
Modelos linguísticos de vídeo em larga escala (VLLMs) surgiram como ferramentas revolucionárias para análise de conteúdo de vídeo. Esses modelos se destacam no raciocínio multimodal, combinando dados visuais e textuais para interpretar e responder a situações complexas de vídeo. Suas aplicações variam desde responder perguntas sobre vídeos até resumir e descrever vídeos. Com a sua capacidade de processar entradas em grande escala e fornecer resultados detalhados, são essenciais para tarefas que requerem uma compreensão avançada da dinâmica visual.
Um desafio principal nos VLLMs é gerenciar o custo computacional do processamento de grandes dados visuais a partir da entrada de vídeo. Os vídeos carregam naturalmente alta redundância, pois os quadros geralmente capturam informações sobrepostas. Esses quadros geram milhares de tokens quando processados, resultando em uso significativo de memória e velocidades de processamento lentas. Abordar esta questão é fundamental para fazer com que os VLLMs funcionem bem sem comprometer a sua capacidade de realizar tarefas cognitivas complexas.
As abordagens atuais tentaram reduzir a complexidade computacional introduzindo técnicas de remoção de tokens e projetando modelos leves. Por exemplo, métodos de poda como FastV propõem pontos de atenção para reduzir tokens valiosos. No entanto, esses métodos geralmente dependem de técnicas de remoção única, que podem remover inadvertidamente tokens críticos necessários para manter a alta precisão. Além disso, as técnicas de redução de parâmetros muitas vezes comprometem o poder preditivo dos modelos, limitando a sua utilização em tarefas complexas.
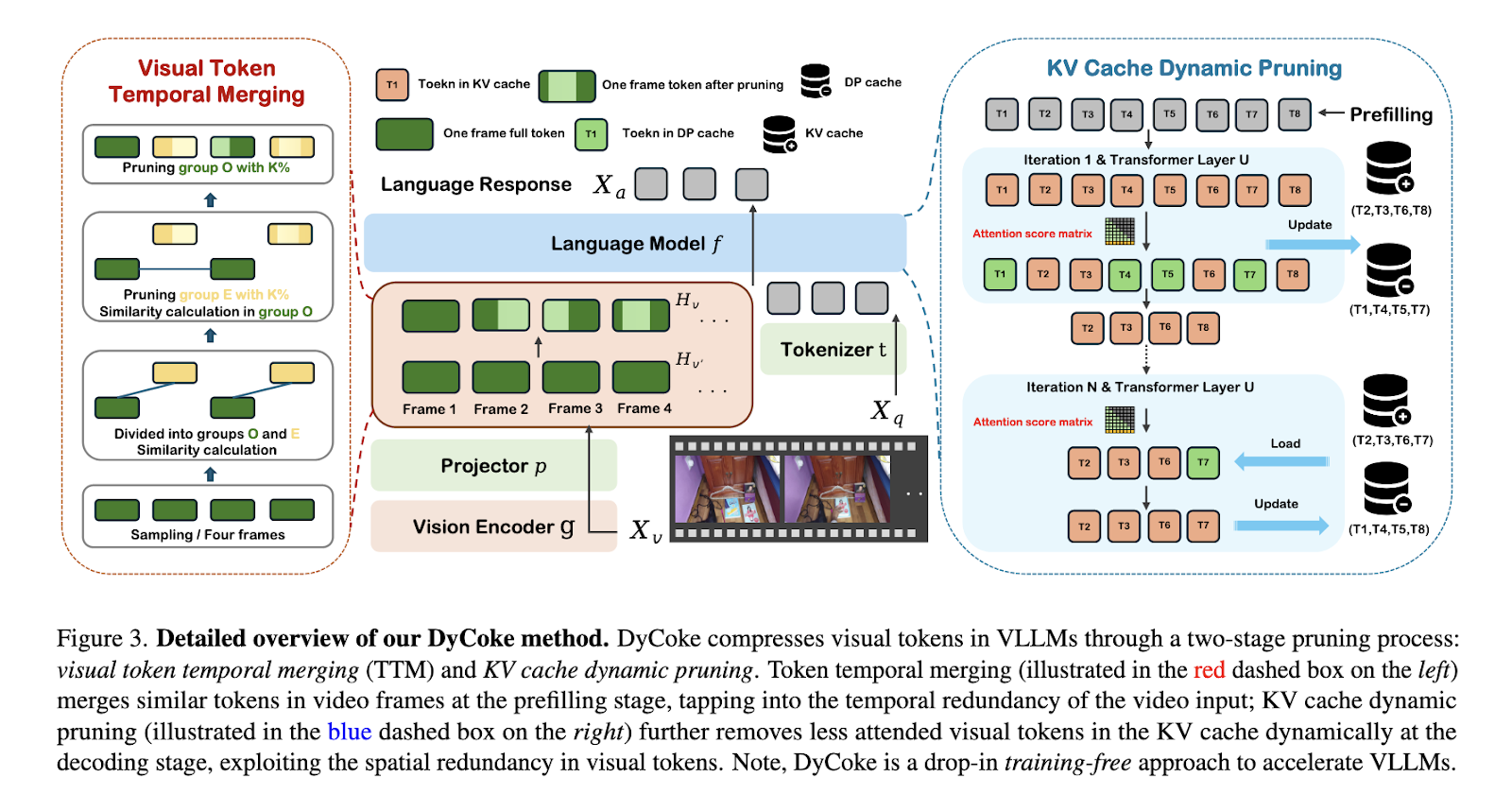
Pesquisadores da Westlake University, Salesforce AI Research, Apple AI/ML e Rice University apresentaram o DyCoke, um novo método projetado para compactar tokens com grandes modelos de linguagem de vídeo. DyCoke adota uma abordagem livre de treinamento, diferenciando-se por abordar a redundância temporal e espacial da entrada de vídeo. Ao utilizar técnicas de poda dinâmicas e adaptativas, o método maximiza a eficiência computacional enquanto mantém o alto desempenho. Esta inovação visa tornar os VLLMs escaláveis em aplicações do mundo real sem necessidade de otimização ou treinamento adicional.
DyCoke usa um processo de compactação de token em dois estágios. O clustering de tokens temporais combina tokens inválidos de todos os quadros de vídeo adjacentes na primeira fase. Este módulo combina frames em janelas de amostra e identifica informações sobrepostas, combinando tokens para armazenar tokens únicos e representativos. Por exemplo, a repetição de aparecer num fundo estático ou de ações repetidas é efetivamente reduzida. Durante a fase de gravação, a segunda fase aplica um método de remoção