
Os cursos de linguística (LLMs) revolucionaram o campo da inteligência artificial ao realizar várias tarefas em diferentes domínios. Espera-se que esses modelos funcionem perfeitamente em vários idiomas, resolvendo problemas complexos e garantindo a segurança. Contudo, o desafio reside em manter a segurança sem comprometer o desempenho, especialmente em ambientes multilingues. À medida que a tecnologia de IA se torna mais global, é importante abordar as preocupações de segurança que surgem quando modelos altamente treinados em inglês são usados em diferentes idiomas e contextos culturais.
Uma questão fundamental diz respeito à medição do desempenho e da segurança nos LLMs. As preocupações de segurança surgem quando os modelos produzem resultados tendenciosos ou perigosos, especialmente para linguagens com dados de treinamento limitados. Normalmente, as abordagens para isso envolvem modelos de ajuste fino para conjuntos de dados mistos, clustering de uso geral e funções de segurança. No entanto, estes métodos podem levar a compensações indesejadas. Em muitos casos, o aumento das medidas de segurança para os LLMs pode ter um impacto negativo na sua capacidade de desempenhar bem as tarefas rotineiras. O desafio, portanto, é desenvolver um método que melhore a segurança e o desempenho em LLMs multilíngues sem exigir grandes quantidades de dados específicos de tarefas.
Os métodos atuais utilizados para medir estes objetivos baseiam-se frequentemente em técnicas de fusão de dados. Isso envolve a criação de um modelo único, treinando-o em vários conjuntos de dados de várias tarefas e linguagens. Embora esses métodos ajudem a atingir um certo nível de capacidade multitarefa, eles podem levar a preocupações menos voltadas à segurança em outros idiomas além do inglês. Além disso, a complexidade de gerenciar múltiplas tarefas ao mesmo tempo muitas vezes limita a capacidade do modelo de ter um bom desempenho em qualquer uma delas. A falta de atenção específica a cada tarefa e linguagem limita a capacidade do modelo de abordar eficazmente a segurança e o desempenho geral.
Para superar essas limitações, os pesquisadores da Cohere AI introduziram uma nova abordagem baseada na integração de modelos. Em vez de confiar no método tradicional de mistura de dados, onde um único modelo é treinado em múltiplas tarefas e linguagens, os pesquisadores propõem combinar diferentes modelos que são ajustados independentemente para tarefas e linguagens específicas. Essa abordagem permite um melhor conhecimento de cada modelo antes de combiná-los em um sistema unificado. Ao fazer isso, os modelos mantêm seus recursos exclusivos, proporcionando maior segurança e funcionalidade comum em diferentes idiomas.
O processo de integração é feito usando várias técnicas. O principal método apresentado pelos pesquisadores é a Interpolação Linear Esférica (SLERP), que permite uma transição suave entre diferentes modelos combinando seus pesos em um caminho circular. Este processo garante que as características únicas de cada modelo sejam preservadas, permitindo que o modelo combinado lide com uma variedade de tarefas sem comprometer a segurança ou o desempenho. Outra abordagem, TIES (Estratégia de Eliminação de Interferência de Tarefas), concentra-se na resolução de conflitos entre modelos específicos de tarefas bem estruturados, ajustando os parâmetros do modelo para um melhor alinhamento. As técnicas de integração incluem integração linear e DARE-TIES, que melhoram ainda mais a robustez do modelo final, abordando problemas de perturbação e garantindo que os parâmetros do modelo contribuam positivamente para o desempenho.
