
A navegação por visão e linguagem (VLN) combina a percepção visual com a compreensão da linguagem natural para guiar os agentes através de ambientes 3D. O objetivo é permitir que os agentes sigam instruções semelhantes às humanas e naveguem em ambientes complexos com eficiência. Tais desenvolvimentos têm potencial em robótica, realidade virtual e tecnologia de assistente inteligente, onde instruções de linguagem orientam as interações com espaços físicos.
Um problema chave na pesquisa VLN é a falta de conjuntos de dados de anotação de alta qualidade que combinem trajetórias de navegação com comandos precisos de linguagem natural. A anotação desses conjuntos de dados requer recursos, conhecimento e esforço significativos, tornando o processo caro e demorado. Além disso, estas anotações muitas vezes não conseguem fornecer a riqueza linguística e a fiabilidade necessárias para generalizar modelos em diferentes ambientes, limitando a sua aplicabilidade em aplicações do mundo real.
As soluções existentes dependem da geração artificial de dados e de melhorias naturais. Os dados sintéticos são gerados usando modelos de trajetória até a instrução, enquanto os atores classificam os locais. No entanto, estes métodos muitas vezes têm de melhorar a qualidade, produzindo dados inconsistentes entre a língua e as trajetórias de navegação. Essa inconsistência leva a um desempenho menos eficaz do agente. O problema também é agravado por métricas que não avaliam adequadamente o alinhamento semântico e a direcionalidade com as trajetórias correspondentes, desafiando assim o controle de qualidade.
Pesquisadores do Laboratório de IA de Xangai, UNC Chapel Hill, Adobe Research e Universidade de Nanjing propuseram o Self-Refining Data Flywheel (SRDF), um sistema projetado para melhorar iterativamente conjuntos de dados e modelos por meio da interação entre o gerador de orientação e o navegador. Essa abordagem automatizada elimina a necessidade de anotação humana. Começando com um pequeno conjunto de dados de anotações humanas de alta