: uma nova estrutura bidirecional de tokenização de fala aprimorada por Mamba para detecção eficiente de tempo de fala")
A detecção de termos falados (STD) é uma área importante no processamento de fala, permitindo a identificação de frases ou termos específicos em grandes arquivos de áudio. Essa tecnologia é amplamente utilizada em pesquisas baseadas em voz, serviços de transcrição e sistemas de indexação multimídia. Ao facilitar a recuperação de conteúdo falado, o STD desempenha um papel importante na melhoria da acessibilidade e usabilidade dos dados de áudio, especialmente em domínios como podcasts, palestras e meios de transmissão.
Um grande desafio na recuperação de palavras faladas é o tratamento eficaz de palavras fora do vocabulário (OOV) e as demandas computacionais dos sistemas existentes. Os métodos tradicionais geralmente dependem de sistemas de reconhecimento automático de fala (ASR), que consomem muitos recursos e são propensos a erros, especialmente para segmentos de áudio de curta duração ou sob condições acústicas dinâmicas. Além disso, esses métodos requerem auxílio na segmentação precisa da fala contínua, dificultando a identificação de palavras específicas fora do contexto.
Os métodos STD existentes incluem técnicas baseadas em ASR que usam redes de fonemas ou grafemas, bem como distorção dinâmica de tempo (DTW) e incorporação fonológica para comparação direta de sons. Embora esses métodos tenham seus méritos, eles são limitados pela diversidade de plataformas, pela ineficiência do computador e pelos desafios no processamento de grandes conjuntos de dados. As ferramentas atuais também precisam de ajuda para se adaptarem a diferentes conjuntos de dados, especialmente termos que não estão disponíveis durante o treinamento.
Pesquisadores do Instituto Indiano de Tecnologia de Kanpur e da imec – Universidade de Ghent introduziram uma nova estrutura de token de fala chamada BEST-STD. Essa abordagem combina a fala em tokens semânticos abstratos e discretos, permitindo a recuperação eficiente por algoritmos baseados em texto. Ao incorporar um codificador Mamba bidirecional, a estrutura gera sequências de tokens altamente consistentes para diferentes expressões do mesmo termo. Esta abordagem elimina a necessidade de classificação explícita e lida com termos OOV de forma mais eficiente do que os sistemas anteriores.
O sistema BEST-STD usa um codificador Mamba duplo, que processa a entrada de áudio nas direções direta e reversa para capturar dependências de longo alcance. Cada camada codificadora projeta os dados de áudio em uma incorporação de alta dimensão, que é dividida em uma sequência de tokens por um quantizador vetorial. O modelo usa um método de aprendizagem auto-supervisionado, que usa tempo dinâmico para combinar expressões do mesmo termo e criar pares de âncoras fortes no nível do quadro. O programa utiliza um índice invertido para armazenar a sequência de tokens, o que permite uma recuperação eficiente comparando a similaridade dos tokens. Durante o treinamento, o sistema gera representações de tokens consistentes, garantindo flexibilidade do alto-falante e diversidade acústica.
