
A pesquisa de aprendizado de máquina evoluiu para modelos que podem projetar e descobrir automaticamente estruturas de dados para tarefas computacionais específicas, como a pesquisa do vizinho mais próximo (NN). Esta mudança na metodologia permite que os modelos aprendam não só a estrutura dos dados, mas também como otimizar as respostas às consultas, reduzindo os requisitos de armazenamento e o tempo de computação. A aprendizagem automática vai agora além do processamento de dados tradicional, abordando melhorias estruturais nos dados para criar estruturas dinâmicas que tiram partido dos padrões de distribuição e das características dos dados. Essa adaptabilidade é importante em todos os campos onde a recuperação de dados é importante, especialmente em domínios onde a velocidade e o armazenamento são restritos.
Projetar estruturas de dados eficientes continua sendo um grande desafio. As estruturas existentes, como árvores de busca binária e árvores kd, são projetadas tendo em mente os piores cenários. Embora isso garanta um desempenho confiável, também significa que eles não estão aproveitando o poder dos padrões nos dados para fazer perguntas mais eficientes. Como resultado, muitas estruturas de dados tradicionais não podem usar recursos exclusivos para cada conjunto de dados, resultando em menor desempenho para consultas que podem se beneficiar de estruturas flexíveis e personalizadas. Como resultado, há um interesse crescente em estruturas de dados que possam se adaptar a distribuições de dados específicas, oferecendo tempos de consulta mais rápidos e uso reduzido de memória adaptado a aplicações específicas.
Os métodos desenvolvidos para melhorar a eficiência da estrutura de dados concentram-se principalmente em algoritmos avançados, onde as estruturas de dados padrão são modificadas com previsões de aprendizado de máquina para acelerar as consultas. No entanto, mesmo estes métodos são limitados pela sua dependência de construções predefinidas que podem necessitar de ser adequadamente ajustadas ao conjunto de dados. Por exemplo, embora as árvores com aprendizagem aprimorada e o hashing sensível à localização melhorem a eficiência da pesquisa ao combinar princípios algorítmicos com modelos preditivos, eles são substituídos por estruturas definidas por humanos. Estes modelos ainda dependem de estruturas de dados originais, limitando a sua capacidade de adaptação automática a distribuições de dados únicas.
Pesquisadores da Universite de Montreal Mila, HEC Montreal Mila, Microsoft Research, University of Southern California e Stanford University propuseram uma nova estrutura que usa aprendizado de máquina para descobrir de forma independente estruturas de dados adequadas para tarefas específicas. Esta estrutura consiste em duas partes principais:
- Uma rede de processamento de dados que organiza dados brutos em estruturas avançadas
- Uma rede de execução de consultas que navega efetivamente em dados estruturados para recuperação
Ambas as redes são treinadas juntas de ponta a ponta, permitindo que se adaptem a diversas distribuições de dados. Ao eliminar a necessidade de estruturas predefinidas, a estrutura executa automaticamente otimizações avançadas que superam os métodos convencionais para todos os tipos de dados e tipos de consulta, incluindo pesquisa de NN e estimativa de frequência em dados distribuídos.
A metodologia envolve um modelo conversor de 8 camadas, onde uma rede de processamento de dados mede as características do conjunto de dados, organizando-as em uma configuração eficiente. Esta medida é refinada com uma função de filtro separável, que ordena os dados com base na sua classificação. Enquanto isso, a rede de execução de consultas, composta por vários modelos independentes, aprende a estratégia de pesquisa ideal para recuperar pontos de dados específicos com base em padrões históricos de consultas. Este treinamento colaborativo personaliza a estrutura de dados e melhora a precisão das consultas. Por exemplo, o modelo mostra alta precisão na classificação correta de 99,5% dos dados de pesquisa NN 1D, apesar de exigir uma classificação precisa. Esse nível de precisão é um exemplo de como as arquiteturas orientadas a dados, uma vez projetadas, podem melhorar a eficiência do armazenamento e a velocidade de recuperação.
