
Os sistemas de geração aumentada de recuperação (RAG) são essenciais para melhorar o desempenho de um modelo de linguagem, integrando fontes externas de informação ao seu desempenho. Esses sistemas usam mecanismos que dividem os documentos em seções pequenas e gerenciáveis, chamadas pedaços. Os programas RAG visam melhorar a precisão e a relevância contextual dos seus resultados, encontrando passagens contextualmente relevantes e enquadrando-as em modelos de linguagem generativa. O campo está em constante evolução para enfrentar os desafios relacionados à eficiência e robustez da segmentação de documentos.
Um grande desafio nos sistemas RAG é garantir que as estratégias de agrupamento equilibrem efetivamente a conservação do estado e a eficiência computacional. A segmentação tradicional de tamanho fixo divide os documentos em partes sequenciais semelhantes e muitas vezes separa o conteúdo semanticamente relacionado. Esta classificação limita o seu uso na recuperação de evidências e resposta a tarefas de produção. Embora outras técnicas, como a fragmentação semântica, estejam ganhando atenção por sua capacidade de agrupar estatisticamente informações semelhantes, suas vantagens sobre o tamanho fixo ainda precisam ser descobertas. Os pesquisadores questionaram se esses métodos podem justificar os recursos computacionais adicionais necessários.
A segmentação de tamanho fixo, embora computacionalmente simples, deve ser otimizada para manter a continuidade do contexto entre os segmentos do documento. Os pesquisadores propuseram técnicas de agrupamento semântico, como métodos baseados em pontos de interrupção e métodos baseados em cluster. A fragmentação semântica baseada em pontos de interrupção identifica pontos de diferenças semânticas significativas entre sentenças para formar segmentos coesos. Em contraste, o chunking baseado em concatenação usa algoritmos para agrupar sentenças matematicamente semelhantes, mesmo que não sejam consecutivas. Várias ferramentas da indústria têm utilizado estes métodos, mas os testes sistemáticos de eficiência ainda precisam ser mínimos.
Pesquisadores da Vectara, Inc. e da Universidade de Wisconsin-Madison testaram técnicas de agrupamento para determinar seu desempenho em tarefas de recuperação de documentos, recuperação de evidências e geração de respostas. Usando incorporações de frases e dados de conjuntos de dados de benchmark, eles compararam métodos de cluster semântico de tamanho fixo, baseados em pontos de interrupção e baseados em cluster. O estudo teve como objetivo medir a qualidade da recuperação, a precisão da geração de respostas e o custo computacional. Além disso, a equipe introduziu uma nova estrutura de testes para atender à necessidade de dados verdadeiros para testes em nível de bloco.
Os experimentos envolveram vários conjuntos de dados, incluindo documentos costurados e originais, para simular complexidades do mundo real. Os conjuntos de dados exportados contêm documentos curtos compilados artificialmente com grande diversidade de tópicos, enquanto os conjuntos de dados originais mantêm a sua estrutura natural. O estudo usou métricas posicionais e semânticas em chunking baseado em cluster, combinando similaridade de cosseno e proximidade espacial de sentença para melhorar a precisão do chunking. O chunking baseado em pontos de interrupção depende de restrições para determinar pontos de interrupção. O chunking de tamanho fixo combina frases sobrepostas entre pedaços consecutivos para reduzir a perda de informações. Métricas como pontuações F1 para recuperação de documentos e BERTScore para geração de respostas forneceram informações quantitativas sobre diferenças de desempenho.

Os resultados revelaram que o chunking semântico oferece benefícios extremos em casos de alta diversidade de tópicos. Por exemplo, o chunker semântico baseado em ponto de interrupção alcançou uma pontuação F1 de 81,89% no conjunto de dados Miracl, superando o chunking de tamanho fixo, que alcançou 69,45%. No entanto, estes benefícios também podem ser aplicados a outras profissões. Na recuperação de evidências, o processamento de tamanho fixo teve um desempenho comparável ou melhor em três dos cinco conjuntos de dados, indicando sua confiabilidade na captura de sentenças de evidências subjacentes. Para conjuntos de dados com estruturas naturais, como HotpotQA e MSMARCO, combinando tamanho fixo, obtiveram pontuações F1 de 90,59% e 93,58%, respectivamente, o que mostra sua robustez. Os métodos baseados em cluster lutam para manter a integridade do contexto em situações onde a informação espacial era importante.
