
Os humanos têm julgamentos naturais extraordinários e, se os modelos de visão computacional corresponderem a eles, o desempenho dos modelos poderá ser melhorado iterativamente. Vários atributos como estrutura da cena, posição do sujeito, posição da câmera, cor, perspectiva e semântica nos ajudam a ter uma imagem clara do mundo e das coisas dentro dele. Alinhar os modelos de visão com a percepção visual torna-os mais sensíveis a essas características e mais semelhantes aos humanos. Embora tenha sido descoberto que moldar modelos perceptivos ao longo das linhas de visão humana ajuda a atingir certos objectivos em situações específicas, tais como a criação de imagens, o seu efeito em papéis de propósito geral continua por confirmar. As suposições feitas na investigação até agora basearam-se numa combinação irracional de capacidades de percepção humana, modelos negativos e representações distorcidas. É discutível se o modelo é realmente relevante ou se os resultados dependem do desempenho pretendido e dos dados de treinamento. Além disso, a sensibilidade dos rótulos e o impacto tornam o quebra-cabeça mais difícil. Todos esses fatores dificultam a compreensão das habilidades cognitivas humanas em relação às tarefas visuais.
Pesquisadores do MIT e da UC Berkeley analisaram esta questão em profundidade. Seu artigo “Quando o alinhamento cognitivo beneficia a representação da percepção?” investiga como um modelo de visão alinhada ao humano funciona em várias tarefas de visão posteriores. Os autores desenvolveram modelos ViT de última geração para julgamentos de similaridade humana de trigêmeos de imagens e os analisaram em benchmarks de visão padrão. Eles apresentam a ideia de um segundo estágio de treinamento, que combina representações de recursos de grandes modelos de percepção e julgamento humano antes de aplicá-los em tarefas posteriores.
Para entender isso melhor, vamos primeiro discutir as três imagens mencionadas acima. Os autores usaram o conhecido conjunto de dados sintéticos NIGHTS com imagens triplas com decisões de seleção de similaridade forçada, onde as pessoas escolheram as duas imagens com maior semelhança com a imagem original. Eles desenvolveram uma função objetivo de alinhamento de patch para capturar as representações espaciais presentes nos tokens de patch e traduzir as características físicas das anotações globais; em vez de combinar as perdas entre os tokens CLS globais do Vision Transformer, eles focaram o CLS e integraram a incorporação de patches ViT para esse fim, a fim de melhorar as características do patch local em conjunto com o rótulo de imagem global. Depois disso, uma visão diferente da modernidade. Modelos de transformadores, como DINO, CLIP, etc., são desenvolvidos a partir dos dados acima usando Low-Rank Adaptation (LoRA). Os autores também combinaram imagens sintéticas em trigêmeos com SynCLR para calcular o desempenho delta.
Esses modelos são mais eficazes em tarefas de visão do que os Vision Transformers básicos. Em tarefas de previsão densas, os modelos alinhados ao homem superaram os modelos básicos em mais de 75% nos casos em que há classificação semântica e estimativa de profundidade. Avançando no campo da visão generativa e LLMs, a tarefa Advanced Generation Retrieval foi testada humanizando o modelo de linguagem de visão. Os resultados também favoreceram as informações retornadas pelos modelos alinhados aos humanos, pois melhoraram a precisão da classificação entre os domínios. Além disso, na tarefa de contar objetos, esses modelos modificados tiveram desempenho melhor que a linha de base em mais de 95% dos casos. A mesma tendência continua no exemplo da recuperação. Esses modelos falharam nas tarefas de classificação devido ao seu alto nível de compreensão semântica.
Os autores consideram também que os dados de treino têm um papel mais importante que o método de treino. Para tanto, foram considerados múltiplos conjuntos de dados com trigêmeos de imagens. Os resultados foram surpreendentes, com o conjunto de dados NIGHTS proporcionando o maior impacto, enquanto o restante não foi afetado. Os recursos cognitivos capturados em NIGHTS desempenham um papel importante nisso com seus recursos como estilo, forma, cor e contagem de objetos. Outros falharam devido à incapacidade de captar os aspectos cognitivos necessários no nível intermediário.
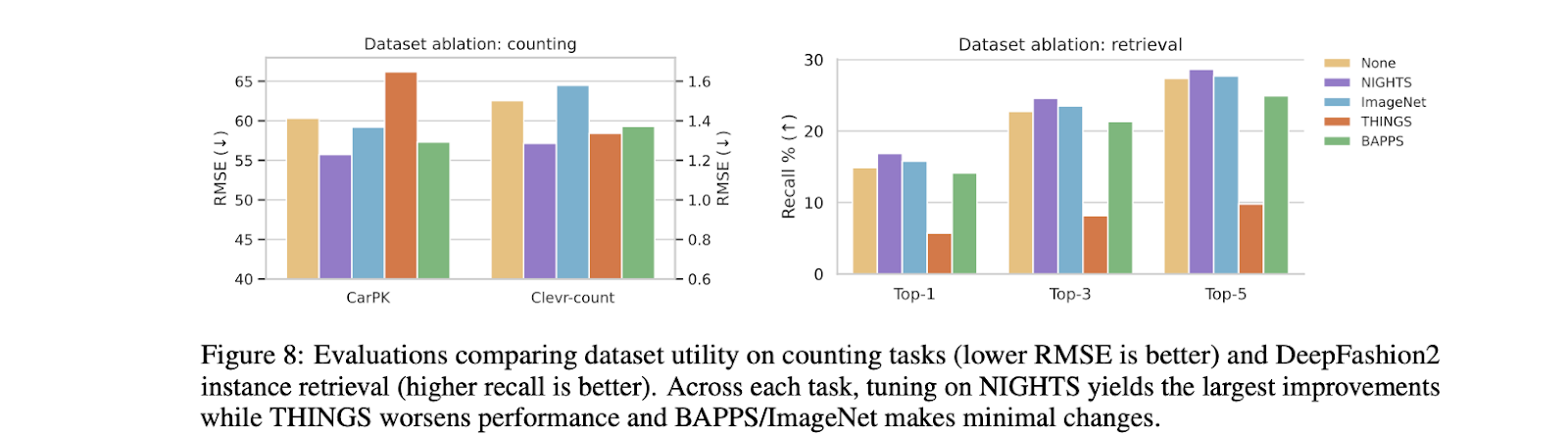
No geral, os modelos de visão alinhada ao humano tiveram um bom desempenho na maioria dos casos. No entanto, esses modelos são propensos à superdispersão e ao viés. Portanto, se for verificada a qualidade e a diversidade das anotações humanas, a inteligência visual pode ser considerada um degrau acima.
Confira Artigo, GitHub e Projeto. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] Melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (avançado)
Adeeba Alam Ansari está atualmente cursando um diploma duplo no Instituto Indiano de Tecnologia (IIT) Kharagpur, cursando B.Tech em Engenharia Industrial e M.Tech em Engenharia Financeira. Com profundo interesse em aprendizado de máquina e inteligência artificial, ele é um leitor ávido e uma pessoa curiosa. Adeeba acredita firmemente no poder da tecnologia para capacitar a sociedade e promover o bem-estar através de soluções inovadoras impulsionadas pela empatia e uma compreensão profunda dos desafios do mundo real.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


