 para melhorar a qualidade da amostragem de modelos de distribuição produtiva")
Modelos de distribuição eles estão intimamente relacionados ao aprendizado de simulação porque fazem amostragem refinando gradualmente o ruído aleatório em dados significativos. Este processo é guiado clonagem comportamentalum método comum de simulação de aprendizagem onde o modelo aprende a copiar as ações do especialista passo a passo. Nos modelos de difusão, um processo pré-definido converte o som na amostra final, e seguir esse processo garante resultados de alta qualidade em diversas tarefas. No entanto, a clonagem comportamental também cria uma velocidade de produção lenta. Isso acontece porque o modelo é treinado para seguir um método detalhado com muitos pequenos passos, muitas vezes exigindo centenas ou milhares de cálculos. No entanto, essas etapas são computacionalmente caras em termos de tempo e exigem muita computação, e realizar menos etapas de produção reduz a qualidade do modelo.
Os métodos atuais melhoram o processo de amostragem sem alterar o modelo, como ajustando programações de áudio, desenvolvendo solucionadores de equações diferenciaise usar não–Markoviano métodos. Outros melhoram a qualidade da amostra treinando redes neurais em amostras de curto prazo. As técnicas de destilação são promissoras, mas muitas vezes tornam os modelos menos eficazes. No entanto, métodos de aprendizagem por conflito ou por reforço podem substituí-los. RL atualiza modelos de distribuição com base em sinais de recompensa usando gradientes de política ou funções de valor diferencial.
Para resolver isso, pesquisadores de tInstituto Coreano de Estudos Avançados, Universidade Nacional de Seul, Universidade de Seul, Universidade Hanyang, de novo Pesquisa Saige sugeriu duas melhorias nos modelos de difusão. O primeiro método, chamado Difusão por Aprendizagem por Reforço Inverso de Entropia Máxima (DxMI)combinou dois métodos: distribuição e Modelos Baseados em Energia (EBM). Nesta abordagem, a EBM utilizou recompensas para medir a qualidade dos resultados. O objetivo era ajustar a recompensa e a entropia (incerteza) no modelo de distribuição para tornar o treinamento mais estável e garantir que ambos os modelos funcionassem bem com os dados. O segundo desenvolvimento, Distribuição com Programação Dinâmica (DxDP)apresentou um algoritmo de aprendizagem por reforço que simplifica a estimativa de entropia, melhorando o limite superior do objetivo e elimina a necessidade de retropropagação no tempo, enquadrando a tarefa como um problema de controle ótimo, usando programação dinâmica para uma convergência mais rápida e eficiente.
Os testes são mostrados DxMI eficiência na propagação de treinamento e modelos baseados em energia (EBMs) para tarefas como processamento de imagens e detecção de anomalias. Porque 2D dados sintéticos, o DxMI melhorou a qualidade da amostra e a precisão da função de potência com o parâmetro de entropia padrão apropriado. Foi demonstrado que o treinamento prévio em DDPM é útil, mas não necessário DxMI para trabalhar. DxMI modelos bem organizados como DDPM de novo Música eletrônica com diversas etapas para produzir imagens de qualidade competitiva. Na detecção de anomalias, a função de potência do DxMI fazer melhor na detecção e processamento de anomalias no ambiente MVTec-AD O conjunto de dados. Aumentar a Entropia melhora o desempenho, promovendo a exploração e aumentando a diversidade de modelos.
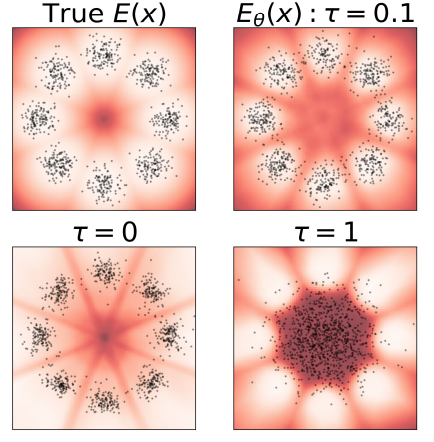
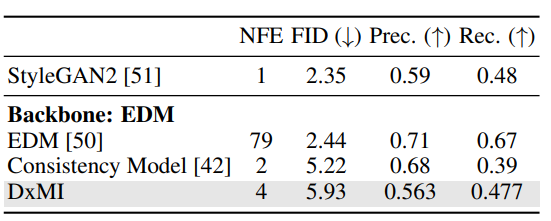
Em resumo, o método proposto melhora significativamente a eficiência e a qualidade dos modelos de distribuição generativos usando o método DxMI. Ele resolve os problemas dos métodos anteriores, como velocidade de produção lenta e qualidade degradada da amostra. No entanto, não é diretamente adequado para treinar geradores de uma etapa, mas um modelo de difusão bem ajustado por DxMI pode ser convertido em um. O DxMI não tem flexibilidade para usar diferentes etapas de produção durante os testes. Este método pode ser utilizado para futuras pesquisas neste domínio e servir de base, o que faz uma grande diferença!
Confira eu Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 Tendências: LG AI Research Release EXAONE 3.5: Modelos de três níveis de IA bilíngue de código aberto oferecem seguimento de comando incomparável e insights profundos de conteúdo Liderança global em excelência em IA generativa….
Divyesh é estagiário de consultoria na Marktechpost. Ele está cursando BTech em Engenharia Agrícola e Alimentar pelo Instituto Indiano de Tecnologia, Kharagpur. Ele é um entusiasta de Ciência de Dados e Aprendizado de Máquina que deseja integrar essas tecnologias avançadas no domínio agrícola e resolver desafios.
🧵🧵 [Download] Avaliação do relatório de trauma do modelo de linguagem principal (estendido)


