decisões internas sobre o opaco. Como resultado, os usuários geralmente confiam na engenharia instantânea para orientar os resultados, mas esse método não tem precisão e não fornece informações sobre um modelo de resposta natural.
Técnicas existentes para refinar o LLM de saída, incluindo fortalecimento, boa ordem e resgate formal. Os investigadores também tentaram resoluções e uma estrutura externa para acesso. No entanto, esses métodos não são totalmente convincentes como solicitar o LLS.
A equipe de laboratório do laboratório do laboratório Teogetory Tity produziu um novo método analisando apresentações ocultas para tornar os latentes um comportamento de resposta ao planejamento. Suas descobertas sugerem que os LLMs encontraram qualidades essenciais da resposta ou antes que o primeiro token seja produzido. A equipe de pesquisa explorou suas representações ocultas e investiga que o LLMS participa do planejamento de uma resposta excelente. Eles apresentam modelos de teste simples treinados rapidamente para prever qualidades futuras de resposta. O estudo está dividido para organizar três entrevistas principais: atributos organizados, como resposta e responsabilidades, características comportamentais, incluindo opções de personagens na gravação de notícias e confiança em muitas respostas preferidas. Ao analisar padrões nas seções ocultas, os pesquisadores descobrem que essas habilidades de planejamento com tamanho do modelo e de todo o processo de geração.
Para reduzir o planejamento de respostas, os pesquisadores fizeram uma série de testes de teste. Eles treinaram modelos para prever as qualificações de resposta usando envios de estado oculto emitidos antes da geração. Os exercícios mostraram que eles podem ter que prever os próximos recursos. A descoberta revelou que as LLMs codificam qualidades de repetição em sua independência imediata, organizando habilidades começando no início e no fim das respostas. A pesquisa também mostrou que modelos de vários tamanhos compartilham os mesmos comportamentos de planejamento, com modelos grandes mostram mais habilidades de previsão.
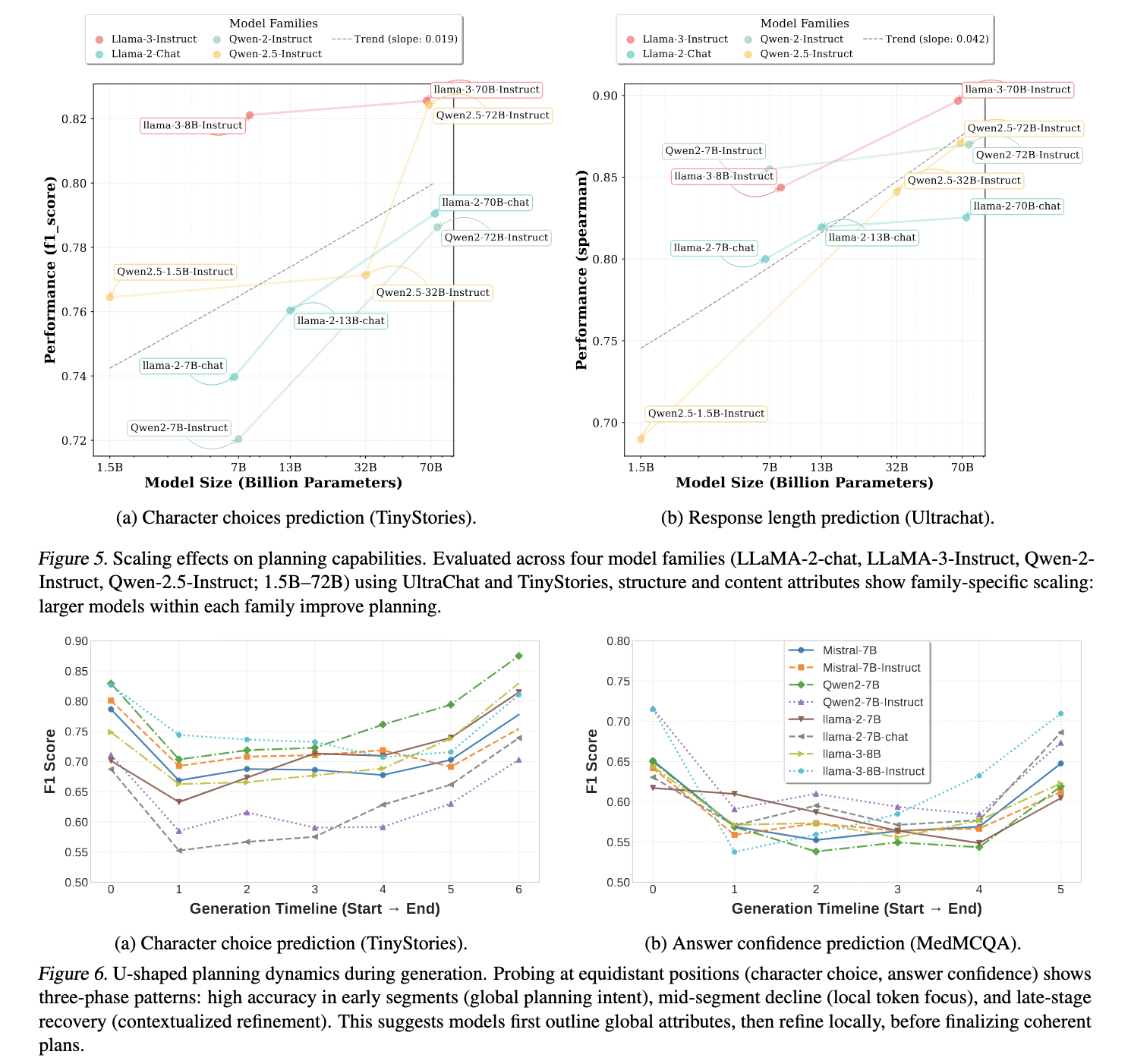
