
Redes Neurais de Grafos (GNNs) são um campo em rápido desenvolvimento em aprendizado de máquina, projetado especificamente para analisar dados estruturados em grafos que representam entidades e seus relacionamentos. Essas redes têm sido amplamente utilizadas em análises de redes sociais, sistemas de recomendação e aplicações de interpretação de dados moleculares. Um subconjunto de GNNs, Redes Neurais de Gráficos Baseadas em Atenção (AT-GNNs), usa mecanismos de atenção para melhorar a precisão da previsão e interpretação, destacando as relações mais relevantes nos dados. No entanto, sua complexidade computacional cria grandes desafios, especialmente no uso eficaz de GPUs para treinamento e compreensão.
Um dos principais problemas no treinamento AT-GNN é a ineficiência causada pelos diferentes desempenhos da GPU. O cálculo envolve muitas etapas complexas, como calcular pontos de atenção, normalizar esses pontos e combinar dados de recursos, o que requer uma introdução geral do kernel e movimentação de dados. As estruturas existentes precisam se adaptar à natureza dos gráficos do mundo real, o que leva a cargas de trabalho desiguais e a uma escalabilidade reduzida. O problema é agravado por supernós – nós com vizinhos excepcionalmente grandes – que comprimem os recursos de memória e degradam o desempenho.
As estruturas GNN existentes, como PyTorch Geometric (PyG) e Deep Graph Library (DGL), tentam melhorar o desempenho usando clustering de kernel e agendamento de threads. Técnicas como Seastar e dgNN melhoraram o desempenho e a carga geral do GNN. No entanto, esses métodos dependem de técnicas invariantes paralelas que não podem se adaptar aos requisitos computacionais exclusivos dos AT-GNNs. Por exemplo, eles precisam de ajuda com threading heterogêneo e aproveitam ao máximo o clustering do kernel ao lidar com estruturas gráficas que contêm supernós ou padrões de cluster incomuns.
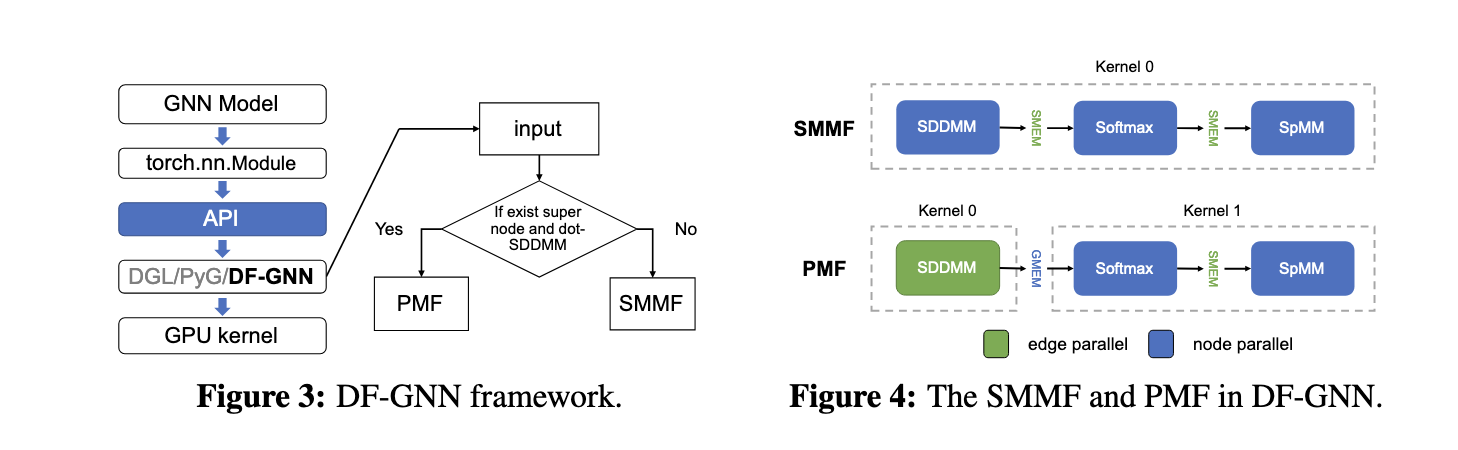
Uma equipe de pesquisadores da Shanghai Jiao Tong University e da Amazon Web Services propôs o DF-GNN, uma estrutura combinatória dinâmica projetada especificamente para melhorar o uso de AT-GNNs em GPUs. Integrado à estrutura PyTorch, o DF-GNN apresenta um novo método de programação em série de dois níveis que permite o ajuste adaptativo da distribuição em série. Essa flexibilidade garante que operações como normalização Softmax e multiplicação mínima de matrizes sejam realizadas com uso ideal de thread, melhorando bastante o desempenho. O DF-GNN aborda as ineficiências associadas às técnicas de integração do kernel, permitindo diferentes estratégias de escalonamento para cada tarefa.
