
Os transformadores têm recebido atenção significativa devido às suas poderosas habilidades de compreender e gerar texto semelhante ao humano, tornando-os adequados para uma variedade de aplicações, como tradução de idiomas, resumo e geração de conteúdo criativo. Eles funcionam com base no método de atenção, que determina quanta atenção cada token em uma sequência deve ter em relação aos outros para fazer previsões informadas. Embora sejam muito promissores, o desafio reside no desenvolvimento destes modelos para lidar com grandes quantidades de dados de forma eficiente, sem custos computacionais excessivos.
Um grande desafio no desenvolvimento de modelos de transformadores é a sua ineficiência no tratamento de longas sequências de texto. À medida que o comprimento do contexto aumenta, os requisitos computacionais e de memória aumentam significativamente. Isso acontece porque cada token interage com todos os outros tokens, levando a uma complexidade quadrática que rapidamente sai do controle. Essa limitação impede o uso de transformadores em tarefas que exigem processos longos, como modelagem de linguagem e sumarização de documentos, onde armazenar e processar todas as sequências é importante para manter o contexto e a coerência. Portanto, são necessárias soluções para reduzir a carga computacional e, ao mesmo tempo, manter a eficiência do modelo.
Os métodos para lidar com esse problema incluem métodos de atenção múltipla, que limitam o número de interações entre tokens, e métodos de compactação de contexto que reduzem o comprimento da sequência, resumindo as informações anteriores. Esses métodos tentam reduzir o número de tokens considerados no caminho de atenção, mas geralmente fazem isso às custas do desempenho, pois a redução do contexto pode levar à perda de informações confidenciais. Esse compromisso entre eficiência e desempenho levou os pesquisadores a explorar novas maneiras de manter a alta precisão e, ao mesmo tempo, reduzir os requisitos computacionais e de memória.
Pesquisadores do Google Research introduziram um novo método chamado Atenção Seletiva, que visa melhorar a eficiência dos modelos de transformadores, permitindo que o modelo ignore tokens que não são mais relevantes. O método permite que cada token determine se outros tokens são necessários para cálculos futuros. Uma inovação importante reside na adição de um mecanismo de seleção ao processo de atenção padrão, reduzindo a atenção dada a tokens irrelevantes. Esta máquina não introduz novos parâmetros nem requer cálculos extensos, tornando-se uma solução simples e eficaz para atualização de transformadores.
O método de Atenção Seletiva é implementado usando uma matriz de máscara suave que determina a importância de cada token em tokens futuros. Os valores nesta matriz são acumulados em todos os tokens e depois subtraídos das pontuações de atenção antes que os pesos sejam combinados. Essa modificação garante que tokens sem importância recebam menos atenção, permitindo que o modelo os ignore em cálculos subsequentes. Ao fazer isso, os transformadores equipados com Atenção Seletiva podem operar com menos recursos, mantendo alto desempenho em todas as diferentes condições. Além disso, o tamanho do contexto pode ser reduzido removendo tokens desnecessários, reduzindo a memória e os custos computacionais durante suposições.
Os pesquisadores conduziram extensos experimentos para testar o desempenho da Atenção Seletiva em uma variedade de tarefas de processamento de linguagem natural. Os resultados mostraram que os transformadores de Atenção Seletiva alcançaram desempenho igual ou melhor que os transformadores convencionais, ao mesmo tempo que reduziram significativamente o uso de memória e o custo computacional. Por exemplo, para um modelo de transformador com 100 milhões de parâmetros, os requisitos de memória do módulo de atenção são reduzidos por fatores de 16, 25 e 47 com tamanhos de núcleo de 512, 1.024 e 2.048 tokens, respectivamente. O método proposto também superou os transformadores tradicionais no benchmark HellaSwag, alcançando uma melhoria de precisão de até 5% para modelos de grande porte. Esta redução significativa de memória se traduz diretamente em algoritmos mais eficientes, tornando possível a utilização desses modelos em ambientes com recursos limitados.
Análises mais aprofundadas mostraram que os transformadores equipados com Atenção Seletiva podem igualar o desempenho dos transformadores tradicionais com cabeças e parâmetros de atenção dupla. Esta descoberta é importante porque o método proposto permite modelos menores e mais eficientes sem comprometer a precisão. Por exemplo, no conjunto de validação da tarefa de modelagem da linguagem C4, os transformadores com Atenção Seletiva mantiveram pontuações de confusão comparáveis, exigindo 47 vezes menos memória em outras configurações. Este avanço abre caminho para o uso de modelos de linguagem de alto desempenho em ambientes com recursos computacionais limitados, como dispositivos móveis ou plataformas de computação de ponta.
