
Redes Convolucionais de Grafos (GCNs) tornaram-se um componente importante na análise de dados complexos estruturados em grafos. Essas redes capturam as relações entre os nós e seus atributos, tornando-os muito importantes em domínios como análise de redes sociais, biologia e química. Ao utilizar estruturas gráficas, os GCNs permitem funções de classificação de nós e predição de links, promovendo avanços em aplicações científicas e industriais.
O treinamento de gráficos em grande escala apresenta desafios significativos, especialmente na manutenção da eficiência e escalabilidade. Os padrões irregulares de acesso à memória causados pela dispersão do gráfico e pela extensa conectividade necessária para o treinamento distribuído dificultam o desempenho ideal. Além disso, o particionamento de gráficos em subconjuntos de computação distribuída cria cargas de trabalho desiguais e aumenta a sobrecarga de comunicação, tornando o processo de treinamento ainda mais difícil. Enfrentar estes desafios é essencial para permitir a formação de GCNs em grandes conjuntos de dados.
Os métodos de treinamento GCN existentes incluem métodos de lote pequeno e lote completo. O treinamento em minilote reduz o uso de memória ao amostrar subgráficos menores, permitindo que a computação seja dimensionada dentro de recursos limitados. No entanto, este método muitas vezes sacrifica a precisão, pois precisa preservar a estrutura geral do gráfico. Embora preserve a estrutura do gráfico, o treinamento em lote completo enfrenta problemas de robustez devido ao aumento dos requisitos de memória e comunicação. A maioria dos frameworks atuais são projetados para plataformas GPU, com foco limitado no desenvolvimento de soluções eficientes para sistemas baseados em CPU.
Uma equipe de pesquisadores, incluindo participantes do Instituto de Tecnologia de Tóquio, RIKEN, do Instituto Nacional de Ciência e Tecnologia Industrial Avançada e do Laboratório Nacional Lawrence Livermore, introduziu uma nova estrutura chamada SuperGCN. Este programa foi projetado para supercomputadores com uso intensivo de CPU, abordando os desafios de robustez e eficiência no treinamento GCN. A estrutura preenche uma lacuna no aprendizado distribuído de grafos, concentrando-se na otimização relacionada a grafos e técnicas de redução de comunicação.
SuperGCN utiliza diversas técnicas novas para melhorar seu desempenho. A estrutura usa uma implementação otimizada de operadores gráficos específica da CPU, o que garante o uso eficiente da memória e uma carga de trabalho equilibrada em todos os threads. Os pesquisadores propuseram uma estratégia de fusão híbrida que usa um algoritmo de cobertura mínima de vértices para dividir as arestas em conjuntos pré e pós-fusão, o que minimiza conexões redundantes. Além disso, a estrutura inclui escalonamento Int2 para compactar mensagens durante a comunicação, reduzindo significativamente os volumes de transferência de dados sem comprometer a precisão. A distribuição de rótulos é usada em conjunto com a expansão de valor para reduzir os efeitos da precisão reduzida, garantindo a convergência e mantendo a alta precisão do modelo.
O desempenho do SuperGCN foi avaliado em conjuntos de dados como Ogbn-products, Reddit e os grandes Ogbn-papers100M, mostrando uma melhoria significativa em relação aos métodos existentes. A estrutura foi até seis vezes mais rápida que o DistGNN da Intel em sistemas baseados em Xeon, com desempenho escalonado proporcionalmente à medida que o número de processadores aumentava. Em supercomputadores baseados em ARM, como o Fugaku, o SuperGCN atingiu mais de 8.000 processadores, demonstrando a escalabilidade incomparável das plataformas de CPU. A estrutura alcançou velocidades de processamento comparáveis aos sistemas baseados em GPU, exigindo muito menos energia e custo. Para Ogbn-papers100M, o SuperGCN alcançou uma precisão de 65,82% com a propagação de rótulos habilitada, superando outros métodos baseados em CPU.