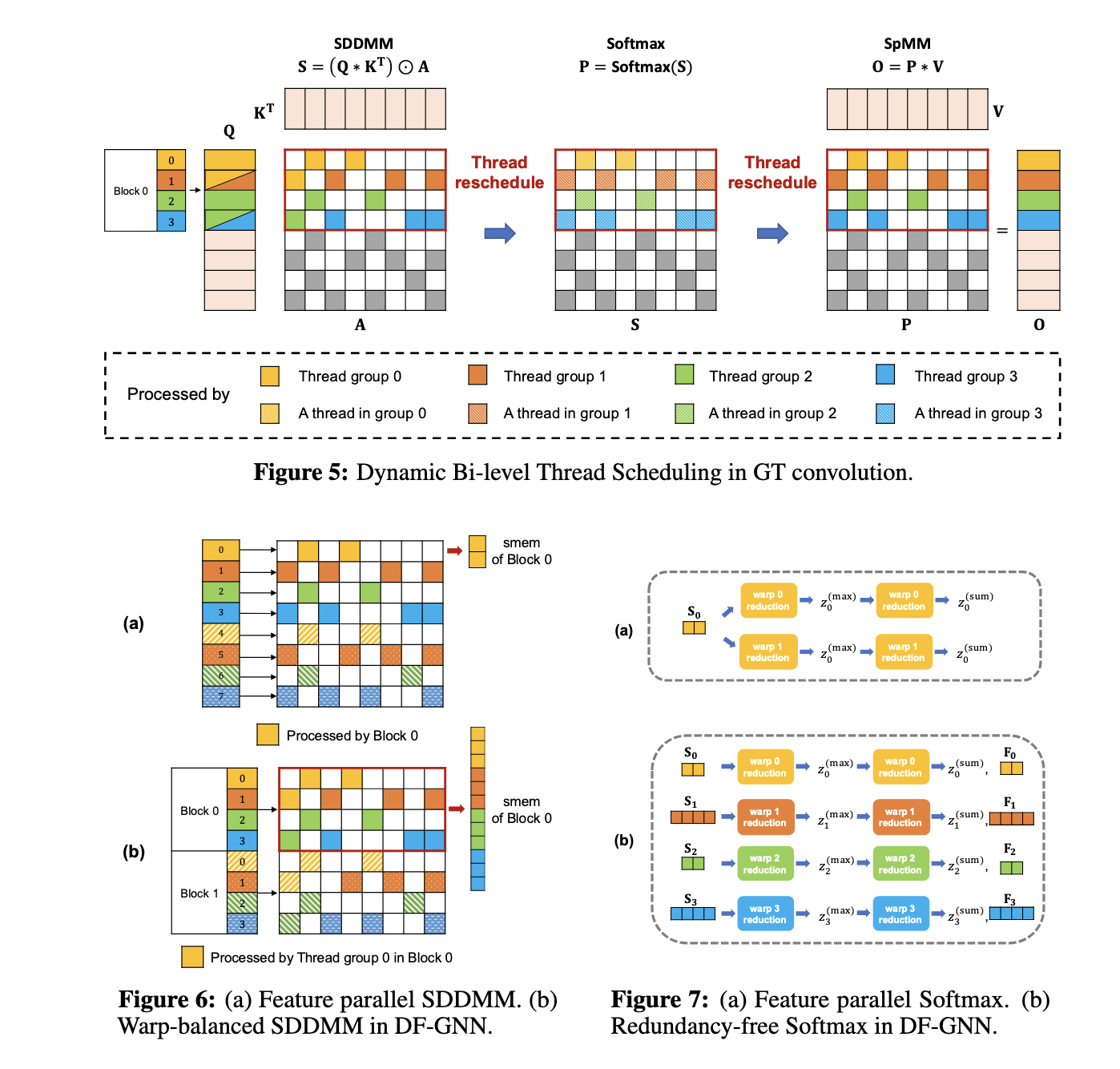
O DF-GNN usa as duas primeiras técnicas de fusão: Fusão de Maximização de Memória Compartilhada (SMMF) e Fusão de Maximização de Paralelismo (PMF). O SMMF consolida as operações em um único canal, otimizando o uso da memória ao armazenar resultados intermediários em memória compartilhada, reduzindo assim a movimentação de dados. Em contraste, o PMF concentra-se em gráficos com supernós, onde as estratégias paralelas às arestas têm melhor desempenho do que as estratégias paralelas aos nós. Além disso, a estrutura introduz otimizações otimizadas, como agendamento balanceado para convergência de bordas, Softmax livre de redundância para eliminar cálculos repetidos e acesso à memória exposta para reduzir a memória global. Esses recursos garantem o processamento de cálculos progressivos e regressivos, ajudando a acelerar o treinamento final.
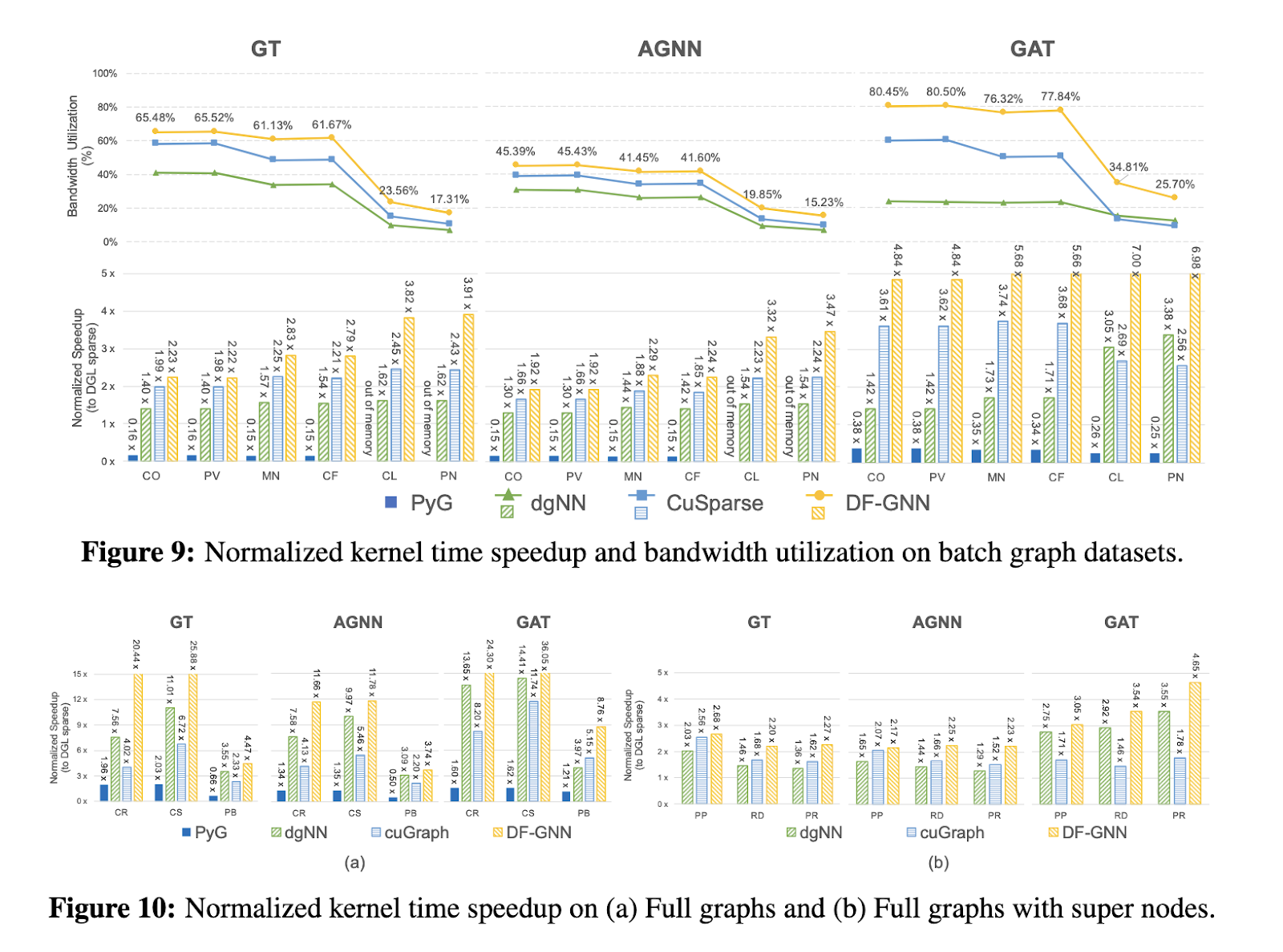
Experimentos extensos mostram as notáveis vantagens de desempenho do DF-GNN. Para conjuntos de dados gráficos completos, como Cora e Citeseer, DF-GNN obteve aceleração