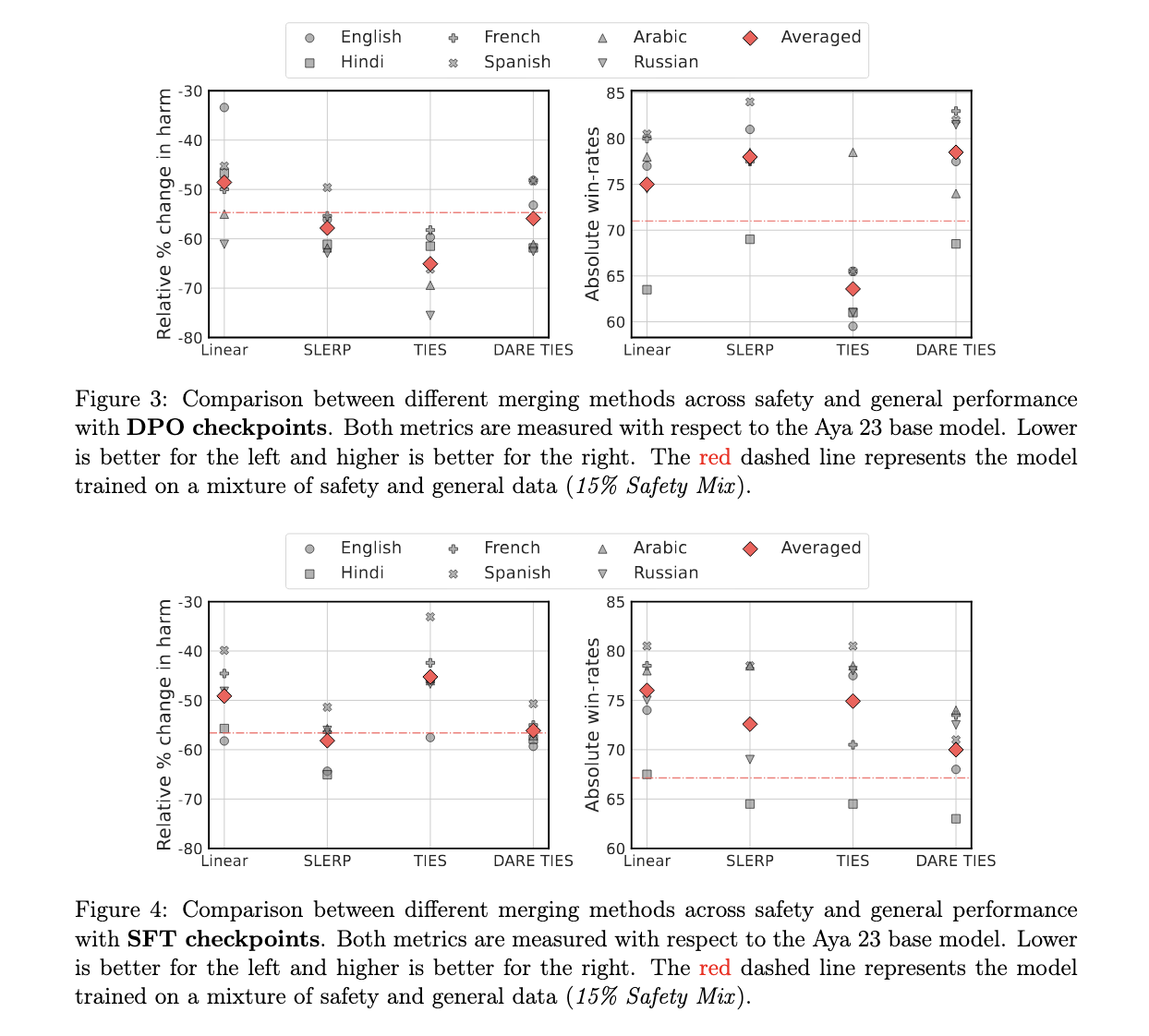
Os resultados deste estudo mostram uma clara melhoria no desempenho geral e na segurança. Por exemplo, o agrupamento SLERP alcançou uma melhoria impressionante de 7% no desempenho geral e uma redução de 3,1% nos efeitos nocivos em comparação com os métodos tradicionais de agrupamento de dados. Por outro lado, a incorporação do TIES trouxe uma redução impressionante de 10,4% nos efeitos adversos, embora tenha reduzido ligeiramente o desempenho geral em 7,4%. Esses números mostram que a integração de modelos é mais eficaz do que a integração de dados na medição de segurança e desempenho. Além disso, quando os modelos foram ajustados para cada idioma e combinados, os pesquisadores observaram uma redução de até 6,6% nos resultados perigosos e uma melhoria de 3,8% nos benchmarks padrão, comprovando ainda mais o desempenho de um modelo específico de idioma para combinar treinamento em modelo multilíngue.