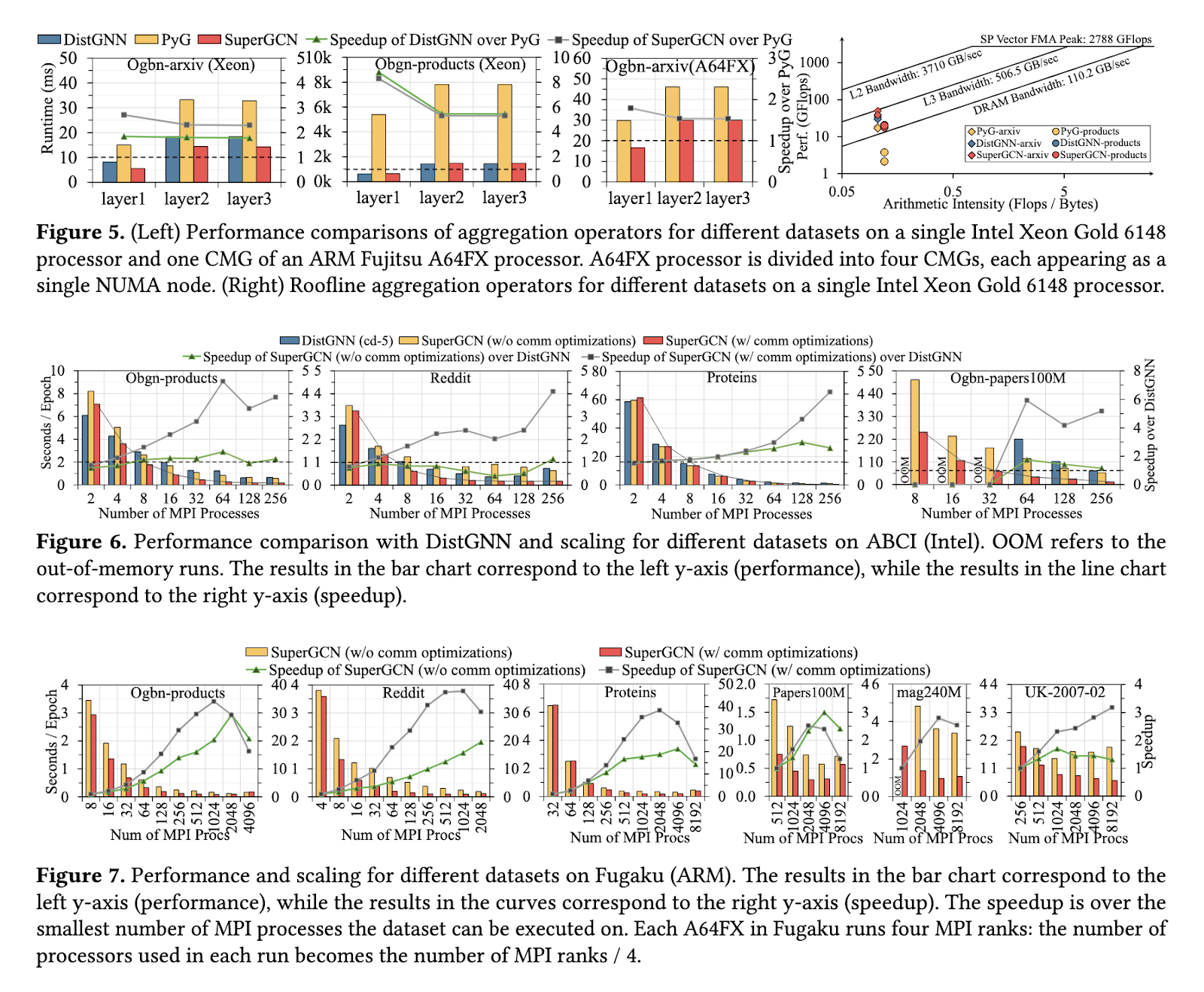
Ao introduzir o SuperGCN, os pesquisadores enfrentaram desafios importantes no treinamento distribuído de GCN. Seu trabalho mostra que soluções eficientes e escaláveis são possíveis em plataformas com uso intensivo de CPU, fornecendo uma alternativa econômica aos sistemas baseados em GPU. Este desenvolvimento marca um passo importante para permitir o processamento de gráficos em grande escala, mantendo a sustentabilidade computacional e ambiental.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
🎙️ 🚨 'Avaliação de vulnerabilidade de um grande modelo de linguagem: uma análise comparativa dos métodos da Cruz Vermelha' Leia o relatório completo (Promovido)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)


