
Testar o desempenho no mundo real de modelos linguísticos de grande escala (LLMs) é essencial para orientar a sua integração em casos de uso práticos. Um desafio importante no teste de LLMs é a tendência de usar conjuntos de dados estáticos durante os testes, levando a métricas de desempenho infladas. Estruturas de testes rigorosas muitas vezes não conseguem determinar a capacidade do modelo de se adaptar ao feedback ou de fornecer explicações, resultando em testes que não refletem as condições do mundo real. Esta lacuna nos métodos de teste exige uma estrutura flexível e iterativa para testar modelos sob condições em evolução.
Tradicionalmente, métodos de avaliação como “LLM-as-a-Judge” dependem de conjuntos de dados estáticos e benchmarks estáticos para medir o desempenho. Embora estes métodos tendam a correlacionar-se melhor com os julgamentos das pessoas do que os métodos de correspondência de palavras, eles sofrem de preconceitos, incluindo preferências de palavras e invariância de pontuações entre repetições. E não conseguem testar os modelos em diversas interações, onde a adaptação e o desenvolvimento iterativo são essenciais. Como resultado, estas abordagens tradicionais lutam para obter uma compreensão abrangente das competências de LLM.
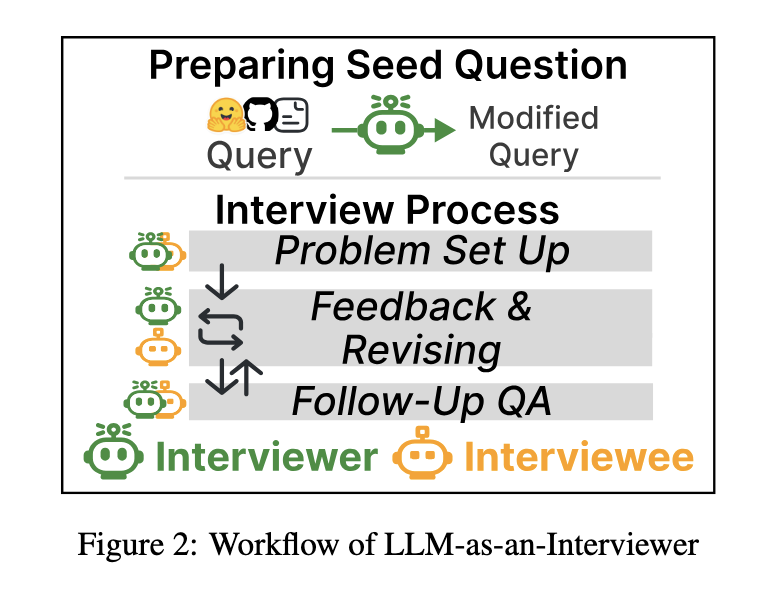
Pesquisadores da KAIST, da Universidade de Stanford, da Universidade Carnegie Mellon e da Contextual AI lançaram o LLM-AS-AN-INTERVIEWER, uma nova estrutura para avaliar LLMs. Esta abordagem simula processos de entrevistas humanas, manipulando conjuntos de dados para gerar perguntas específicas e fornecer feedback sobre respostas modeladas. O questionador do LLM ajusta suas perguntas com base no desempenho do modelo testado, incentivando uma avaliação detalhada e sutil de suas habilidades. Ao contrário dos métodos estáticos, esta estrutura captura comportamentos como o refinamento das respostas e a capacidade de lidar eficazmente com questões adicionais.
A estrutura opera em três estágios: definição do problema, feedback e revisão e perguntas de acompanhamento. Inicialmente, o entrevistador cria questões diversas e desafiadoras, preparando conjuntos de dados de referência. Durante a discussão, fornece feedback detalhado sobre as respostas do modelo e coloca questões de acompanhamento que exploram aspectos adicionais do seu pensamento ou conhecimento. Este processo iterativo culmina na produção de um “Relatório de Entrevista”, que inclui métricas de desempenho, análise de erros e um resumo abrangente dos pontos fortes e limitações do modelo. Este relatório fornece possíveis insights sobre a aplicação e adaptação do modelo no mundo real.
