
Os modelos de distribuição de probabilidade são importantes para gerar estruturas de dados complexas, como imagens e vídeos. Esses modelos transformam ruído aleatório em dados estruturados, alcançando alto realismo e usabilidade em diversos domínios. O modelo funciona em dois estágios: um estágio avançado que corrompe gradualmente os dados com ruído e um estágio reverso que reconstrói sistematicamente os dados combinados. Apesar dos resultados promissores, esses modelos muitas vezes exigem muitas etapas de remoção de ruído e enfrentam ineficiências na medição da qualidade da amostra com velocidade computacional, o que motiva os pesquisadores a buscar formas de simplificar esses processos.
Um grande problema com os modelos de distribuição existentes é a necessidade de produção eficiente de amostras de alta qualidade. Essa limitação vem principalmente do grande número de etapas necessárias no processo reversível e das configurações de covariância que são fixas ou aprendidas de forma diferente, que não melhoram a qualidade da saída o suficiente em comparação com o tempo e os recursos computacionais. A redução dos erros de previsão de covariância pode acelerar o processo de amostragem, mantendo a integridade da saída. Para resolver isso, os pesquisadores procuram melhorar essas estimativas de covariância para obter um modelo mais eficiente e preciso.
Métodos comuns, como Modelos Probabilísticos de Difusão e Denoising (DDPM), capturam ruído usando programações de ruído predeterminadas ou aprendem covariância usando parâmetros dinâmicos baixos. Recentemente, modelos avançados evoluíram para aprender diretamente a covariância para melhorar a qualidade da saída. No entanto, esses métodos apresentam cargas computacionais, especialmente em aplicações de grandes dimensões, onde os dados requerem cálculos intensivos. Tais limitações impedem o uso eficaz de modelos em todos os domínios que exigem alta resolução ou integração complexa de dados.
Uma equipe de pesquisadores do Imperial College London, da University College London e da Universidade de Cambridge apresentou um novo método chamado Optimal Covariance Matching (OCM). Esta abordagem redefine a medida de covariância derivando diretamente a covariância diagonal da função de pontuação do modelo, eliminando a necessidade de estimativa baseada em dados. Ao regredir analiticamente a covariância relevante, o OCM reduz erros de previsão e melhora a qualidade das amostras, ajudando a superar limitações associadas a matrizes de covariância fixas ou estudadas diferencialmente. OCM representa um passo importante ao simplificar o processo de medição de covariância sem comprometer a precisão.
O método OCM fornece uma maneira sistemática de estimar a covariância treinando uma rede neural para prever a diagonal Hessiana, o que permite uma estimativa precisa da covariância com requisitos computacionais mínimos. Os modelos tradicionais geralmente exigem o cálculo da matriz Hessiana, que não é matematicamente perfeita para aplicações de alta dimensão, como grandes conjuntos de dados de imagens ou vídeos. OCM ignora esses cálculos intensivos, reduzindo os requisitos de armazenamento e o tempo de computação. O uso de uma função baseada em pontuação para estimar a covariância melhora a precisão da previsão, ao mesmo tempo que mantém baixas as demandas computacionais, garantindo desempenho prático para aplicações de alta dimensão. Esta abordagem baseada em pontuação para OCM não apenas torna a previsão de covariância mais precisa, mas também reduz o tempo total necessário para o processo de amostragem.

