
Um grande desafio na pesquisa em IA é como desenvolver modelos que possam equilibrar o pensamento rápido e intuitivo e o pensamento lento e detalhado de forma eficiente. A cognição humana funciona por meio de dois sistemas: Sistema 1, que é rápido e intuitivo, e Sistema 2, que é mais lento, porém mais analítico. Nos modelos de IA, esta dicotomia entre estes dois sistemas manifesta-se frequentemente como um compromisso entre eficiência computacional e precisão. Os modelos rápidos retornam resultados rápidos, mas principalmente com o sacrifício da precisão, enquanto os modelos lentos retornam alta precisão, mas ao preço do custo computacional e são demorados. É um desafio integrar estes dois métodos num só, permitindo uma tomada de decisão eficaz sem reduzir o desempenho. É aqui que reside o maior desafio, e superá-lo melhorará muito o desempenho da IA em tarefas complexas do mundo real, como navegação, planejamento e raciocínio.
As técnicas atuais para lidar com tarefas cognitivas muitas vezes dependem de tomadas de decisão rápidas e intuitivas ou de processamento lento e deliberado. Modelos rápidos, como modelos Somente Solução, capturam soluções sem etapas causais, as opções são modelos menos precisos e menos eficientes para tarefas complexas. Por outro lado, modelos que dependem de sequências de raciocínio lentas e exaustivas, como o Searchformer, proporcionam melhor precisão, mas são menos eficientes devido aos longos passos de raciocínio e ao seu alto custo computacional. Muitos métodos que combinam estes métodos, tais como a integração da saída do pensamento lento em modelos rápidos, muitas vezes requerem processamento adicional e controlos externos, aumentando assim rapidamente a complexidade e limitando a flexibilidade. Uma grande limitação neste campo continua a ser a falta de uma estrutura unificada capaz de alternar dinamicamente entre modos de pensamento rápido e lento.
Pesquisadores da Meta apresentam o Dualformer, uma solução inovadora que integra perfeitamente lógica rápida e lenta em um único modelo baseado em transformador. Ele usa dicas de raciocínio aleatório durante o treinamento para que o modelo aprenda a se adaptar entre um modo rápido somente de solução e um modo de raciocínio mais lento baseado em dicas. Pelo contrário, o Dualformer ajusta automática e automaticamente o seu processo de pensamento de acordo com a dificuldade da tarefa e alterna facilmente entre os métodos. Esta inovação aborda diretamente as limitações dos modelos anteriores com melhor desempenho estatístico e maior precisão de raciocínio. O modelo também reduz a sobrecarga computacional usando técnicas de rastreamento sistemático que simulam atalhos humanos na tomada de decisões.
O modelo desenvolvido é baseado em um método sistemático de descarte de traços, no qual os traços cognitivos são gradualmente podados ao longo do processo de treinamento, a fim de focar na eficiência. Assim, pode-se conduzir tal treinamento estratégico em tarefas complexas, como navegação em labirintos ou jogos Sokoban, usando pistas geradas pelo algoritmo de busca A*. Nesse sentido, nós próximos, tokens de custo e etapas de pesquisa no rastreamento lógico são reduzidos seletivamente durante o treinamento para simular processos de decisão rápidos. Isso pode ser randomizado para incentivar o modelo a generalizar bem entre as tarefas e, ao mesmo tempo, ter um bom desempenho nos modos de pensamento rápido e lento. A arquitetura dual-former é uma estrutura de decodificador que pode lidar com essas operações lógicas complexas enquanto tenta manter o custo computacional o mais baixo possível.
O Dualformer apresenta excelentes resultados em uma variedade de tarefas de computação, melhorando significativamente seu desempenho de última geração em precisão e eficiência computacional. Portanto, no modo lento, ele atinge 97,6% de acerto nas tarefas do labirinto usando 45,5% menos etapas de raciocínio em comparação com o modelo básico do Searchformer. No modo rápido, apresenta uma taxa de solução correta de 80%, superando por larga margem o modelo Solution Only, que alcançou apenas 30% de desempenho. Além disso, quando em modo automático o modelo escolhe sua própria estratégia, ela ainda é elevada, com alta taxa de sucesso de 96,6% e quase 60% menos etapas em comparação com outros métodos. Esses jogos apresentam uma compensação para os dualformers entre velocidade e precisão do computador, daí robustez e flexibilidade em tarefas de raciocínio tão complexas.
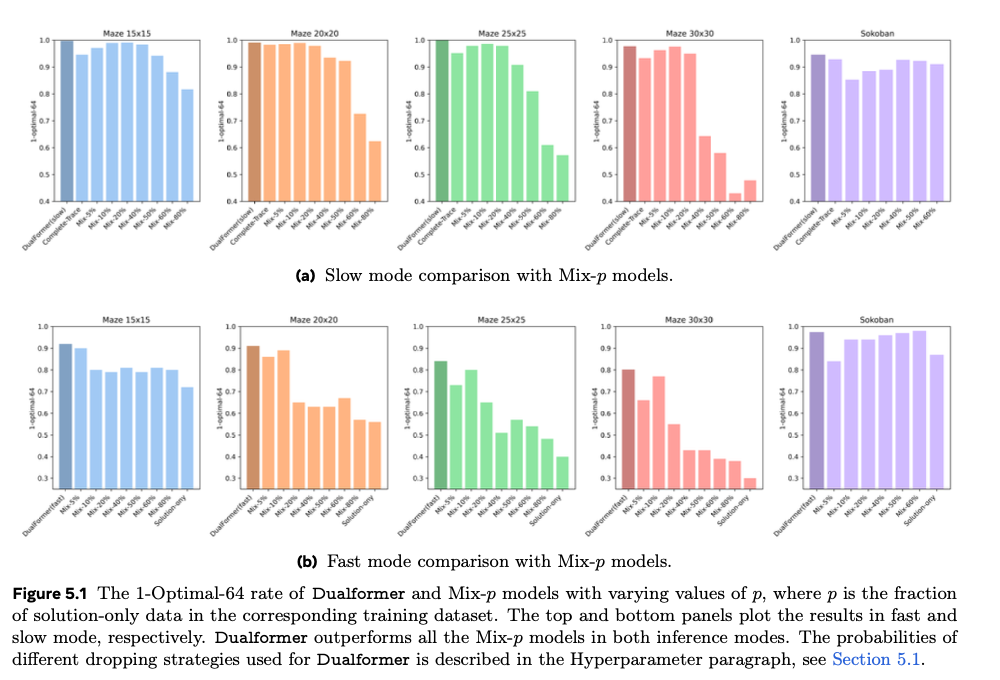
Concluindo, o Dualformer resolveu com sucesso a inclusão do pensamento rápido e lento nos modelos de IA. Durante o treinamento, o modelo funciona com dicas aleatórias e técnicas sistemáticas de descarte de dicas; portanto, é aplicável a todos os modos de pensar e sua adaptabilidade à dificuldade da tarefa é variável. Isso permite uma redução significativa nos requisitos computacionais, mantendo a alta precisão, o que representa um avanço em tarefas computacionais que exigem velocidade e precisão. Graças a esta estrutura única, o Dualformer abre novas oportunidades para usar IA em situações complexas do mundo real, aprimorando suas capacidades em vários campos.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Upcoming Live Webinar- Oct 29, 2024] A melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (atualizado)
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