dinâmica ao cache de valor-chave (KV). Os tokens são avaliados e armazenados dinamicamente com base em sua pontuação de atenção. Esta etapa garante que apenas os tokens mais importantes sejam deixados, enquanto os tokens não importantes são armazenados em um cache de remoção dinâmico para reutilização. Ao refinar iterativamente o cache KV em cada etapa de gravação, o DyCoke combina a carga de computação com o valor real dos tokens.
Os resultados da DyCoke destacam sua eficiência e durabilidade. Em benchmarks como o MVBench, que inclui 20 tarefas complexas, como reconhecimento de ação e interação de objetos, o DyCoke alcançou uma aceleração de inferência de até 1,5x e uma redução de 1,4x no uso de memória em comparação com modelos de linha de base. Especificamente, o método reduziu o número de tokens armazenados para até 14,25% em algumas configurações, com degradação mínima de desempenho. No conjunto de dados VideoMME, DyCoke tem um desempenho muito bom no processamento de longas sequências de vídeo, mostrando alta eficiência enquanto mantém ou excede a precisão dos modelos não compactados. Por exemplo, com uma taxa de poda de 0,5, conseguiu uma redução de latência de até 47%. Ele superou métodos de última geração, como FastV, na manutenção da precisão em tarefas como raciocínio episódico e navegação egocêntrica.
A oferta da DyCoke vai além de velocidade e eficiência de memória. Simplifique as tarefas de imagem de vídeo reduzindo a duplicação temporal e espacial da entrada visual, equilibrando efetivamente o desempenho e a utilização de recursos. Ao contrário dos métodos anteriores que exigem treinamento extensivo, o DyCoke funciona como uma solução plug-and-play, tornando-o acessível à maioria dos modelos de linguagem de vídeo. Sua capacidade de alterar dinamicamente o armazenamento de tokens garante que informações importantes sejam preservadas, mesmo em situações exigentes.

No geral, DyCoke representa um importante passo no desenvolvimento de VLLMs. Enfrentar os desafios computacionais inerentes ao processamento de vídeo permite que estes modelos funcionem de forma mais eficiente sem comprometer as suas capacidades de raciocínio. Esta inovação avança na compreensão de vídeo de alto nível e abre novas possibilidades para o uso de VLLMs em situações do mundo real onde os recursos computacionais são frequentemente limitados.
Confira Papel e GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
🎙️ 🚨 'Avaliação de vulnerabilidade de um grande modelo de linguagem: uma análise comparativa dos métodos da Cruz Vermelha' Leia o relatório completo (Promovido)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)
: um novo método de IA que remove seletivamente logs infiéis para melhorar a precisão da resposta em modelos de percepção de linguagem em grande escala")

