
O uso de modelos linguísticos em larga escala (LLMs) revolucionou os aplicativos de inteligência artificial, permitindo avanços em tarefas de processamento de linguagem natural, como conversação de IA, geração de conteúdo e preenchimento automatizado de código. Muitas vezes com bilhões de parâmetros, esses modelos dependem de grandes recursos de memória para armazenar condições de computação intermediárias e grandes armazenamentos de valores-chave durante a inferência. O poder computacional desses modelos e seu tamanho crescente exigem novas soluções para gerenciar a memória sem sacrificar o desempenho.
Um desafio importante dos LLMs é a capacidade limitada de memória das GPUs. Se a memória da GPU não for suficiente para armazenar os dados necessários, os sistemas transferem partes da carga de trabalho para a memória da CPU, um processo conhecido como troca. Embora isto expanda a capacidade de memória, introduz atrasos devido à transferência de dados entre a CPU e a GPU, o que tem um impacto significativo na saída e no desempenho dos conceitos LLM. A compensação entre aumentar a capacidade de memória e manter a eficiência computacional continua a ser um gargalo significativo no desenvolvimento de implantações LLM em escala.
Soluções atuais como vLLM e FlexGen tentam resolver esse problema usando diversas técnicas de modulação. O vLLM usa uma estrutura de memória paginada para gerenciar o cache de valores-chave, melhorando até certo ponto a eficiência da memória. O FlexGen, por outro lado, usa um perfil offline para otimizar a alocação de memória entre GPU, CPU e recursos de disco. No entanto, esses métodos geralmente exigem atrasos mais previsíveis, atrasos computacionais e a incapacidade de se adaptar dinamicamente às mudanças na carga de trabalho, deixando espaço para melhorias adicionais no gerenciamento de memória.
Pesquisadores da UC Berkeley introduziram Pie, uma nova estrutura que visa superar os desafios dos problemas de memória em LLMs. Pie usa duas técnicas principais: troca dinâmica de funções e extensibilidade dinâmica. Usando padrões de acesso à memória previsíveis e recursos avançados de hardware, como o superchip NVIDIA GH200 Grace Hopper de alta largura de banda da NVLink, o Pie expande dinamicamente a memória sem aumentar a latência de computação. Esta abordagem inovadora permite que o sistema oculte atrasos na transferência de dados usando-os simultaneamente com cálculos de GPU, garantindo desempenho ideal.
O método Pie gira em torno de dois componentes importantes. O ajuste dinâmico de desempenho garante que as transferências de memória não atrasem os cálculos da GPU. Isso é conseguido buscando dados da memória da GPU antes de seu uso, usando a alta largura de banda das GPUs e CPUs modernas. Enquanto isso, a expansão dinâmica ajusta a quantidade de memória da CPU usada para troca com base nas condições do sistema em tempo real. Ao alocar memória dinamicamente conforme necessário, o Pie evita a subutilização ou superalocação que pode diminuir o desempenho. Esse design permite que o Pie integre perfeitamente a memória da CPU e da GPU, gerenciando efetivamente os recursos combinados como um pool de memória único e estendido para renderização LLM.