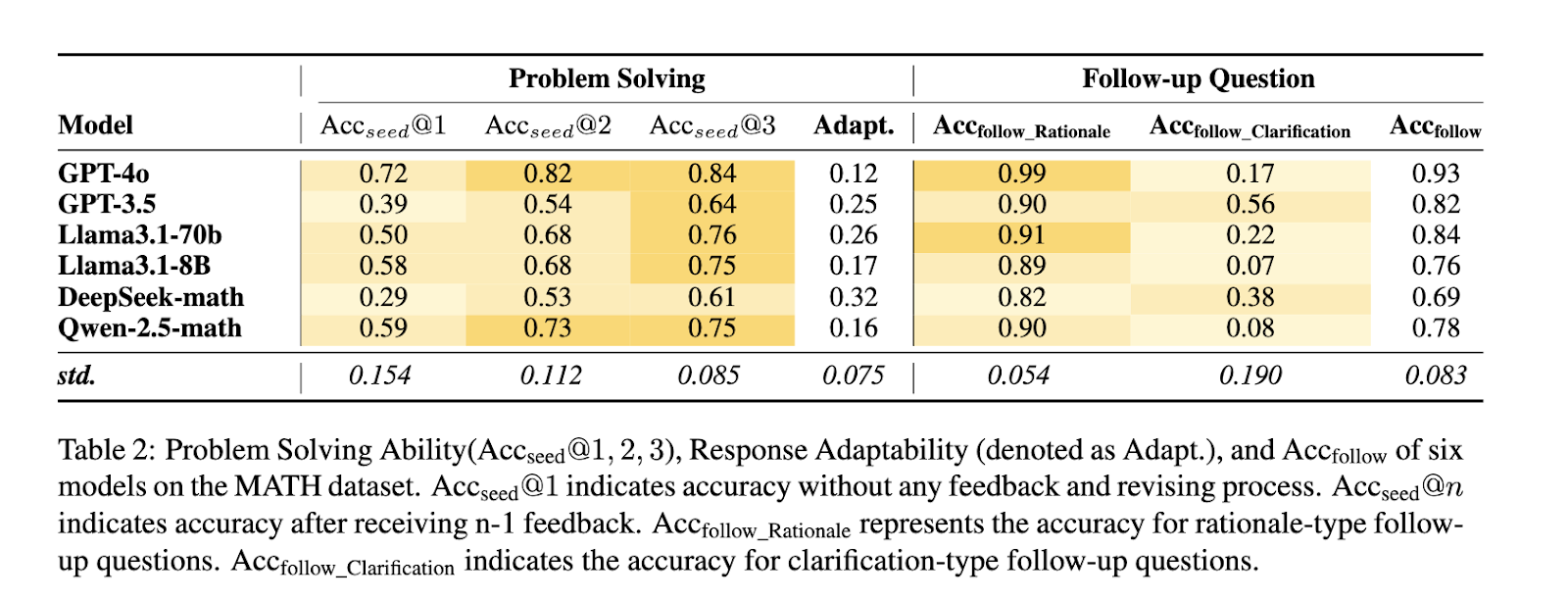
Experimentos usando conjuntos de dados MATH e DepthQA demonstram a eficácia da estrutura. Em MATH, que se concentra no raciocínio aritmético, modelos como o GPT-4o alcançaram uma precisão inicial de resolução de problemas de 72%. Essa precisão aumentou para 84% com feedback e interação iterativos, destacando a capacidade da estrutura de melhorar o desempenho do modelo. Da mesma forma, o teste DepthQA, que enfatiza perguntas abertas, revela a eficácia das perguntas de acompanhamento na revelação de lacunas de conhecimento do modelo e na melhoria das suas respostas. Por exemplo, a métrica de adaptação GPT-3.5 mostrou uma melhoria acentuada de 25% após interações repetidas, demonstrando a capacidade do modelo de refinar as respostas com base no feedback.
A estrutura também aborda o viés crítico tão comum nas avaliações de LLM. O viés de verbosidade, a tendência de favorecer respostas longas, diminui à medida que a interação progride, com uma diminuição significativa na correlação entre o comprimento da resposta e as pontuações. Além disso, o viés de autoaperfeiçoamento, em que os modelos favorecem suas respostas durante os testes, é reduzido pela interação de variáveis e pela comparação de pontuações. Esse ajuste garante resultados de teste consistentes e confiáveis em diversas execuções, com o desvio padrão diminuindo à medida que a frequência de resposta aumenta.
