
Prever transcrições diretamente de sequências genéticas é um grande desafio na genômica microbiana, especialmente para muitas bactérias que não são sequenciadas ou requerem protocolos experimentais complexos, como o RNA-seq. A lacuna entre o conhecimento genômico e a compreensão funcional nos deixa sem conhecimento dos processos evolutivos microbianos, dos mecanismos de sobrevivência e das funções reguladoras dos genes. Isto deve ser direcionado para melhores estudos de ecossistemas microbianos, análise de materiais não-modelos e otimização da biologia sintética.
As técnicas atuais para o perfil do transcriptoma são principalmente métodos experimentais, como o sequenciamento de RNA, que são demorados, caros e muitas vezes inadequados para microrganismos com requisitos especiais de crescimento ou que vivem em condições críticas. Os modelos estatísticos para UTRs ou sequências longas de DNA são menos úteis porque não podem ser generalizados para todos os grupos taxonômicos. Além disso, estes métodos não levam em consideração as restrições evolutivas relacionadas à síntese de proteínas, o que os torna ainda menos úteis para prever os transcriptomas de espécies microbianas não-modelo e novas.
Pesquisadores do Instituto de Tecnologia de Pequim e da Universidade de Harvard propuseram o TXpredict, uma estrutura flexível para previsão do transcriptoma usando sequenciamento genético. O uso de um modelo de linguagem de proteínas pré-treinado (ESM2) extrai recursos preditivos de incorporações de proteínas enquanto incorpora princípios evolutivos. Esta inovação supera limitações de escalabilidade, generalização e eficiência computacional, mas ainda introduz novos recursos, como previsão de expressão gênica específica de condição. Devido à sua capacidade de analisar a diversidade de táxons microbianos, incluindo espécies não cultivadas, o TXpredict é um grande avanço na genômica microbiana.
O TXpredict é baseado em dados de transcriptoma de 22 espécies bacterianas e 10 espécies de arqueas, que incluem medições de expressão de 11,5 milhões de genes. O modelo usa uma arquitetura de codificador de transformador de autoatenção com vários cabeçotes para capturar relacionamentos de sequência complexos. As entradas incluem incorporações de proteínas do ESM2 e cálculos básicos de sequência. O treinamento do modelo usou validação cruzada de deixar um genoma de fora para generalização robusta. As previsões específicas da condição também foram ativadas pela integração da sequência 5′ UTR. A estrutura é computacionalmente eficiente, completando a previsão do transcriptoma de um genoma microbiano em 22 minutos em hardware padrão.
O TXpredict provou ser muito preciso e escalável no contexto da previsão do transcriptoma. Encontrou um coeficiente de correlação de Spearman de 0,53 para organismos bacterianos e 0,42 para archaea e mostrou resultados significativos para certas espécies como B. hinzii (0,64), B. thetaiotaomicron (0,62) e C. beijerinckii (0,62). As previsões estenderam-se a mais 900 genomas representando 276 genes e 3,11 milhões de genes, incluindo um grande número de táxons anteriormente não caracterizados. No contexto de texto específico do caso, o modelo mostrou uma correlação média de 0,52 em 4,6 mil casos de teste, capturando assim padrões regulatórios dinâmicos. Esses resultados mostram que a estrutura é capaz de fornecer previsões precisas sobre uma ampla gama de subespécies, mantendo a eficiência computacional.
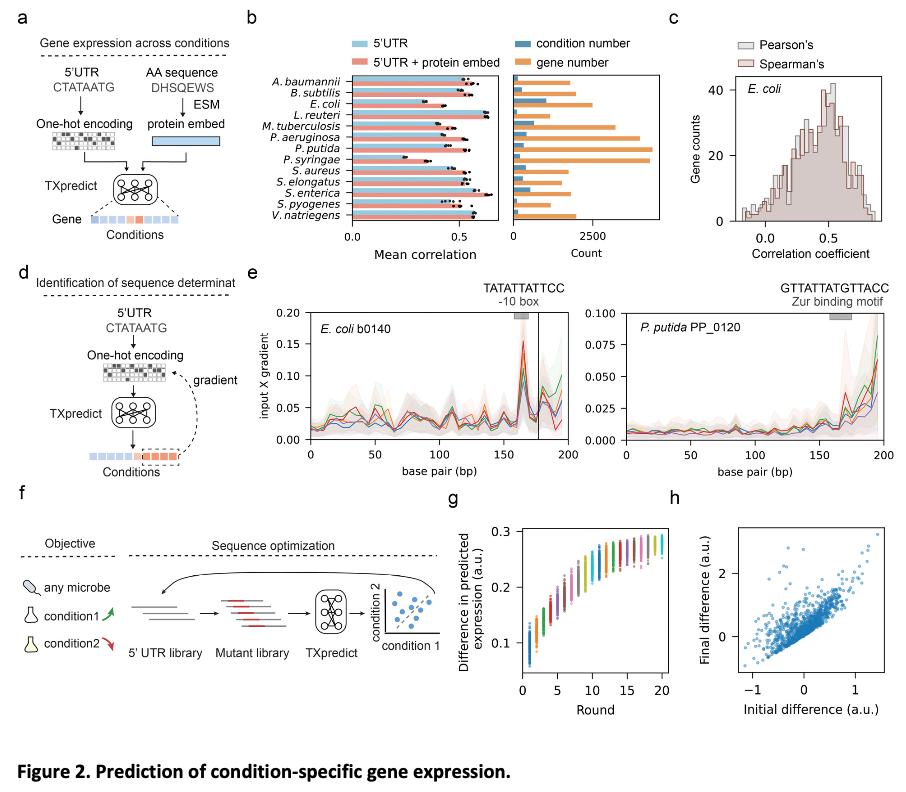
O TXpredict aborda desafios críticos na genômica microbiana, preenchendo a lacuna entre a sequência do genoma e a previsão do transcriptoma. Esta abordagem, através da integração de incorporação de proteínas, restrições evolutivas e características específicas cruzadas, fornece uma solução simples, precisa e eficiente para a taxonomia de diversas bactérias. Esta técnica não só produz informações valiosas sobre o controle genético e a adaptação, mas também tem o potencial de avançar na biologia sintética e na pesquisa ambiental. Apesar de algumas limitações, incluindo a dependência de conjuntos de dados de RNA-seq pré-existentes e a exclusão de segmentos de RNA não codificantes, o TXpredict estabelece uma estrutura básica para novas aplicações no campo da pesquisa microbiana.
Confira eu Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 PRÓXIMO WEBINAR GRATUITO DE IA (15 DE JANEIRO DE 2025): Aumente a precisão do LLM com dados artificiais e inteligência experimental–Participe deste webinar para obter insights práticos sobre como melhorar o desempenho e a precisão do modelo LLM e, ao mesmo tempo, proteger a privacidade dos dados.
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
🧵🧵 [ FREE AI Webinar] Participe deste webinar para obter insights práticos sobre como melhorar o desempenho e a precisão do modelo LLM e, ao mesmo tempo, proteger a privacidade dos dados. (Promovido)