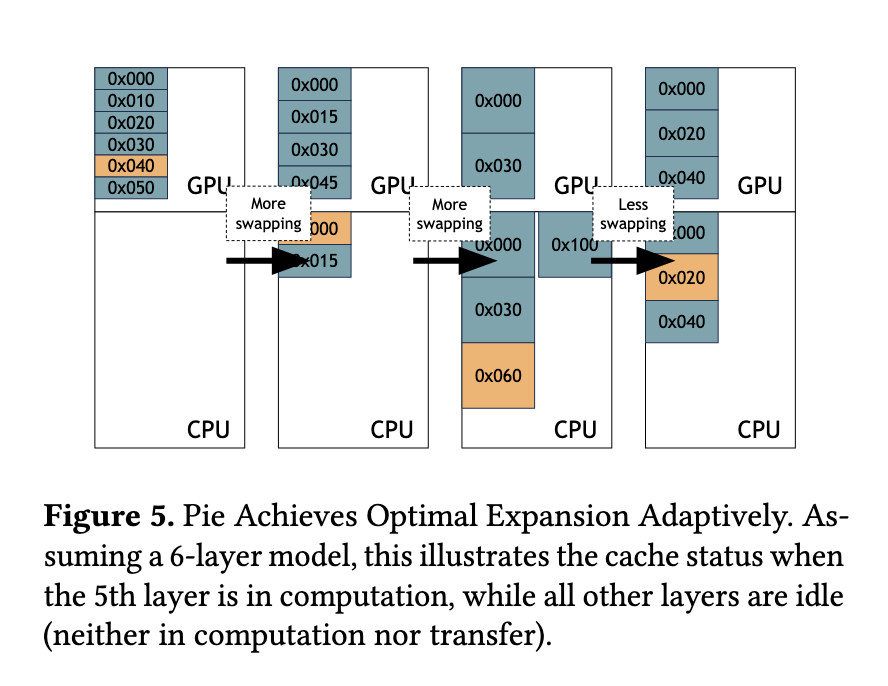
Os testes de benchmark do Pie mostraram melhorias significativas nas métricas de desempenho. Comparado ao vLLM, o Pie alcançou rendimento 1,9x maior e latência 2x menor em vários benchmarks. Além disso, o Pie reduziu o uso de memória da GPU em 1,67×, mantendo o mesmo desempenho. Contra o FlexGen, o Pie mostrou uma vantagem ainda maior, atingindo um rendimento 9,4x maior e uma latência significativamente reduzida, especialmente em cenários que envolvem dados maiores e cargas de trabalho mais complexas. Os testes usaram modelos de última geração, incluindo OPT-13B e OPT-30B, e rodaram em instâncias NVIDIA Grace Hopper com até 96 GB de memória HBM3. O sistema lidou com sucesso com cargas de trabalho do mundo real de conjuntos de dados como ShareGPT e Alpaca, provando sua praticidade.
A capacidade do Pie de se adaptar dinamicamente a diversas cargas de trabalho e ambientes de sistema o diferencia dos métodos existentes. O método de expansão dinâmica identifica rapidamente as configurações ideais de alocação de memória durante o tempo de execução, garantindo latência mínima e alto desempenho. Mesmo sob condições de memória restrita, a flexibilidade transparente de desempenho do Pie permite o uso eficiente dos recursos, evitando gargalos e mantendo a alta capacidade de resposta do sistema. Essa adaptabilidade ficou especialmente evidente durante situações de alta carga, onde o Pie foi dimensionado para atender à demanda sem comprometer o desempenho.

Pie representa um avanço significativo na infraestrutura de IA ao abordar o desafio de longa data das limitações de memória na compreensão do LLM. Sua capacidade de expandir perfeitamente a memória da GPU com latência mínima abre caminho para transferir modelos de linguagem grandes e complexos para o hardware existente. Esta inovação melhora a robustez das aplicações LLM e reduz as barreiras de custos associadas à atualização de hardware para atender às demandas do trabalho moderno de IA. À medida que os LLMs crescem em escala e uso, estruturas como Pie permitirão um uso eficiente e generalizado.
Veja o jornal. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
Por que os modelos de linguagem de IA ainda estão em risco: principais insights do relatório da Kili Technology sobre a vulnerabilidade de modelos de linguagem em grande escala [Read the full technical report here]
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
🐝🐝 Evento do LinkedIn, 'Uma plataforma, possibilidades multimodais', onde o CEO da Encord, Eric Landau, e o chefe de engenharia de produto, Justin Sharps, falarão sobre como estão reinventando o processo de desenvolvimento de dados para ajudar o modelo de suas equipes – a IA está mudando o jogo, rápido.
: uma abordagem integrada para reforçar a aprendizagem humana e o feedback de IA, resolvendo desafios de padronização e coleta de feedback")
 com decodificação inferencial")
