
Combinar pacientes com ensaios clínicos relevantes é um processo importante, mas desafiador, na pesquisa médica moderna. Envolve analisar históricos complexos de pacientes e combiná-los com vários níveis de detalhe encontrados nos critérios de elegibilidade do teste. Esses testes são complexos, imprecisos e inconsistentes, trabalhosos e propensos a erros, ineficientes e atrasam o progresso da pesquisa enquanto muitos pacientes ficam esperando pelo tratamento experimental. Isto é alimentado pela necessidade de escalar grandes conjuntos de testes, especialmente em áreas como oncologia e doenças raras, onde a precisão e a eficiência são altamente valorizadas.
As abordagens comuns para a correspondência entre pacientes e ensaios são duplas: uma é o recrutamento de coorte e a correspondência entre ensaio e paciente, e a segunda é a correspondência entre pacientes e ensaios, que se concentra em encaminhamentos individuais e cuidados centrados no paciente. Apesar disso, várias limitações afetam os métodos baseados em incorporação neural. Essas desvantagens incluem a dependência de grandes conjuntos de dados de anotações que são difíceis de obter, com baixa eficiência computacional e fracas capacidades em termos de aplicações em tempo real. A falta de transparência sobre o prognóstico também mina a confiança dos médicos. Pode-se concluir que tal incompletude exige métodos de dados novos e interpretáveis para melhorar o desempenho uniforme em ambientes clínicos.
Para enfrentar esses desafios, os pesquisadores desenvolveram o TrialGPT, uma estrutura básica que utiliza modelos linguísticos de grande escala (LLMs) para orientar a correspondência entre pacientes e ensaios. Esses três componentes principais compõem a estrutura do TrialGPT: TrialGPT-Retrieval, que filtra ensaios irrelevantes com a ajuda de recuperação híbrida e palavras-chave geradas a partir de resumos de pacientes; TrialGPT-Matching, que realiza uma avaliação detalhada da elegibilidade dos pacientes em nível de critério, fornecendo assim descrições em linguagem natural e informações locais das evidências; e TrialGPT-Ranking, que agrega resultados de nível de critério em pontuações de nível de teste para priorização e liberação. Essa estrutura combina recursos profundos de compreensão e processamento de linguagem natural, garantindo precisão, interpretabilidade e flexibilidade para análise de dados médicos não estruturados.
Os pesquisadores testaram o TrialGPT em três conjuntos de dados públicos: SIGIR, TREC 2021 e TREC 2022, que incluíram 183 pacientes randomizados e mais de 75.000 anotações de ensaios. Os conjuntos de dados contêm uma ampla variedade de critérios de elegibilidade divididos em rótulos de inclusão e exclusão. O componente de recuperação usa GPT-4 para gerar palavras-chave sensíveis ao contexto a partir de anotações do paciente com mais de 90% de recuperação e 94% de redução do espaço de pesquisa. O mesmo componente realiza análises em nível de critério que fornecem alta precisão e são apoiadas por previsões de validade interpretáveis e localização de evidências. O método de escalonamento combina métodos de cluster baseados em linear e LLM de forma eficiente para dimensionar os testes apropriados enquanto descarta os inadequados e, portanto, pode ser usado em escala em aplicações do mundo real.
