
O aprendizado de máquina se concentra no desenvolvimento de modelos que podem aprender com grandes conjuntos de dados para melhorar suas capacidades preditivas e de tomada de decisão. Uma das principais áreas de desenvolvimento no aprendizado de máquina são as redes neurais, que são críticas para tarefas como reconhecimento de imagens, processamento de linguagem e tomada de decisão autônoma. Esses modelos são regidos por leis de escala, que sugerem que aumentar o tamanho dos modelos e a quantidade de dados de treinamento melhora o desempenho. No entanto, esta melhoria depende da qualidade dos dados utilizados, especialmente se dados artificiais forem incluídos no processo de treino.
Um problema crescente no aprendizado de máquina é a degradação do desempenho do modelo quando dados sintéticos são usados para treinamento. Ao contrário dos dados do mundo real, os dados sintéticos podem capturar a complexidade e a riqueza dos conjuntos de dados naturais. Esse problema leva ao que os pesquisadores chamam de “colapso do modelo”, quando o modelo começa a ficar sobrecarregado com padrões artificiais. Estes padrões não representam totalmente a variabilidade dos dados do mundo real, levando o modelo a amplificar erros e preconceitos. Isto resulta numa capacidade comprometida de adaptação a dados novos e não observados do mundo real, tornando o modelo menos confiável em aplicações práticas.
Atualmente, os modelos de aprendizado de máquina são frequentemente treinados em conjuntos de dados que combinam dados reais e sintéticos para dimensionar o tamanho do conjunto de treinamento. Embora esta abordagem permita grandes conjuntos de dados, a estratégia de dados mistos apresenta vários desafios. A equipa de investigação destaca que, embora o dimensionamento de modelos que utilizam dados sintéticos possa parecer benéfico, a inclusão de dados sintéticos de baixa qualidade leva à falha do modelo, minando os benefícios de dados adicionais. Foram explorados ajustes como a ponderação dos dados ou a mistura seletiva dos dados, mas nem sempre evitaram o colapso do modelo.
Pesquisadores do Meta, do NYU Center for Data Science, do NYU Courant Institute e da UCLA apresentaram uma análise abrangente do fenômeno do colapso do modelo. A pesquisa testou se a mistura de dados reais e sintéticos pode prevenir quedas, e eles testaram isso usando diferentes tamanhos de modelos e taxas de dados. As descobertas mostram que mesmo uma pequena parte dos dados sintéticos (apenas 1% do valor do conjunto de dados) pode levar ao colapso do modelo, sendo os modelos grandes facilmente afetados por este problema. Isto sugere que são necessários mais do que métodos tradicionais de combinação de dados reais e artificiais para combater o problema.
A equipe de pesquisa usou modelos de regressão linear e amostragem aleatória para investigar como o tamanho do modelo e o tamanho do modelo interagem com a qualidade dos dados. Eles mostraram que modelos grandes tendem a superestimar quando treinados em dados sintéticos, o que se desvia significativamente da distribuição de dados reais. Embora existam casos em que aumentar o tamanho do modelo possa reduzir ligeiramente a queda, isso não evita completamente o problema. Os resultados são particularmente preocupantes dada a crescente dependência de dados sintéticos em sistemas de IA de grande escala.
Os testes de modelos baseados em imagens usando o conjunto de dados MNIST e modelos de linguagem treinados em BabiStories mostraram que o desempenho do modelo diminui quando dados artificiais são apresentados. Por exemplo, em testes envolvendo modelos de linguagem, a equipe descobriu que dados artificiais, mesmo quando misturados com dados reais, causavam uma queda significativa no desempenho. À medida que a proporção de dados sintéticos aumentou, o erro experimental aumentou, confirmando a robustez do fenómeno de colapso do modelo. Em alguns casos, modelos grandes apresentam erros mais pronunciados, aumentando os vieses e erros encontrados nos dados sintéticos, levando a resultados piores do que modelos menores.
