
Os modelos linguísticos multimodais (MLLMs) concentram-se na criação de programas de inteligência artificial (IA) que podem interpretar facilmente texto e dados visuais. Esses modelos visam preencher a lacuna entre a compreensão da linguagem natural e a compreensão visual, permitindo que as máquinas processem coletivamente vários tipos de entrada, desde documentos de texto até imagens. A compreensão e o raciocínio multidisciplinares estão a tornar-se cada vez mais importantes, especialmente à medida que a IA avança para aplicações avançadas em áreas como reconhecimento de imagens, processamento de linguagem natural e visão computacional. Ao melhorar a forma como a IA integra e processa diversas fontes de dados, os MLLMs estão preparados para revolucionar tarefas como legendagem de imagens, compreensão de documentos e sistemas interativos de IA.
Um grande desafio no desenvolvimento de MLLMs é garantir que sejam igualmente eficazes em tarefas baseadas em texto e em tarefas linguísticas. Freqüentemente, uma melhoria em uma área pode levar ao declínio em outra. Por exemplo, melhorar a compreensão visual de um modelo pode afetar negativamente as suas capacidades linguísticas, o que é problemático para aplicações que exigem ambos, como o reconhecimento óptico de caracteres (OCR) ou o raciocínio multimodal complexo. O principal problema é equilibrar o processamento de dados visuais, como imagens de alta resolução, e manter uma forte lógica textual. À medida que as aplicações de IA se tornam mais avançadas, esta compensação torna-se um gargalo significativo no avanço dos modelos de IA multimodais.
Os métodos existentes de MLLMs, incluindo modelos como GPT-4V e InternVL, tentaram resolver este problema usando várias técnicas de construção. Esses modelos interrompem o modelo de linguagem durante o treinamento ou usam mecanismos de atenção para processar imagens e tokens de texto simultaneamente. No entanto, esses métodos não são isentos de falhas. Congelar o modelo de linguagem durante o treinamento multimodal geralmente leva a um baixo desempenho em tarefas de percepção de linguagem. Em contraste, modelos de acesso aberto como LLaVA-OneVision e InternVL mostraram prejuízo acentuado no desempenho somente texto após treinamento multimodal. Isto reflete um problema constante na área, onde o desenvolvimento de um método ocorre às custas de outro.
Pesquisadores da NVIDIA apresentaram modelos NVLM 1.0, que representam um avanço significativo na modelagem multilíngue. A família NVLM 1.0 consiste em três arquiteturas principais: NVLM-D, NVLM-X e NVLM-H. Cada um desses modelos aborda as deficiências das abordagens anteriores, combinando capacidades avançadas de raciocínio multimodal com processamento de texto eficiente. Uma característica notável do NVLM 1.0 é a inclusão de dados de ajuste fino supervisionado (SFT) somente texto de alta qualidade durante o treinamento, o que permite que esses modelos mantenham e até mesmo melhorem seu desempenho somente texto, ao mesmo tempo em que são mais eficazes em tarefas de percepção de linguagem. . A equipe de pesquisa destacou que sua metodologia foi projetada para superar os modelos proprietários existentes, como o GPT-4V, e outros métodos de acesso aberto, como o InternVL.
Os modelos NVLM 1.0 usam uma arquitetura híbrida para processamento padrão de texto e imagem. O NVLM-D, um modelo somente decodificador, lida com ambos os modos de maneira unificada, tornando-o particularmente adequado para tarefas de comunicação multimodal. O NVLM-X, por outro lado, é construído por meio de mecanismos de atenção, que melhoram o desempenho do computador no processamento de imagens de alta resolução. Um modelo híbrido, NVLM-H, combina os pontos fortes de ambas as abordagens, permitindo a compreensão detalhada da imagem, mantendo a eficiência necessária para o reconhecimento de texto. Esses modelos incluem mosaico dinâmico de imagens de alta resolução, melhorando significativamente o desempenho de tarefas relacionadas ao OCR sem sacrificar os recursos de imagem. A integração de um sistema de marcação de blocos 1-D permite o processamento preciso de tokens de imagem, o que melhora o desempenho de tarefas como compreensão de documentos e leitura de texto de cena.