moderada 16,3x em comparação com a biblioteca DGL menor, que tem uma melhoria máxima de até 7x na execução do kernel. Para conjuntos de dados de gráficos de cluster, incluindo gráficos de alto nível como PATTERN, ele fornece uma medida de aceleração 3,7xsuperando concorrentes como cuGraph e dgNN, que só alcançaram 2,4x de novo 1,7xrespectivamente. Além disso, o DF-GNN apresentou alta flexibilidade em conjuntos de dados com supernós como Reddit e Protein, alcançando uma média 2,8x acelerar enquanto mantém o uso restrito da memória. A utilização da largura de banda do quadro permanece consistentemente alta, garantindo desempenho ideal em todos os tamanhos e arquiteturas de gráficos.
Além da otimização no nível do kernel, o DF-GNN também acelera o fluxo de trabalho de treinamento de ponta a ponta. Nos conjuntos de dados do gráfico de cluster, encontrou uma aceleração média de 1,84x com sessões de treinamento completas, com cada atualização de passe acessível 3,2x. A aceleração é estendida para 2,6x em conjuntos de dados gráficos completos, destacando a eficiência do DF-GNN no tratamento de diversas cargas de trabalho. Estes resultados enfatizam a capacidade do framework de se adaptar dinamicamente a diferentes ambientes computacionais, tornando-o uma ferramenta versátil para aplicações GNN em larga escala.
Abordando as ineficiências do treinamento AT-GNN em GPUs, o DF-GNN apresenta uma solução completa que se adapta dinamicamente a diferentes características computacionais e gráficas. Ao abordar questões importantes como uso de memória e agendamento de threads, esta estrutura estabelece uma nova referência no desenvolvimento de GNN. Sua integração com PyTorch e suporte para vários conjuntos de dados garantem ampla funcionalidade, abrindo caminho para sistemas de aprendizagem baseados em gráficos mais rápidos e eficientes.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
🎙️ 🚨 'Avaliação de vulnerabilidade de um grande modelo de linguagem: uma análise comparativa dos métodos da Cruz Vermelha' Leia o relatório completo (Promovido)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
🧵🧵 [Download] Avaliação do relatório do modelo de risco linguístico principal (ampliado)