Os resultados da geração de resposta destacaram pouca diferença entre os métodos de agrupamento. Chunkers de tamanho fixo e semânticos produziram resultados semelhantes, com chunkers semânticos mostrando pontuações BERTS ligeiramente mais altas em alguns casos. Por exemplo, o chunking baseado em cluster obteve pontuação de 0,50 no conjunto de dados Qasper, um pouco atrás da pontuação do chunking de tamanho fixo de 0,49. No entanto, esta diferença não foi significativa o suficiente para justificar o custo computacional adicional associado aos métodos semânticos.
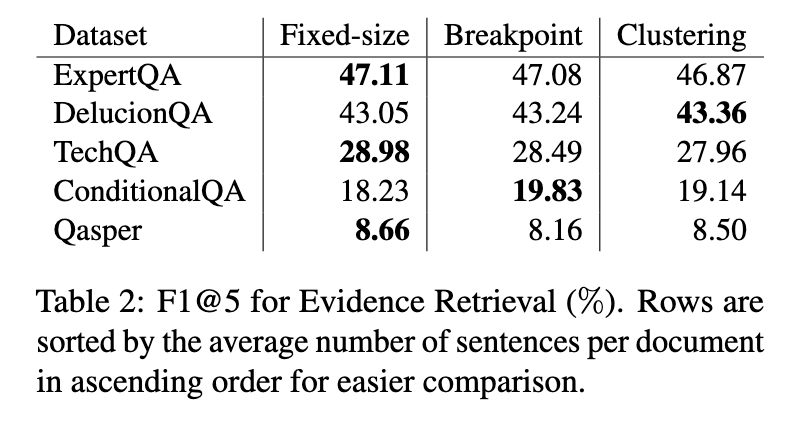
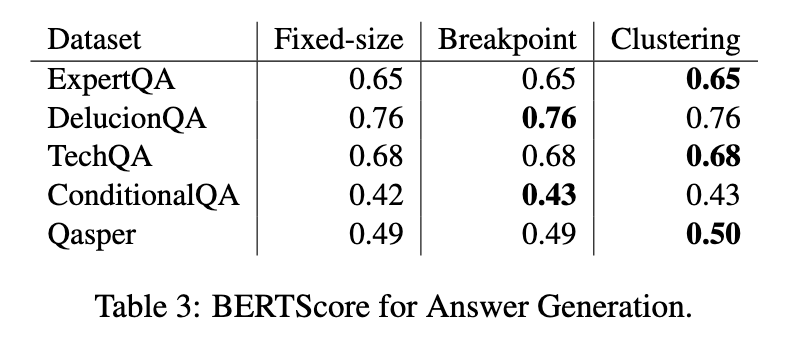
As conclusões enfatizam que a segmentação de tamanho fixo continua a ser uma opção viável para sistemas RAG, especialmente em aplicações do mundo real, onde os documentos muitas vezes incluem uma diversidade limitada de tópicos. Embora o chunking semântico às vezes mostre desempenho superior em situações muito específicas, suas demandas computacionais e resultados inconsistentes limitam seu uso generalizado. Os pesquisadores concluíram que o trabalho futuro deve se concentrar na otimização de técnicas de agrupamento para alcançar um melhor equilíbrio entre eficiência computacional e precisão de conteúdo. O estudo enfatiza a importância de avaliar os compromissos entre as estratégias de integração de sistemas RAG. Ao comparar sistematicamente estes métodos, os investigadores fornecem informações valiosas sobre os seus pontos fortes e limitações, orientando o desenvolvimento de técnicas de classificação de texto mais eficientes.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[FREE AI WEBINAR] Usando processamento inteligente de documentos e GenAI em serviços financeiros e transações imobiliárias– Da estrutura à produção

Sajjad Ansari se formou no último ano do IIT Kharagpur. Como entusiasta da tecnologia, ele examina as aplicações da IA com foco na compreensão do impacto das tecnologias de IA e suas implicações no mundo real. Seu objetivo é transmitir conceitos complexos de IA de maneira clara e acessível.
🐝🐝 Evento do LinkedIn, 'Uma plataforma, possibilidades multimodais', onde o CEO da Encord, Eric Landau, e o chefe de engenharia de produto, Justin Sharps, falarão sobre como estão reinventando o processo de desenvolvimento de dados para ajudar o modelo de suas equipes – a IA está mudando o jogo, rápido.