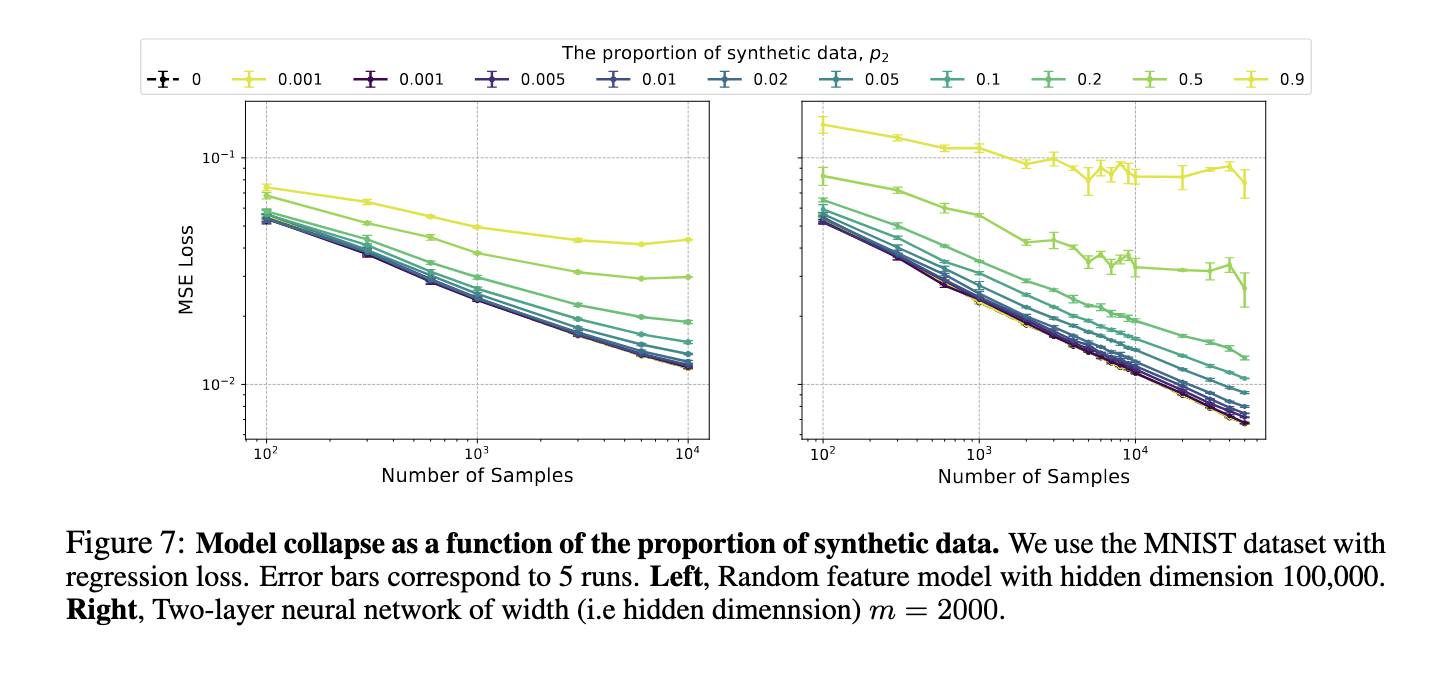
Concluindo, o estudo enfatiza os perigos do uso de dados artificiais para treinar grandes modelos. A convolução do modelo apresenta um desafio crítico que afeta a robustez e a confiabilidade das redes neurais. Embora a investigação forneça informações importantes sobre os mecanismos de colapso do modelo, também sugere que os métodos actuais de mistura de dados reais e sintéticos são inadequados. São necessárias técnicas mais avançadas para garantir que os modelos treinados em dados sintéticos ainda possam ser adaptados com sucesso a situações do mundo real.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] Melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (avançado)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.



")