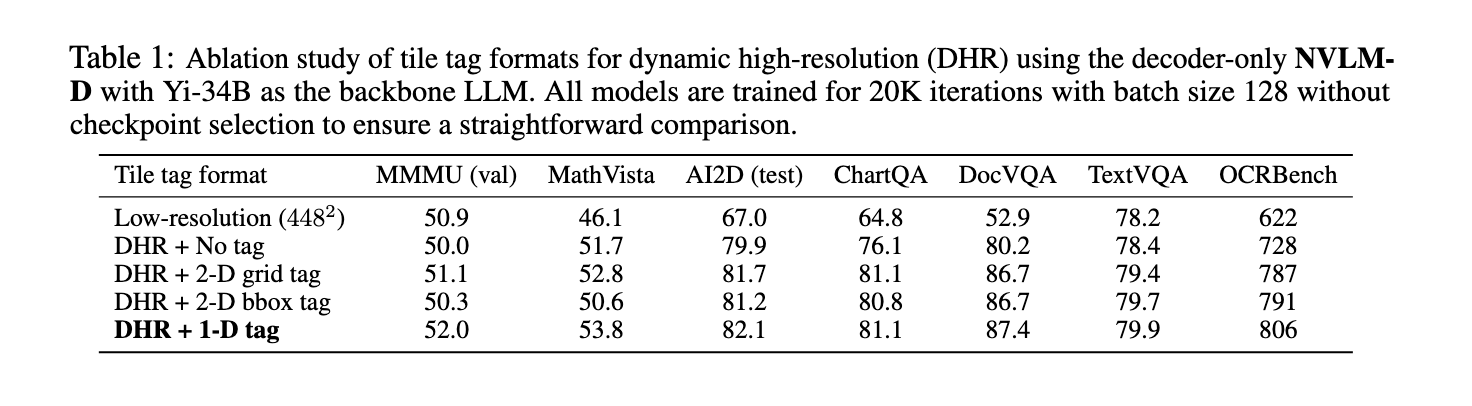
Em termos de desempenho, os modelos NVLM 1.0 alcançaram resultados impressionantes em vários benchmarks. Por exemplo, em tarefas somente de texto, como MATH e GSM8K, o modelo NVLM-D1.0 72B obteve uma melhoria de 4,3 pontos em relação ao seu núcleo somente de texto, devido à combinação de conjuntos de dados de texto de alta qualidade durante o treinamento. Os modelos também apresentaram forte desempenho para percepção de linguagem, com pontuações de precisão de 93,6% no conjunto de dados VQAv2 e 87,4% no AI2D para responder questões visuais e tarefas de raciocínio. Em tarefas relacionadas ao OCR, os modelos NVLM superaram significativamente os sistemas existentes, pontuando 87,4% no DocVQA e 81,7% no ChartQA, destacando sua capacidade de lidar com informações visuais complexas. Esses resultados foram alcançados com os modelos NVLM-X e NVLM-H, que apresentaram gerenciamento superior de imagens de alta resolução e dados multimodais.
Outra descoberta importante do estudo é que os modelos NVLM não só têm sucesso em tarefas de linguagem visual, mas também mantêm ou melhoram o seu desempenho apenas em texto, algo que muitos outros modelos lutam para alcançar. Por exemplo, em tarefas de raciocínio baseadas em texto, como MMLU, os modelos NVLM mantiveram altos níveis de precisão, superando até mesmo seus equivalentes somente em texto em alguns casos. Isto é especialmente importante para aplicações que exigem forte compreensão de texto juntamente com processamento de dados visuais, como análise de documentos e raciocínio de texto de imagem. O modelo NVLM-H, em particular, alcança um equilíbrio entre eficiência de processamento de imagem e precisão de imagem multimodal, tornando-o um dos modelos mais promissores na área.
