
O processamento de linguagem natural (PNL) teve um rápido desenvolvimento, com modelos linguísticos de grande escala (LLMs) liderando o caminho na mudança na forma como o texto é gerado e interpretado. Esses modelos demonstraram uma capacidade incrível de criar respostas suaves e consistentes em uma variedade de aplicações, desde chatbots até ferramentas de resumo. No entanto, a aplicação destes modelos a domínios sensíveis, como finanças, cuidados de saúde e direito, destacou a importância de garantir que as respostas sejam consistentes, precisas e contextualmente fiáveis. A desinformação ou alegações não fundamentadas podem ter implicações graves para esses domínios, tornando importante avaliar e melhorar a fiabilidade dos resultados do LLM quando aplicável em contextos específicos.
Um grande problema no texto gerado pelo LLM é o fenômeno da “ilusão”, onde o modelo produz conteúdo que contradiz o contexto dado ou apresenta fatos faltantes. Esta questão pode ser dividida em dois tipos: alucinações verdadeiras, quando o que é produzido se desvia da informação estabelecida, e alucinações honestas, onde a resposta produzida não corresponde ao contexto dado. Apesar da investigação e desenvolvimento contínuos neste campo, continua a existir uma lacuna significativa nas métricas que avaliam eficazmente até que ponto os LLM mantêm a fidelidade ao contexto, especialmente em situações complexas em que o contexto pode incluir informações contraditórias ou incompletas. Este desafio precisa ser enfrentado para evitar a erosão da confiança do usuário em aplicações do mundo real.
Os métodos atuais de avaliação de LLMs concentram-se na verificação de factos, mas muitas vezes necessitam de melhorias em termos de testes de fiabilidade contextual. Esses benchmarks testam a precisão em relação a fatos conhecidos ou ao conhecimento mundial, mas não medem a relevância das respostas geradas para o contexto, especialmente em situações de recuperação ruidosas, onde o contexto pode ser confuso ou contraditório. Além disso, mesmo a combinação de informações externas usando geração aumentada de recuperação (RAG) não garante a retenção de contexto. Por exemplo, quando múltiplas categorias relevantes são recuperadas, o modelo pode omitir informações críticas ou apresentar evidências conflitantes. Essa complexidade deve ser totalmente capturada nas atuais medidas de avaliação de sonhos, o que torna desafiadora a avaliação do desempenho do LLM em situações tão complexas.
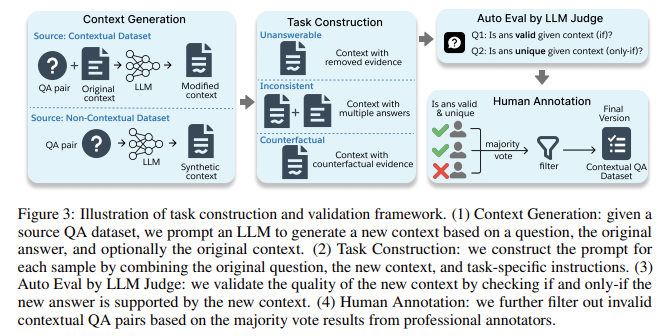
Pesquisadores da Salesforce AI Research lançaram um novo benchmark chamado FéEvalprojetado especificamente para avaliar a confiabilidade do contexto dos LLMs. FaithEval aborda esse problema identificando três condições distintas: condições irrespondíveis, condições inconsistentes e condições falsas. O benchmark inclui um conjunto diversificado de problemas de alta qualidade de 4,9K, validados por meio de uma estrutura robusta de quatro estágios e uma estrutura de validação que inclui testes automatizados baseados em LLM e validação humana. Ao simular situações do mundo real onde o contexto retornado pode carecer de informações necessárias ou conter informações conflitantes ou fabricadas, o FaithEval fornece uma avaliação abrangente de como os LLMs podem adaptar suas respostas ao contexto.
FaithEval usa uma estrutura de validação rigorosa em quatro estágios, que garante que cada amostra seja criada e verificada quanto à qualidade e consistência. O conjunto de dados inclui três funções principais: casos não respondidos, casos fixos e casos falsos. Por exemplo, numa tarefa de contexto sem resposta, o contexto pode incluir informações relevantes mas vagas para responder a uma pergunta, tornando difícil para os modelos identificar quando evitar gerar uma resposta. Da mesma forma, em uma tarefa de contexto inconsistente, vários documentos fornecem informações conflitantes sobre o mesmo tópico, e o modelo deve determinar quais informações são mais confiáveis ou se há conflito. O trabalho de conteúdo contrafactual inclui declarações que contradizem o senso comum ou os fatos, exigindo modelos para navegar entre evidências conflitantes e o conhecimento comum. Este benchmark testa a capacidade dos LLMs de lidar com 4,9 mil pares de controle de qualidade, incluindo tarefas que simulam situações em que os modelos devem permanecer confiáveis apesar de distúrbios e condições adversas.
Os resultados da pesquisa revelam que mesmo modelos de última geração, como o GPT-4o e o Llama-3-70B, lutam para manter a confiabilidade em situações complexas. Por exemplo, o GPT-4o, que alcançou uma alta precisão de 96,3% nos benchmarks verdadeiros padrão, apresentou uma queda significativa no desempenho, caindo para 47,5% de precisão quando o contexto apresentava evidências falsas. Da mesma forma, Phi-3-medium-128k-instruct, que teve um bom desempenho em condições normais com 76,8% de precisão, teve dificuldades em condições sem resposta, onde alcançou apenas 7,4% de precisão. Esta descoberta destaca que modelos maiores ou com mais parâmetros não garantem melhor aderência ao contexto, tornando mais importante melhorar as estruturas de teste e desenvolver melhores modelos sensíveis ao contexto.
O benchmark FaithEval enfatiza vários insights importantes das avaliações de LLMs, fornecendo conclusões importantes:
- Desempenho diminuído em veículos opostos: Mesmo os modelos mais eficientes sofreram uma queda significativa no desempenho quando o contexto era conflitante ou inconsistente.
- O tamanho não se ajusta ao desempenho: Modelos maiores, como o Llama-3-70B, não tiveram desempenho consistentemente melhor do que os menores, indicando que a contagem de parâmetros por si só não é uma medida de confiabilidade.
- É necessário procurar benchmarks aprimorados: As classificações atuais são inadequadas para avaliar a confiabilidade em situações que envolvem informações conflitantes ou estabelecidas, que exigem testes rigorosos.

Em conclusão, o benchmark FaithEval fornece uma contribuição oportuna para o desenvolvimento contínuo de LLMs, introduzindo uma estrutura robusta para avaliação de confiabilidade contextual. Este estudo destaca as limitações dos benchmarks existentes e apela a um maior desenvolvimento para garantir que futuros LLMs possam produzir resultados contextualmente fiáveis e fiáveis em situações do mundo real. À medida que os LLMs continuam a evoluir, tais benchmarks serão úteis para ampliar os limites do que esses modelos podem alcançar e garantir que permaneçam confiáveis em aplicações críticas.
Confira Papel e GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Interessado em promover sua empresa, produto, serviço ou evento para mais de 1 milhão de desenvolvedores e pesquisadores de IA? Vamos trabalhar juntos!
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.
")

