
A conversão de texto em áudio revolucionou a forma como o conteúdo de áudio é criado, automatizando processos que exigiam experiência e tempo significativos. Esta tecnologia permite a conversão de informações de texto em som versátil e audível, agilizando os fluxos de trabalho na produção de áudio e nas indústrias criativas. A combinação de entrada de texto com saída de áudio realista abriu oportunidades em aplicações como narrativa de mídia mista, música e design de som.
Um dos principais desafios nos sistemas de texto para áudio é garantir que o áudio produzido corresponda fielmente às informações do texto. Os modelos atuais muitas vezes não conseguem capturar detalhes complexos, levando à substituição completa. Alguns resultados deixam de fora recursos importantes ou introduzem artefatos de áudio não intencionais. A falta de métodos padronizados para o desenvolvimento destes sistemas agrava o problema. Ao contrário dos modelos linguísticos, os sistemas de texto para áudio não beneficiam de técnicas robustas de alinhamento, como a aprendizagem reforçada através de feedback humano, o que deixa muito espaço para melhorias.
Os métodos anteriores de conversão de texto em áudio dependiam fortemente de modelos baseados em transmissão, como AudioLDM e Stable Audio Open. Embora esses modelos ofereçam qualidade decente, eles apresentam limitações. Sua dependência de múltiplas etapas de eliminação de ruído os torna mais caros e demorados. Além disso, a maioria dos modelos é treinada em conjuntos de dados proprietários, o que limita a sua acessibilidade e reprodutibilidade. Estas restrições dificultam o seu crescimento e a capacidade de lidar eficazmente com informações diversas e complexas.
Para enfrentar esses desafios, pesquisadores da Universidade de Tecnologia e Design de Cingapura (SUTD) e da NVIDIA apresentaram o TANGOFLUX, um modelo avançado de conversão de texto em fala. Este modelo foi projetado para eficiência e resultados de alta qualidade, alcançando melhorias significativas em relação aos métodos anteriores. TANGOFLUX usa a estrutura CLAP-Ranked Preference Optimization (CRPO) para otimizar a reprodução de áudio e garantir consistência com descrições de texto de forma iterativa. Sua arquitetura compacta e técnicas de treinamento inteligentes permitem um desempenho muito bom, exigindo poucos parâmetros.
TANGOFLUX combina métodos avançados para alcançar resultados de alta qualidade. Ele usa uma arquitetura híbrida que consiste em blocos Diffusion Transformer (DiT) e Multimodal Diffusion Transformer (MMDiT), permitindo lidar com produção de áudio variável no tempo. Ao contrário dos modelos tradicionais baseados em propagação, que dependem de múltiplas etapas de remoção de ruído, o TANGOFLUX usa uma estrutura de correspondência de fluxo para criar um caminho direto e otimizado do ruído até a saída. Este fluxo de trabalho otimizado minimiza as etapas computacionais necessárias para a geração de áudio de alta qualidade. Durante o treinamento, o sistema integra o status e o tempo do texto para garantir a precisão na captura das nuances dos comandos de entrada e da duração desejada da saída de áudio. O modelo CLAP avalia o alinhamento entre informações de áudio e texto gerando pares preferidos e otimizando-os iterativamente, um processo inspirado nas técnicas de alinhamento usadas em modelos de linguagem.