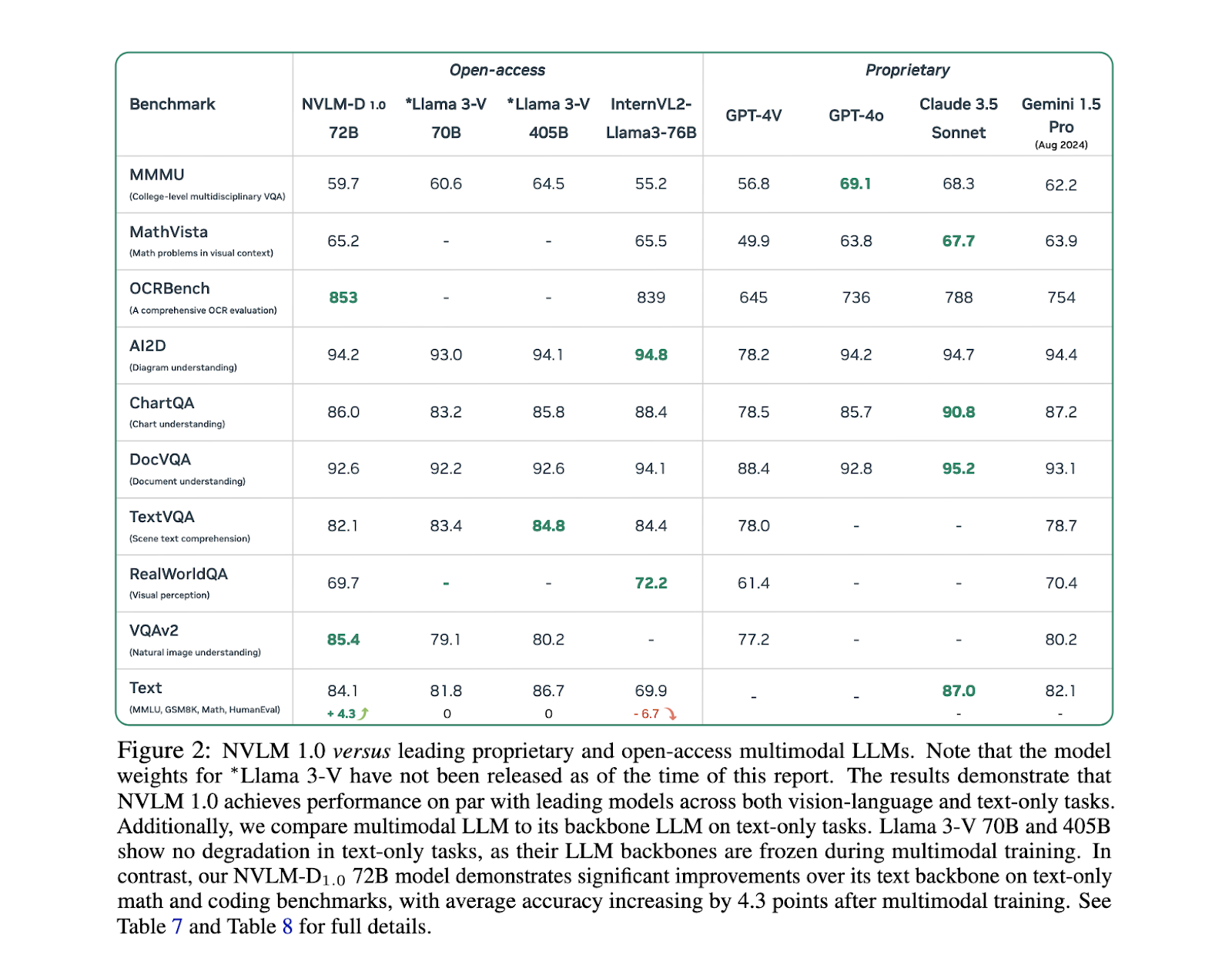
Concluindo, os modelos NVLM 1.0 desenvolvidos pelos pesquisadores da NVIDIA representam um avanço significativo em modelos multilíngues em larga escala. Ao combinar conjuntos de dados de texto de alta qualidade para treinamento multimodal e usar projetos de arquitetura inovadores, como ladrilhos adaptativos e ladrilhos de imagens de alta resolução, esses modelos abordam o desafio crítico do processamento de texto e imagens sem sacrificar o desempenho. A família de modelos NVLM não apenas supera os melhores sistemas proprietários em tarefas de linguagem visual, mas também mantém capacidades superiores de raciocínio somente em texto, marcando uma nova fronteira no desenvolvimento de sistemas de IA multimodais.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)