qualidade, o sistema SRDF gera instruções sintéticas e as utiliza para treinar um navegador básico. O Navigator então avalia a confiabilidade dessas instruções, filtrando dados de baixa qualidade para treinar um gerador melhor para a próxima iteração. Essa melhoria iterativa garante melhoria contínua na qualidade dos dados e no desempenho do modelo.
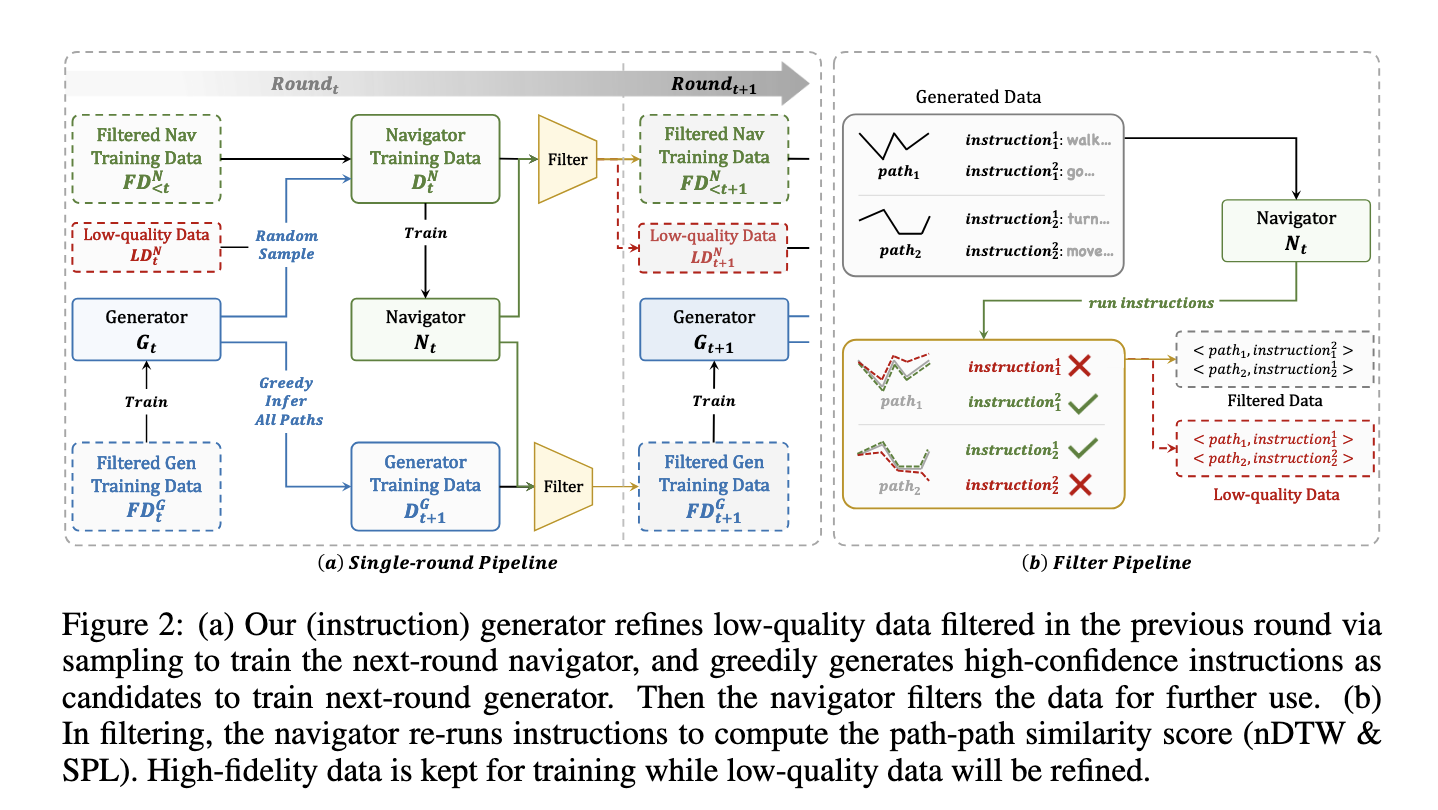
O sistema SRDF consiste em dois componentes principais: o gerador de orientação e o navegador. O gerador cria instruções de navegação artificiais a partir da rota usando modelos avançados de linguagem multimodal. O navegador, por sua vez, avalia essas instruções medindo a precisão com que elas conseguem seguir os caminhos gerados. Dados de alta qualidade são identificados com base em métricas robustas de confiabilidade, como comprimento de caminho medido (SPL) e padrão Dynamic Time Warping (nDTW). Dados de má qualidade são reproduzidos ou excluídos, garantindo que apenas dados confiáveis e altamente alinhados sejam usados para treinamento. Em três iterações, o sistema filtra o conjunto de dados, eventualmente contendo 20 milhões de pares de sequências de alta fidelidade, cobrindo 860 locais diferentes.
O sistema SRDF mostrou melhorias excepcionais de desempenho em diversas métricas e benchmarks. No conjunto de dados Room-to-Room (R2R), a métrica SPL do navegador aumentou de 70% para 78% sem precedentes, superando o benchmark humano de 76%. Isto marca a primeira vez que um agente VLN teve um desempenho admirável em termos de precisão de navegação em nível humano. O gerador de instruções também obteve resultados impressionantes, pois a pontuação do SPICE aumentou de 23,5 para 26,2, superando todos os métodos de geração de instruções para navegação por linguagem e visão. Além disso, os dados produzidos pelo SRDF promoveram alta generalização em todas as operações de downlink, incluindo navegação de longo alcance (R4R) e navegação baseada em conversação (CVDN), alcançando desempenho moderno para todos os conjuntos de dados testados.