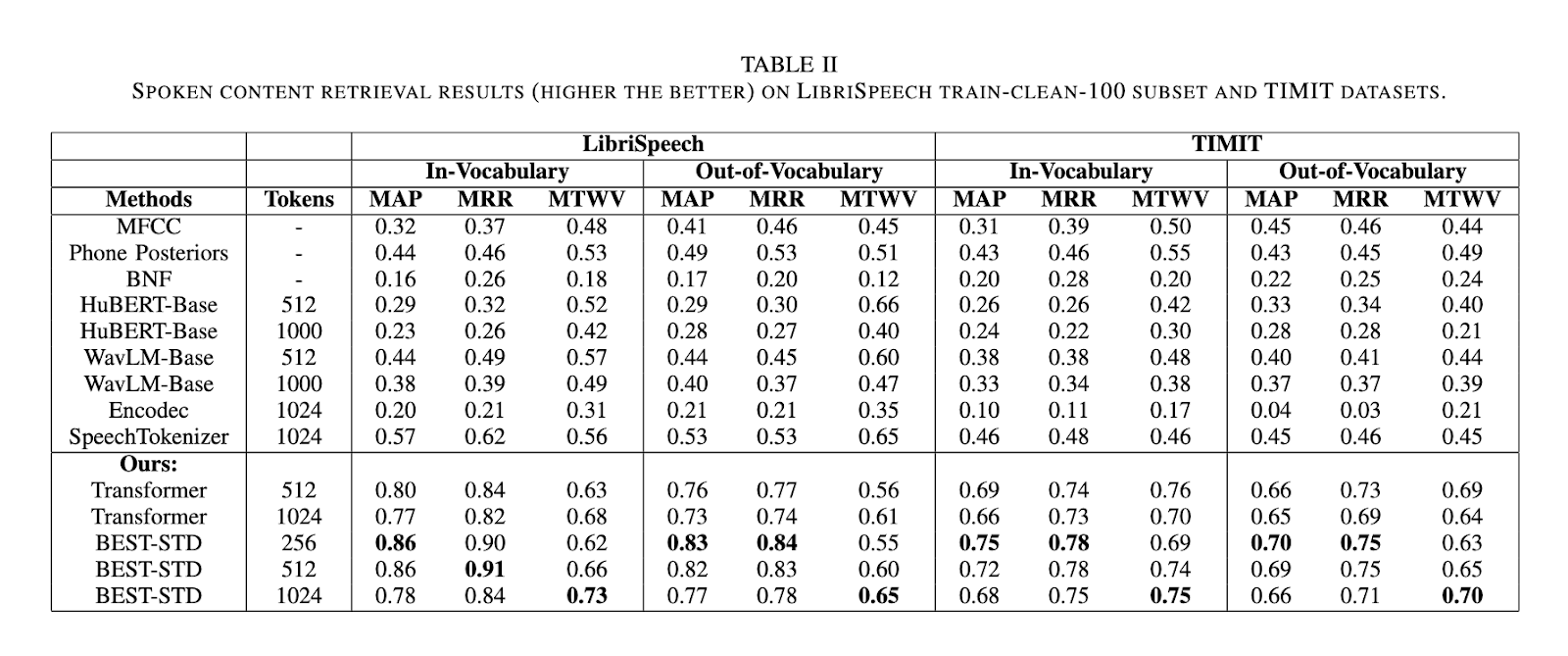
A estrutura BEST-STD mostrou desempenho superior em testes realizados nos conjuntos de dados LibriSpeech e TIMIT. Comparado com métodos tradicionais de STD e modelos de token de última geração, como HuBERT, WavLM e SpeechTokenizer, o BEST-STD alcançou as pontuações mais altas do tipo Jaccard para correspondência de token, e as pontuações de unigramas de 0,84 e pontuações de bigrama de 0,78. O sistema superou as tarefas básicas de recuperação de conteúdo de fala em termos de precisão média (MAP) e taxa média de repetição (MRR). Para palavras e vocabulário intermediários, o BEST-STD alcançou pontuações MAP de 0,86 e pontuações MRR de 0,91 no conjunto de dados LibriSpeech, enquanto para termos OOV, as pontuações atingiram 0,84 e 0,90, respectivamente. Estes resultados enfatizam a capacidade do sistema de generalizar todos os tipos de termos e conjuntos de dados.
Notavelmente, a estrutura BEST-STD também se destacou em velocidade e eficiência de recuperação, beneficiando-se do índice reverso da sequência de tokens. Este método reduz a dependência de correspondência baseada em DTW com uso intensivo de computação, tornando-o escalonável para grandes conjuntos de dados. O codificador bidirecional Mamba, em particular, provou ser mais eficiente do que as arquiteturas baseadas em transformadores devido à sua capacidade de modelar informações temporais refinadas que são importantes para a detecção de termos falados.
Concluindo, a introdução do BEST-STD marca um grande avanço no reconhecimento de palavras faladas. Ao abordar as limitações dos métodos tradicionais, este método fornece uma solução robusta e eficiente para tarefas de recuperação de áudio. O uso de tokens independentes de locutor e do codificador bidirecional do Mamba não apenas melhora o desempenho, mas também garante flexibilidade em diferentes conjuntos de dados. Esta estrutura mostra-se promissora para aplicações do mundo real, abrindo caminho para melhor acessibilidade e capacidade de pesquisa no processamento de áudio.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
🎙️ 🚨 'Avaliação de vulnerabilidade de um grande modelo de linguagem: uma análise comparativa dos métodos da Cruz Vermelha' Leia o relatório completo (Promovido)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)