O teste revela um contraste significativo com as habilidades de planejamento entre modelos bem organizados. Modelos bem estruturados mostram melhor precisão de doenças e ética formatizadas, garantindo que o bom comportamento seja fortalecido corretamente. Por exemplo, a resposta da resposta à resposta mostrou coeficientes de alta qualidade em todos os modelos, com a reunião de Spearman até 0,84 de 0,84 às vezes. Da mesma forma, a previsão da etapa de aprendizado mostra forte conformidade com os preços verdadeiros de fato. Diferentes atividades como seleção de personagens na redação e seleção da maioria das seleções mais aleatórias, apoiando a opinião contínua de que os LLMs incluem os entrevistados.
Centenas de modelos mostram altas habilidades de organizar todos os atributos. Nas famílias Llama e Qwen, a melhor edição da organização regularmente para um conselho popular. Estudos descobriram que a LLAMA-3-70B e o ensino QWEN2.5-72B indicam o maior desempenho, enquanto pequenos modelos como acumulados. Além disso, as táticas astutas indicam que as qualidades estruturais aparecem em negrito nas partes centrais, enquanto os atributos de conteúdo são divulgados de acordo com o último aviso. Conduta, como responder à autoconfiança e harmonia convincente, permanece estável em diferentes profundidades.
Esses achados enfatizam o elemento básico do LLM: eles não são apenas o próximo token, mas planejam atributos mais amplos de suas respostas antes de fabricar o texto. Essa capacidade de definir uma resposta consiste em resultados para melhorar a aparência do modelo e do controle. Compreender esses procedimentos internos pode ajudar os modelos de ailet em tempo de ailet, o que leva a melhores previsões e redução reduzida na não geração. Pesquisas futuras podem verificar na combinação de módulos de planejamento claro nos edifícios da LLM para desenvolver a conformidade com a resposta e personalizar o usuário.
Enquete o papel. Todo o crédito deste estudo é pesquisado para este projeto. Além disso, fique à vontade para segui -lo Sane E não se esqueça de se juntar ao nosso 75k + ml subreddit.
🚨 Pesquisa recomendada recomendada para nexo
Nikhil é um estudante de estudantes em Marktechpost. Perseguindo graduados integrados combinados no Instituto Indiano de Tecnologia, Kharagpur. Nikhl é um entusiasmo de interface do usuário / ml que procura aplicativos como biomotomentores e ciências biomédicas. Após um sólido na ciência material, ele examina novos empreendimentos e desenvolvendo oportunidades de contribuir.