A estrutura passou em todas as diversas condições de teste do experimento. Na busca NN 1D, o modelo apresentou taxas de precisão mais altas do que os métodos convencionais de busca binária. Por exemplo, o modelo é muito bem-sucedido em pesquisa binária ao gerar consultas próximas ao alvo quando testado em dados com distribuição uniforme maior que (-1, 1) com 100 características e limitado a sete observações. Para casos de alta dimensão, como hiperesferas de 30 dimensões, o modelo utilizou aproximações semelhantes ao hashing sensível à localização, que obteve resultados semelhantes aos de algoritmos especiais. Notavelmente, em uma configuração desafiadora onde a precisão da consulta deve ser alcançada em um espaço limitado, o modelo usa efetivamente mais espaço, trocando memória pela precisão da consulta. A precisão do modelo aumentou quando foram fornecidos sete vetores adicionais para armazenar, indicando adaptação a várias restrições espaciais.
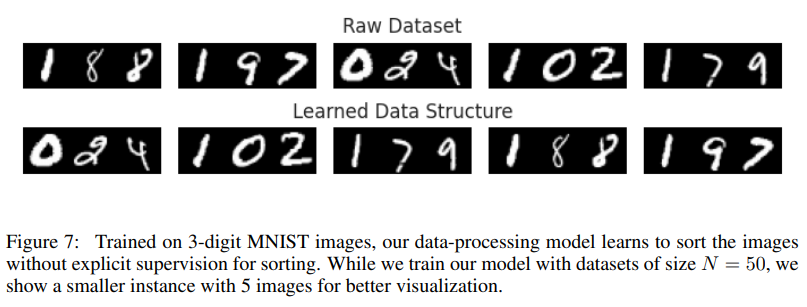
O estudo revela várias conclusões importantes que demonstram as capacidades e a inovação da estrutura:
- Detecção automática de layout: O modelo aprende de forma independente configurações eficientes de estruturas de dados, eliminando a necessidade de estruturas predefinidas e projetadas por humanos.
- Alta precisão em configurações de dados simples e complexos: Alcançou 99,5% de precisão na pesquisa sistemática de NN 1D e navegou com sucesso em dados uniformes e de alta dimensão com supervisão mínima.
- Uso eficiente de espaço extra para maior precisão: O framework apresentou um claro aumento de desempenho à medida que mais memória foi alocada, mostrando flexibilidade em situações estressantes.
- Ampla funcionalidade além da pesquisa NN: A flexibilidade do framework também foi destacada em tarefas de estimativa de frequência, onde superou os modelos de esboço CountMin em dados com distribuição Zipfian, mostrando potencial para algumas aplicações exigentes.

Concluindo, este estudo mostra um passo promissor em direção ao futuro da descoberta de estruturas de dados orientada por aprendizado de máquina. Usando treinamento adaptativo de ponta a ponta, esta estrutura aborda com eficácia os desafios de armazenamento e consulta que as estruturas de dados tradicionais enfrentam, especialmente quando operam dentro das restrições dos dados do mundo real. Esta abordagem melhora a velocidade e a precisão da recuperação de dados e abre caminhos para a descoberta automática no processamento de dados, marcando um grande avanço no uso do aprendizado de máquina na otimização de edifícios.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Sponsorship Opportunity with us] Promova sua pesquisa/produto/webinar para mais de 1 milhão de leitores mensais e mais de 500 mil membros da comunidade
Sana Hassan, estagiária de consultoria na Marktechpost e estudante de pós-graduação dupla no IIT Madras, é apaixonada pelo uso de tecnologia e IA para enfrentar desafios do mundo real. Com um profundo interesse em resolver problemas do mundo real, ele traz uma nova perspectiva para a interseção entre IA e soluções da vida real.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


