
Modelos linguísticos de grande escala (LLMs) ganharam muita atenção por sua capacidade de compreender e processar textos semelhantes aos humanos. Esses modelos têm uma capacidade única de sintetizar informações de forma eficaz, devido à grande quantidade de dados sobre os quais são treinados. Essa capacidade é essencial para uma variedade de aplicações, desde tarefas de processamento de linguagem natural (PNL) até formas mais avançadas de inteligência artificial. No entanto, compreender como estes modelos adquirem e retêm informações factuais durante o treinamento é um desafio complexo. Este estudo investiga o complexo processo pelo qual os LLMs internalizam o conhecimento e examina como esses modelos podem ser desenvolvidos para preservar e generalizar o conhecimento que adquirem.
Um dos maiores problemas que os investigadores enfrentam na formação de LLMs é a perda de conhecimento factual ao longo do tempo. Ao utilizar grandes conjuntos de dados na formação antecipada, os LLMs lutam para reter informações sobre certos factos, especialmente quando novas informações são introduzidas em fases subsequentes da formação. Além disso, os LLMs muitas vezes têm dificuldade em lembrar informações esparsas ou de cauda longa, o que afeta muito a sua capacidade de sintetizar diversos tópicos. Esta perda de armazenamento prejudica a precisão dos modelos quando aplicados a situações complexas ou incomuns encontradas, o que representa uma grande barreira para melhorar o desempenho dos LLMs.
Muitas abordagens foram apresentadas para enfrentar esses desafios, com foco na melhoria da aquisição e retenção de informações autênticas em LLMs. Esses métodos incluem aumentar o tamanho dos modelos e conjuntos de dados de pré-treinamento, usar técnicas avançadas de otimização e ajustar os tamanhos dos clusters para lidar melhor com os dados durante o treinamento. A iteração do conjunto de dados também foi proposta para reduzir a reutilização de dados de treinamento, levando a um aprendizado mais eficiente. Apesar destes esforços, os problemas básicos do esquecimento rápido e a dificuldade do modelo em gerar factos invulgares persistem, e as soluções actuais têm registado progressos constantes.
Pesquisadores do KAIST, UCL e KT introduziram um novo método para estudar a aquisição e retenção de conhecimento factual em LLMs. Eles projetaram um experimento que introduziu sistematicamente novas informações factuais no modelo durante o pré-treinamento. Ao analisar a capacidade do modelo de memorizar e generalizar esta informação sob várias condições, os investigadores pretenderam descobrir as forças que governam a forma como os LLMs aprendem e esquecem. Sua abordagem envolve monitorar o desempenho do modelo em diferentes ambientes de teste e observar o impacto de fatores como tamanho do cluster, redundância de dados e resumo da retenção de informações. Este experimento forneceu informações valiosas sobre o desenvolvimento de estratégias de treinamento para melhorar a memória de longo prazo em LLMs.
A metodologia dos pesquisadores foi abrangente, envolvendo avaliações detalhadas em múltiplas etapas de pré-treinamento. Eles conduzem testes usando informações simuladas que o modelo não encontrou antes para garantir a precisão da análise. Vários cenários foram testados, incluindo a injeção repetida da mesma informação factual, parafraseando-a ou apresentando-a apenas uma vez. Para medir o desempenho da retenção, a equipe testou o desempenho do modelo examinando as mudanças na probabilidade de recordar certos fatos ao longo do tempo. Eles descobriram que lotes maiores ajudaram o modelo a reter informações verdadeiras de maneira mais eficaz, enquanto dados redundantes levavam a um esquecimento mais rápido. Ao utilizar uma variedade de condições experimentais, a equipa de investigação pode determinar as estratégias mais eficazes para treinar LLMs para reter e generalizar o conhecimento.
O desempenho do método proposto revelou várias descobertas importantes. Primeiro, o estudo mostrou que modelos grandes, como aqueles com 7 mil milhões de parâmetros, apresentaram melhor retenção de informações verdadeiras do que modelos mais pequenos com apenas 1 mil milhões de parâmetros. Curiosamente, a quantidade de dados de treinamento utilizados não afetou significativamente a retenção, contradizendo a crença de que mais dados levam a um melhor desempenho do modelo. Em vez disso, os investigadores descobriram que os modelos treinados no conjunto de dados extraído eram mais poderosos, com taxas de esquecimento mais lentas. Por exemplo, modelos expostos a informações definidas por palavras apresentam um alto grau de generalidade, o que significa que podem utilizar a informação de forma flexível em diferentes situações.