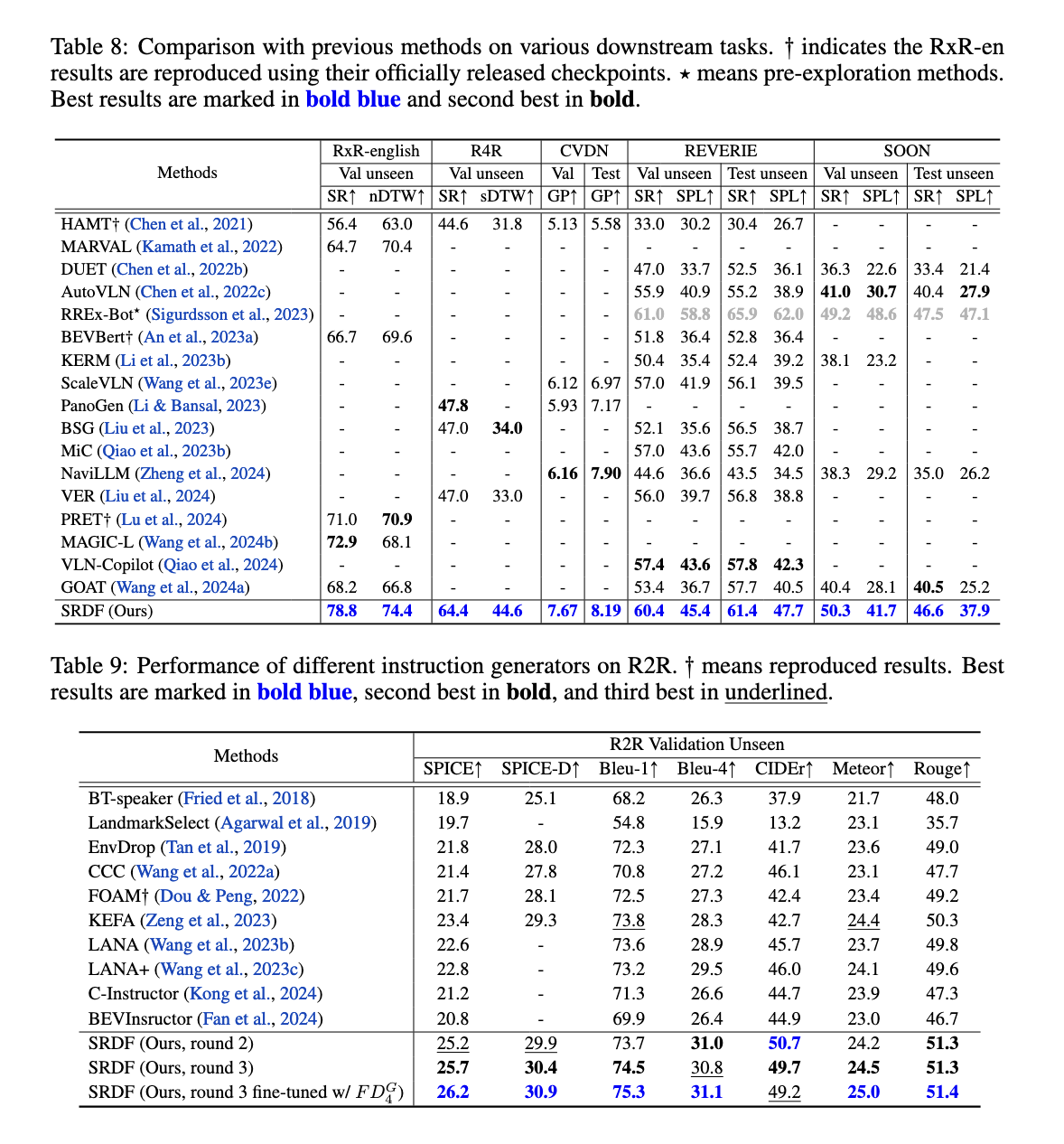
Especificamente, o sistema funciona muito bem na navegação de longo horizonte, alcançando uma melhoria de 16,6% na taxa de sucesso no conjunto de dados R4R. O conjunto de dados CVDN melhorou significativamente a métrica de Progresso da Meta, superando todos os modelos anteriores. Além disso, a escalabilidade do SRDF foi demonstrada à medida que o gerador de instruções melhora consistentemente com grandes conjuntos de dados e ambientes diversos, garantindo desempenho robusto em diversas tarefas e benchmarks. Os pesquisadores também relataram maior diversidade e riqueza instrucional, com mais de 10.000 palavras únicas incluídas no conjunto de dados gerado pelo SRDF, abordando as limitações de vocabulário de conjuntos de dados anteriores.
A abordagem SRDF aborda o desafio de longa data da escassez de dados na VLN, otimizando o conjunto de dados. A interação iterativa entre o navegador e o criador do guia garante a melhoria contínua de ambas as partes, levando a conjuntos de dados mais precisos e de maior qualidade. Esta abordagem inovadora estabeleceu um novo padrão na pesquisa VLN, demonstrando o importante papel da qualidade e alinhamento dos dados no desenvolvimento de IA integrada. Com a sua capacidade de superar o desempenho humano e generalizar uma ampla gama de tarefas, o SRDF está preparado para impulsionar um progresso significativo no desenvolvimento de sistemas de navegação inteligentes.
Confira eu Página de papel e GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 Tendências: LG AI Research revela EXAONE 3.5: três modelos Al Frontier bilíngues de dois níveis que oferecem comandos de próxima geração incomparáveis e insights de conteúdo de longo prazo Liderança global em excelência em IA generativa….
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)