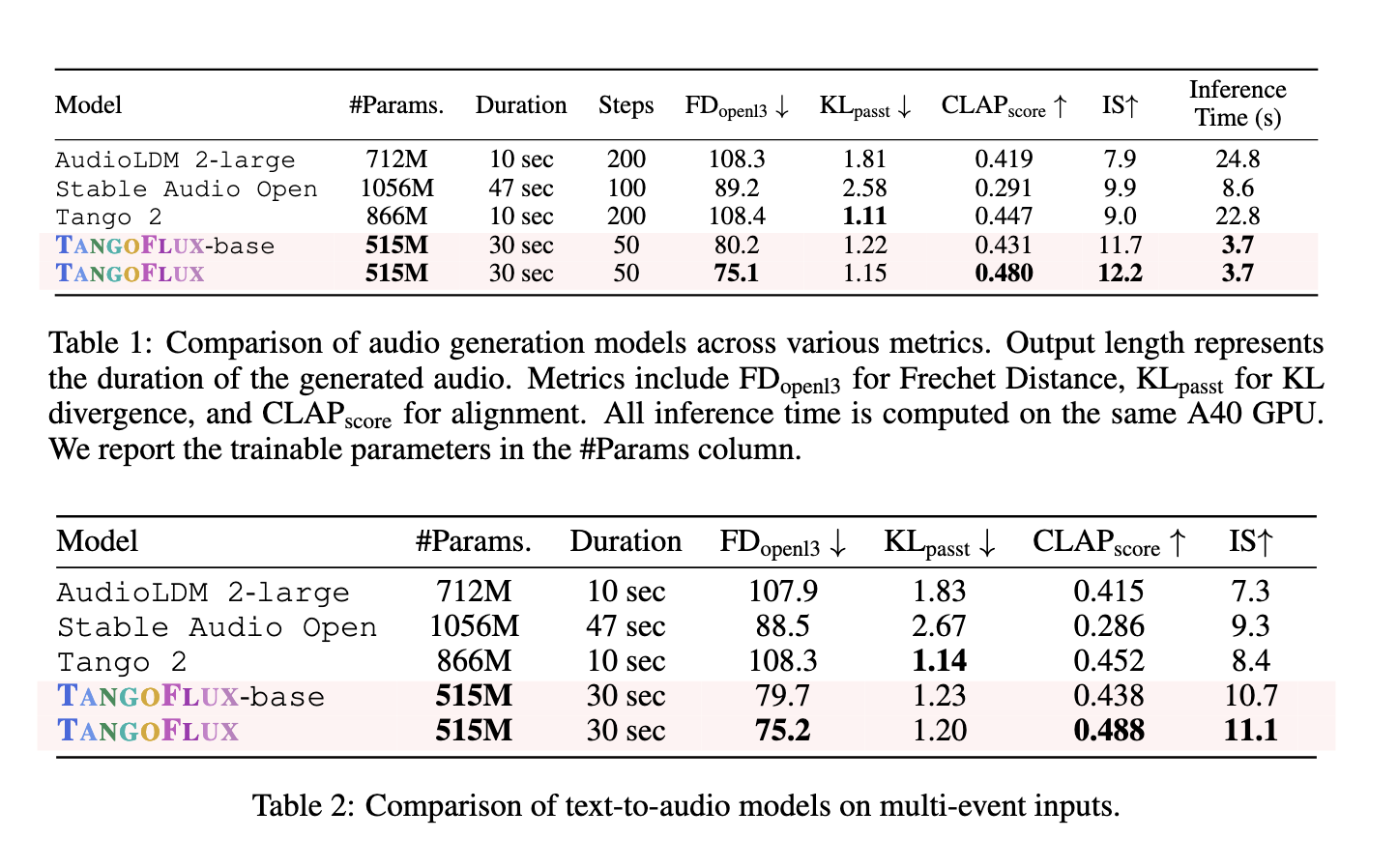
Em termos de desempenho, o TANGOFLUX supera seus antecessores em todas as múltiplas métricas. Produz 30 segundos de áudio em 3,7 segundos usando uma única GPU A40, mostrando uma eficiência impressionante. O modelo atinge uma pontuação CLAP de 0,48 e uma pontuação FD de 75,1, ambas indicando saída de áudio de alta qualidade e compatibilidade de texto. Comparado ao Stable Audio Open, que atinge uma pontuação CLAP de 0,29, o TANGOFLUX melhora significativamente a precisão do alinhamento. Em situações de múltiplos eventos, onde a informação inclui muitos eventos diferentes, o TANGOFLUX se destaca, demonstrando sua capacidade de capturar informações complexas e relações temporais de forma eficaz. A robustez do sistema também é destacada pela capacidade de manter o desempenho mesmo com etapas de amostragem reduzidas, recurso que melhora seu desempenho em aplicações em tempo real.
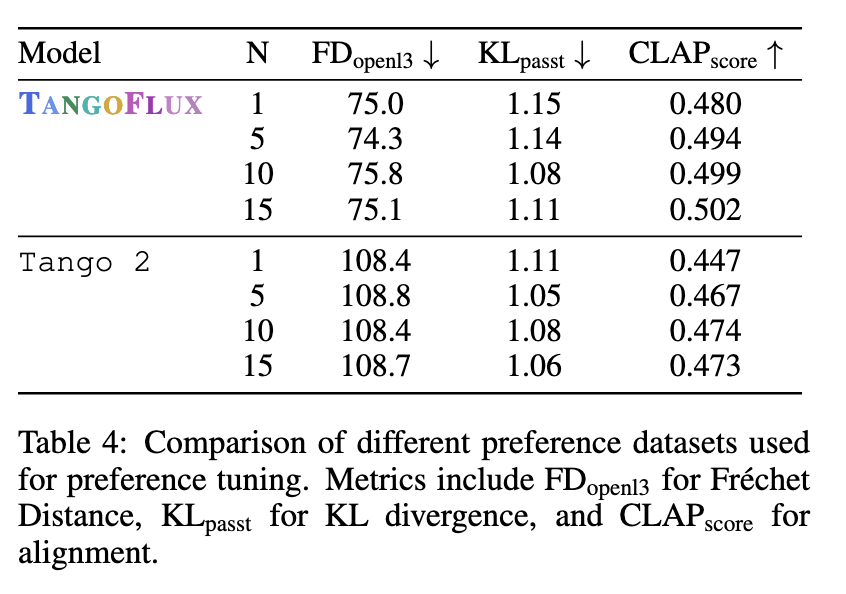
Os testes em humanos confirmam esses resultados, com o TANGOFLUX com pontuação alta em métricas independentes, como qualidade geral e compatibilidade rápida. Os comentaristas classificaram seus resultados como mais claros e alinhados do que outros modelos, como AudioLDM e Tango 2. Os pesquisadores também enfatizaram a importância da estrutura CRPO, que permitiu criar um conjunto de dados de preferência que supera outros, como BATON e Audio-Alpaca. O modelo evitou a degradação do desempenho frequentemente associada a conjuntos de dados off-line, gerando novos dados sintéticos durante cada sessão de treinamento.
A pesquisa aborda com sucesso limitações importantes em sistemas de texto para áudio, introduzindo o TANGOFLUX, que combina eficiência e alto desempenho. Seu uso inovador de fluxo otimizado e otimização preferencial estabelece a referência para desenvolvimentos futuros na área. Estas melhorias melhoram a qualidade e o alinhamento do som produzido e demonstram escalabilidade, tornando-o uma solução viável para adoção generalizada. O trabalho da SUTD e da NVIDIA representa um avanço significativo na tecnologia de texto para áudio, ampliando os limites do que pode ser alcançado neste domínio em rápida mudança.
Confira Papel, Repositório de códigode novo Modelo pré-treinado. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 PRÓXIMO WEBINAR GRATUITO DE IA (15 DE JANEIRO DE 2025): Aumente a precisão do LLM com dados artificiais e inteligência experimental–Participe deste webinar para obter insights práticos sobre como melhorar o desempenho e a precisão do modelo LLM e, ao mesmo tempo, proteger a privacidade dos dados.
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
🧵🧵 [Download] Avaliação do relatório de trauma do modelo de linguagem principal (estendido)