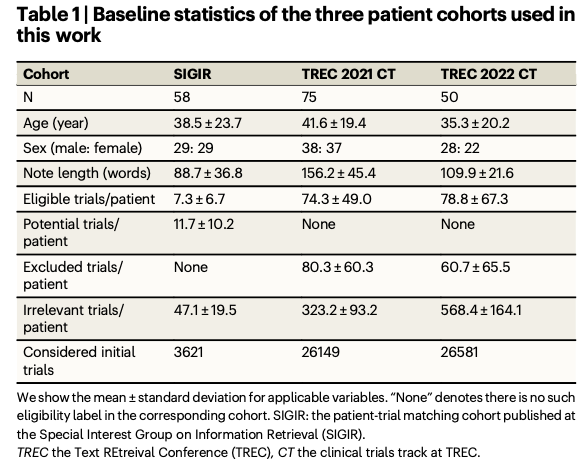
O modelo trialGPT teve um forte desempenho em todos os benchmarks relevantes, resolvendo problemas de recuperação e correspondência. O módulo de recuperação eliminou grandes lotes de teste enquanto ainda lembrava das opções corretas. O módulo de correspondência forneceu previsões em nível de critério com precisão equivalente à de especialistas humanos, além de descrições em linguagem natural e evidências em nível de frase real. Seu fator de classificação superou todos os outros métodos em termos de precisão e desempenho de classificação, excluindo a identificação e classificação de testes relevantes. A eficiência do fluxo de trabalho associado ao ensaio do paciente também foi melhorada pelo TrialGPT, o que levou a uma redução no tempo do ensaio em mais de 42 por cento, o que mostra o seu valor prático para o emprego em ensaios clínicos.
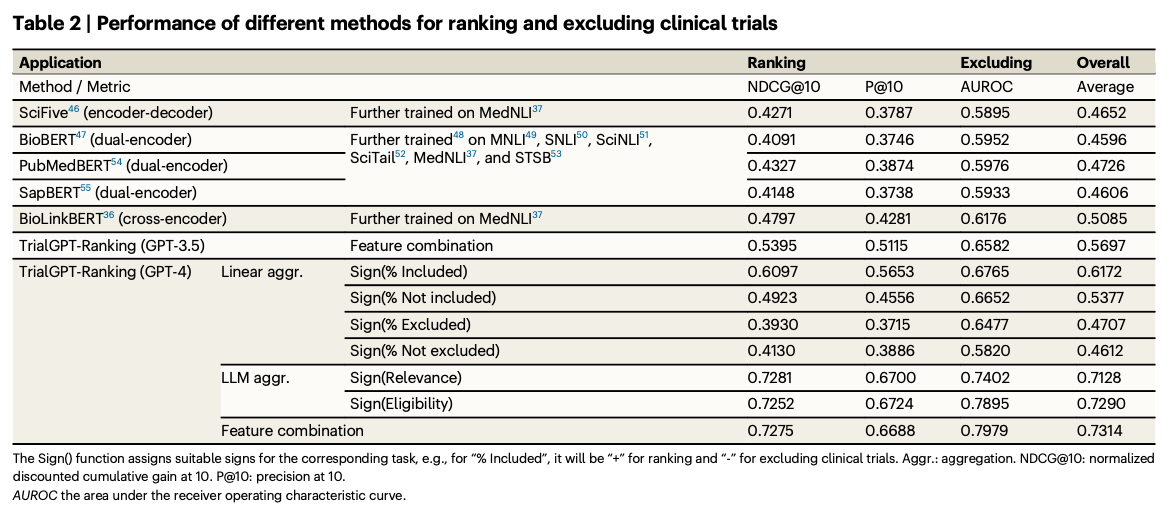
O TrialGPT apresenta uma solução robusta para os desafios de comparação de ensaios com pacientes: dimensionamento, precisão e transparência no uso de novos LLMs. Sua modularidade supera limitações importantes dos métodos convencionais, acelerando os processos de recrutamento de pacientes e simplificando a pesquisa clínica, ao mesmo tempo em que produz melhores resultados para os pacientes. Com melhor compreensão da linguagem combinada com resultados interpretáveis, o TrialGPT representa uma nova escala para avaliação e eficácia pessoal. O trabalho futuro pode incluir a integração de fontes de dados multimodais e a adaptação de LLMs de código aberto a várias aplicações de validação do mundo real.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Conferência Virtual GenAI gratuita com. Meta, Mistral, Salesforce, Harvey AI e mais. Junte-se a nós em 11 de dezembro para este evento de visualização gratuito para aprender o que é necessário para construir grande com pequenos modelos de pioneiros em IA como Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face e muito mais.
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
🐝🐝 Leia este relatório de pesquisa de IA da Kili Technology 'Avaliação de vulnerabilidade de um modelo de linguagem grande: uma análise comparativa de métodos de passagem vermelha'