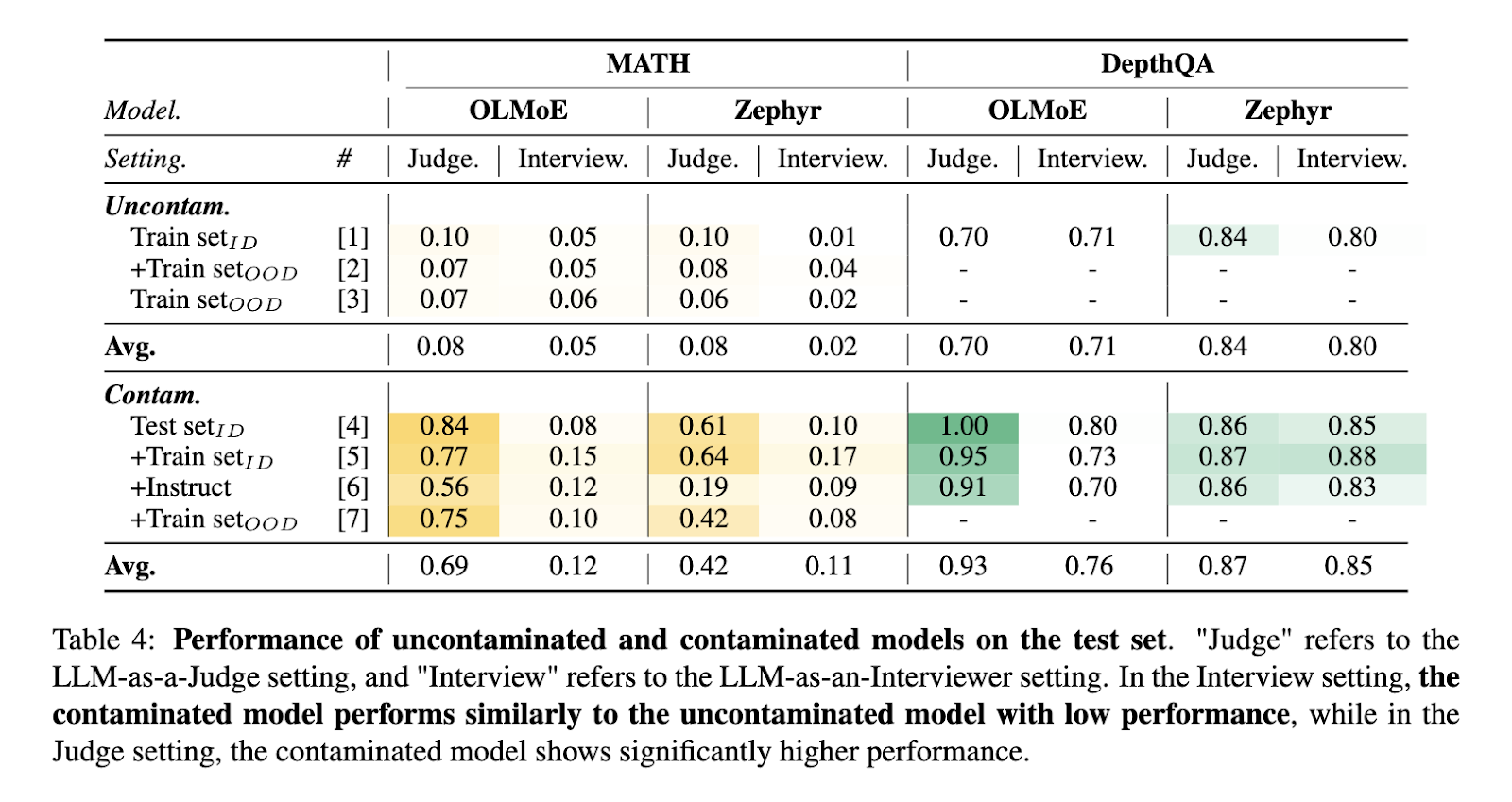
LLM-AS-AN-ENTREVIEWER fornece uma solução robusta para corrupção de dados, principais preocupações de treinamento e avaliação do LLM. A estrutura reduz o risco de contaminação, alterando dinamicamente as questões de referência e introduzindo novos acompanhamentos. Por exemplo, os modelos treinados em conjuntos de dados contaminados mostraram o desempenho mais elevado em ambientes estáticos, mas estreitamente alinhados com modelos não contaminados quando testados empiricamente. Este resultado enfatiza a capacidade da estrutura de distinguir entre capacidades reais do modelo e artefatos de sobreposição de dados de treinamento.
Em conclusão, o LLM-AS-AN-ENTREVIEWER representa uma mudança de paradigma na avaliação de modelos macrolinguísticos. A simulação de interações semelhantes às humanas e a adaptação dinâmica às respostas modeladas fornecem uma compreensão mais precisa e diferenciada de suas habilidades. A natureza iterativa da estrutura destaca áreas para melhoria e permite que os modelos demonstrem a sua flexibilidade e desempenho no mundo real. Com o seu design robusto e análise abrangente, esta estrutura tem o potencial de estabelecer um novo padrão para testes LLM, garantindo que modelos futuros sejam testados com maior precisão e validade.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 PRÓXIMO WEBINAR GRATUITO DE IA (15 DE JANEIRO DE 2025): Aumente a precisão do LLM com dados artificiais e inteligência experimental–Participe deste webinar para obter insights práticos sobre como melhorar o desempenho e a precisão do modelo LLM e, ao mesmo tempo, proteger a privacidade dos dados.
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
🧵🧵 Siga-nos no X (Twitter) para pesquisas gerais sobre IA e atualizações de desenvolvimento aqui…