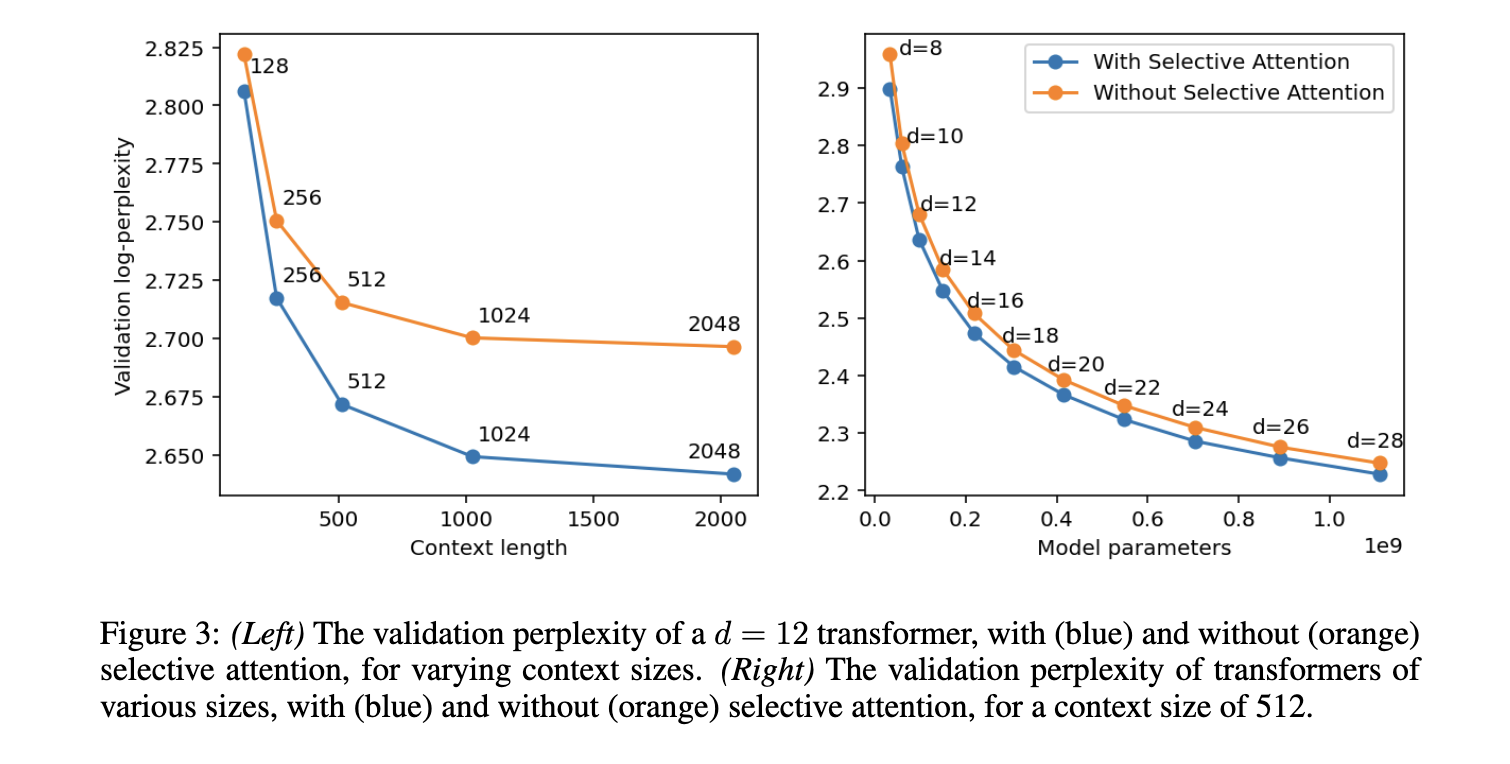
Concluindo, o desenvolvimento da Atenção Seletiva do Google Research aborda o principal desafio de alta memória e custo computacional em modelos de transformadores. O processo introduz uma modificação simples, mas poderosa, que melhora a eficiência dos transformadores sem adicionar complexidade. Ao permitir que o modelo se concentre em tokens importantes e ignore outros, a Atenção Seletiva melhora o desempenho e a eficiência, tornando-se um avanço significativo no processamento de linguagem natural. Os resultados alcançados desta forma têm potencial para aumentar o desempenho dos transformadores em uma ampla gama de tarefas e ambientes, contribuindo para o avanço das pesquisas e do uso da inteligência artificial.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Interessado em promover sua empresa, produto, serviço ou evento para mais de 1 milhão de desenvolvedores e pesquisadores de IA? Vamos trabalhar juntos!
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.

: uma abordagem de IA para derivar algoritmos para melhorar o desempenho e a fluência em modelos de linguagem")