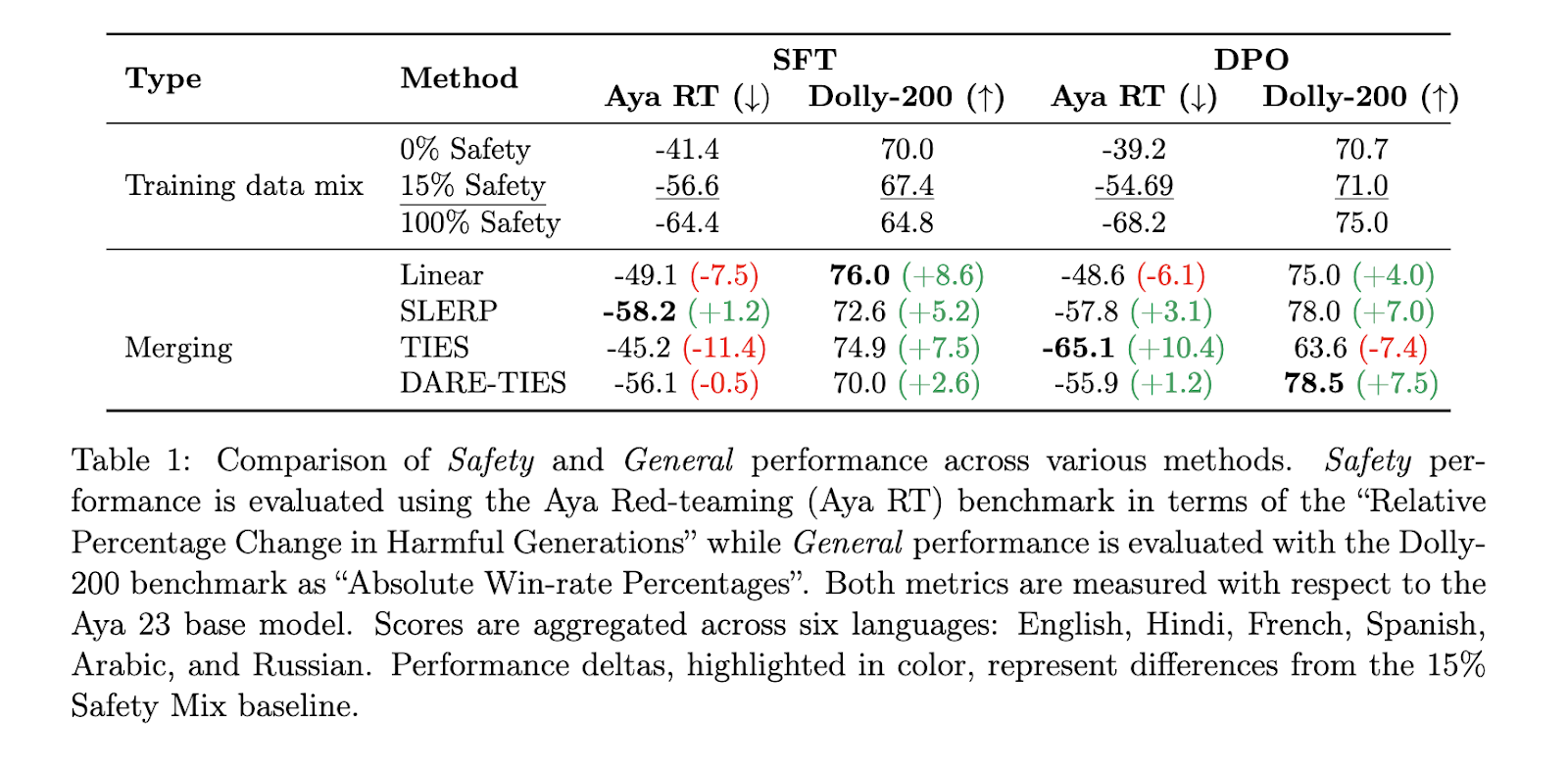
A melhoria de desempenho foi particularmente notável em outros idiomas, com o russo apresentando a maior redução de gerações perigosas (até 15%) usando a integração TIES. O espanhol, por outro lado, apresentou uma melhoria de 10% no desempenho geral nas medidas SLERP e TIES. No entanto, nem todas as línguas beneficiam igualmente. Os modelos ingleses, por exemplo, mostraram uma diminuição no desempenho de segurança quando agrupados, destacando a variabilidade dos resultados com base nos dados de treinamento subjacentes e nas técnicas de agrupamento.
A pesquisa fornece uma estrutura abrangente para a construção de LLMs multilíngues seguros e eficazes. Ao combinar modelos ajustados para segurança e desempenho em tarefas e linguagens específicas, os pesquisadores da Cohere AI demonstraram uma abordagem altamente eficiente e escalável para o desenvolvimento de LLMs. Esta abordagem reduz a necessidade de grandes quantidades de dados de treinamento e permite um melhor alinhamento dos princípios de segurança entre idiomas, o que é muito necessário no ambiente de IA atual.
Em conclusão, a combinação de modelos representa um passo promissor na abordagem dos desafios de medição da segurança e proteção em LLMs, especialmente em ambientes multilingues. Este método melhora muito a capacidade dos LLMs de fornecer resultados seguros e de alta qualidade, especialmente quando usados em linguagens de poucos recursos. À medida que a IA avança, técnicas como a integração de modelos podem ser ferramentas importantes para garantir que os sistemas de IA sejam robustos e seguros numa variedade de contextos linguísticos e culturais.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] Melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (avançado)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️
 de código aberto projetada para alinhamento estrutural de elementos visuais e de texto incorporados")

