
O pré-treinamento automático provou ser um divisor de águas no aprendizado de máquina, especialmente em relação ao processamento sequencial de dados. A modelagem preditiva de elementos sequenciais tem tido muito sucesso no processamento de linguagem natural e, cada vez mais, tem sido explorada nos domínios da visão computacional. A modelagem de vídeo é uma área inexplorada, oferecendo oportunidades de extensão para reconhecimento de ações, rastreamento de objetos e aplicações robóticas. Essa melhoria se deve ao crescimento dos conjuntos de dados e à inovação das arquiteturas de transformadores que tratam as entradas visuais como tokens estruturados adequados para treinamento automático.
A modelagem de vídeos apresenta desafios únicos devido à sua variabilidade temporal e aleatoriedade. Ao contrário do texto simples, os quadros de vídeo geralmente contêm informações abstratas, dificultando a tokenização e a leitura de representações apropriadas. Uma modelagem de vídeo adequada deve ser capaz de superar esta fraqueza ao capturar as relações espaço-temporais nos quadros. A maioria das estruturas concentra-se na representação baseada em imagens, deixando aberto o desenvolvimento de arquiteturas de vídeo. A tarefa requer novas formas de equilibrar eficiência e eficácia, especialmente quando a previsão de vídeo e a manipulação robótica estão em jogo.
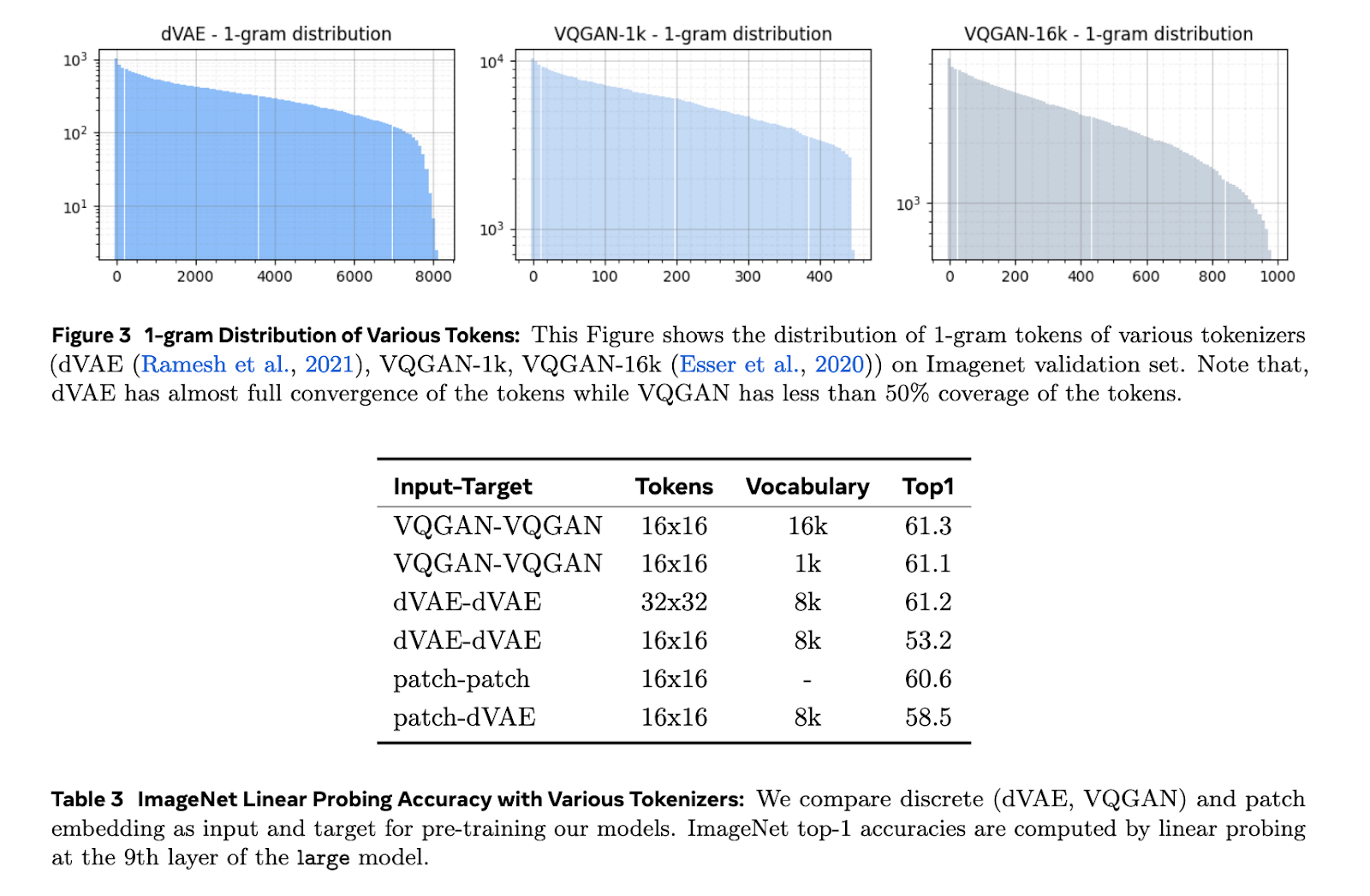
O aprendizado de representações visuais com redes convolucionais e codificadores automáticos ocultos tem sido bem-sucedido em tarefas de imagem. Tais métodos muitas vezes falham em aplicações de vídeo, pois não conseguem expressar totalmente as dependências temporais. Métodos de tokenização como dVAE e VQGAN geralmente convertem informações visuais em tokens. Isto provou funcionar bem, mas dimensionar tal método torna-se um desafio em situações com conjuntos de dados mistos, incluindo imagens e vídeos. A tokenização baseada em patch não é uma prática comum para atender bem a várias tarefas em vídeo.