Outra descoberta importante foi a relação entre o tamanho da pilha e a retenção de informações. Modelos treinados com clusters maiores, como 2048, mostraram maior resistência ao esquecimento do que aqueles treinados com clusters menores de 128. O estudo também revelou uma relação linear entre as etapas de treinamento e esquecimento, o que mostra que o verdadeiro conhecimento diminui rapidamente nos modelos. treinado em dados duplicados. Por outro lado, modelos expostos a um grande volume de fatos únicos retêm essas informações por muito tempo, enfatizando a importância da qualidade do conjunto de dados em detrimento da quantidade. Por exemplo, a constante de decaimento para dados repetidos na fase de treinamento posterior foi de 0,21, em comparação com 0,16 para os dados indicados, indicando um esquecimento mais lento quando o conjunto de dados é repetido.
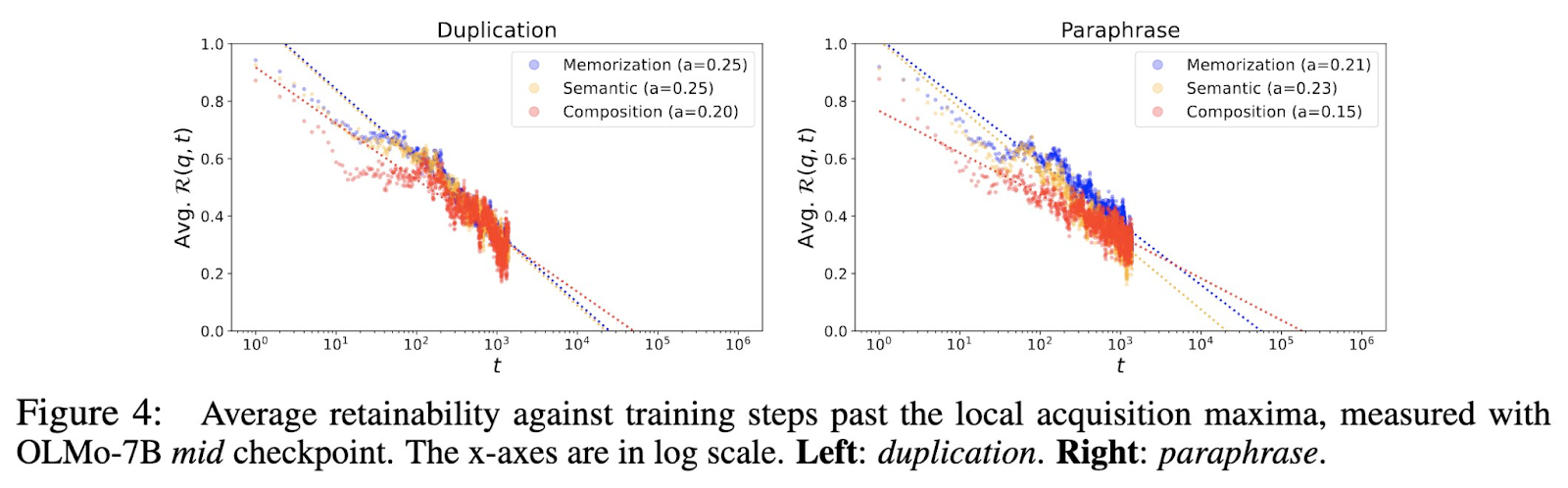
O estudo oferece uma abordagem promissora para abordar questões de esquecimento e negligência em LLMs. Os resultados sugerem que aumentar o tamanho e a frequência da coorte durante a fase de formação pode melhorar significativamente a retenção do conhecimento factual nos LLMs. Estas melhorias podem tornar os modelos mais fiáveis numa vasta gama de tarefas, especialmente quando se trabalha com informações irregulares ou de cauda longa. Finalmente, este estudo fornece uma compreensão clara dos processos por trás da aquisição de conhecimento em LLMs, abrindo novos caminhos para pesquisas futuras para refinar métodos de treinamento e melhorar as capacidades desses modelos dinâmicos.
Esta pesquisa forneceu informações importantes sobre como os modelos linguísticos em grande escala adquirem e armazenam informações. Ao identificar fatores como tamanho do modelo, tamanho do cluster e qualidade do conjunto de dados, o estudo fornece soluções práticas para melhorar o desempenho do LLM. Estas conclusões destacam a importância de estratégias de formação eficazes e enfatizam o potencial do desenvolvimento de LLMs para serem mais eficazes no tratamento de tarefas linguísticas complexas e diversas.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Assine o boletim informativo de ML de rápido crescimento com mais de 26 mil assinantes.
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.