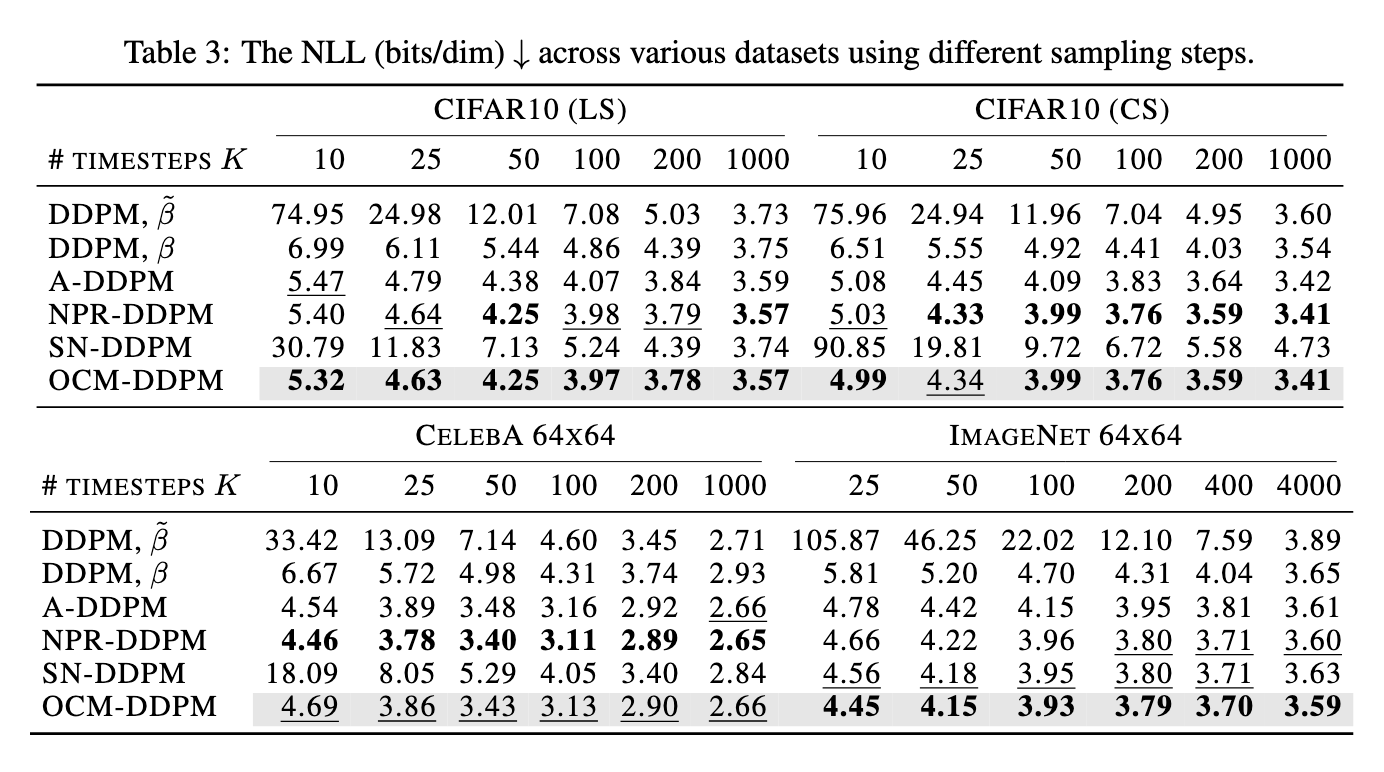
O teste de desempenho mostra uma melhoria significativa do OCM que proporcionou a qualidade e eficiência das amostras produzidas. Por exemplo, quando testado no conjunto de dados CIFAR10, o OCM obteve uma pontuação Frechet Inception Distance (FID) de 38,88 para cinco etapas de classificação de ruído, superando o DDPM convencional, que registrou uma pontuação FID de 58,28. Com dez etapas de remoção de ruído, o método OCM foi ainda melhor, alcançando pontuação de 21,60 contra 34,76 do DDPM. Estes resultados mostram que o OCM melhora a qualidade da amostra e reduz a carga computacional, exigindo menos etapas para obter resultados comparáveis ou melhores. O estudo também revelou que a avaliação potencial do OCM melhorou significativamente. Usando menos de 20 etapas, o OCM alcançou um log de verossimilhança negativo (NLL) de 4,43, que supera os DDPMs convencionais, que normalmente exigem 20 ou mais etapas para atingir um NLL de 6,06. Esta eficiência melhorada sugere que a estimativa OCM baseada em pontuações de covariância pode ser uma alternativa eficiente aos modelos de distribuição Markovianos e não Markovianos, reduzindo tempo e recursos computacionais sem comprometer a qualidade.
Este estudo destaca um método inovador para otimizar a estimativa de covariância para fornecer geração de dados de alta qualidade com etapas reduzidas e maior eficiência. Ao aplicar uma abordagem baseada em pontos ao OCM, a equipe de pesquisa fornece uma solução equilibrada para os desafios da modelagem de segmentação, combinando eficiência computacional com alta qualidade de resultados. Este desenvolvimento poderá ter um impacto significativo em aplicações onde a geração rápida e de alta qualidade de dados é crítica.
Confira Papel e GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Upcoming Live Webinar- Oct 29, 2024] A melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (atualizado)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


: uma família de instruções de modelos abertos preparadas para Darija (árabe marroquino)")