Uma equipe de pesquisadores da Meta FAIR e da UC Berkeley apresentou a família Toto de modelos de vídeo autorregressivos. Sua inovação ajuda a resolver as limitações dos métodos tradicionais, tratando os vídeos como uma sequência de tokens visuais visíveis e usando propriedades de transformadores causais para prever os próximos tokens. Os pesquisadores desenvolveram modelos que podem combinar facilmente o treinamento de imagem e vídeo, treinando em um conjunto de dados combinado que inclui mais de um milhão de tokens de imagem e vídeo. A abordagem combinada permitiu que a equipe aproveitasse o poder do treinamento automatizado em ambos os domínios.
Os modelos Toto usam o token dVAE e o vocabulário de token 8k para processar imagens e quadros de vídeo. Cada quadro é redimensionado e tokenizado separadamente, resultando em uma sequência de 256 tokens. Esses tokens são então processados por um transformador causal usando recursos RMSNorm e incorporações RoPE para estabelecer melhor desempenho do modelo. O treinamento foi realizado no conjunto de dados ImageNet e HowTo100M, um token com resolução de 128 × 128 pixels. Os pesquisadores também prepararam os modelos para as tarefas abaixo, substituindo a integração central pela integração de atenção para garantir uma melhor qualidade de representação.
Os modelos apresentam bom desempenho em todos os benchmarks. Na classificação ImageNet, o maior modelo Toto alcançou a maior precisão de 1º, 75,3%, superando outros modelos de geração, como MAE e iGPT. Na tarefa de reconhecimento de ação do Kinetics-400, os modelos alcançaram a maior precisão de 1 de 74,4%, o que comprova sua capacidade de compreender dinâmicas temporais complexas. No conjunto de dados DAVIS de vigilância por vídeo semissupervisionada, os modelos alcançam uma pontuação J&F de até 62,4, melhorando assim os benchmarks de última geração estabelecidos pela DINO e MAE. Além disso, para tarefas robóticas, como manipulação de objetos, os modelos Toto aprendem muito rapidamente e têm boa amostragem. Por exemplo, o modelo Toto-base detecta a tarefa do mundo real de escolher um cubo em um robô Franka com 63% de precisão. No geral, estes são resultados surpreendentes em termos da diversidade e do alcance dos modelos propostos com diferentes aplicações.

O trabalho proporcionou avanços significativos na modelagem de vídeo, abordando desafios de redundância e tokenização. Os investigadores demonstraram com sucesso “através de treino combinado em imagens e vídeos, que este tipo de treino automático é eficaz numa série de tarefas”. Novos designs e técnicas de tokenização fornecem a base para especulações mais densas e pesquisas de reconhecimento. Este é um passo importante para desbloquear todo o potencial da modelagem de vídeo em aplicações do mundo real.
Confira Página de papel e design. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 65k + ML.
🚨 PRÓXIMO WEBINAR GRATUITO DE IA (15 DE JANEIRO DE 2025): Aumente a precisão do LLM com dados artificiais e inteligência experimental–Participe deste webinar para obter insights práticos sobre como melhorar o desempenho e a precisão do modelo LLM e, ao mesmo tempo, proteger a privacidade dos dados.
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
✅ [Recommended Read] Nebius AI Studio se expande com modelos de visão, novos modelos de linguagem, incorporados e LoRA (Aprimorado)
: Estendendo a Estrutura HELM para VLMs")

