
FineWeb2 melhora significativamente os conjuntos de dados de treinamento multilíngue, cobrindo mais de 1.000 idiomas com dados de alta qualidade. O conjunto de dados usa cerca de 8 terabytes de dados de texto compactados e contém cerca de 3 bilhões de palavras, retiradas de 96 resumos do CommonCrawl entre 2013 e 2024. Processado usando uma biblioteca de dados, o FineWeb2 apresenta desempenho muito alto em comparação com conjuntos de dados estabelecidos como CC-100, mC4, CulturaX e HPLT em nove idiomas diferentes. A configuração e o teste da ablação estão neste repositório do GitHub.
Os pesquisadores da comunidade Huggingface lançaram o FineWeb-C, um projeto colaborativo voltado para a comunidade que estende o FineWeb2 para criar anotações de conteúdo educacional de alta qualidade em centenas de idiomas. O projeto permite que os membros da comunidade avaliem o valor educativo do conteúdo da web e identifiquem aspectos problemáticos através da plataforma Argilla. Idiomas com até 1.000 anotações são elegíveis para inclusão no conjunto de dados. Este processo de anotação tem dois objetivos: identificar conteúdo acadêmico de alta qualidade e melhorar o desenvolvimento do LLM em todos os idiomas.
Os 318 membros da comunidade Hugging Face postaram 32.863 anotações, contribuindo para o desenvolvimento de LLMs de alta qualidade em todos os idiomas sub-representados. FineWeb-Edu é um conjunto de dados construído sobre o conjunto de dados FineWeb original e usa um classificador de qualidade educacional treinado em anotações LLama3-70B-Order para identificar e armazenar o conteúdo mais educacional. Essa abordagem provou ser bem-sucedida, superando o FineWeb em benchmarks populares e, ao mesmo tempo, reduzindo a quantidade de dados necessários para treinar LLMs ativos. Este projeto visa estender as capacidades do FineWeb-Edu a todos os idiomas do mundo, coletando anotações da comunidade para treinar classificadores de qualidade educacional específicos de cada idioma.
O projeto prioriza anotações geradas por humanos em vez de anotações baseadas em LLM, especialmente em linguagens de poucos recursos onde o desempenho do LLM não pode ser verificado de forma confiável. Esta abordagem orientada para a comunidade é consistente com o modelo colaborativo da Wikipédia, que enfatiza o acesso aberto e a democratização da tecnologia de IA. Os doadores estão a aderir a um movimento mais amplo para quebrar as barreiras linguísticas no desenvolvimento da IA, uma vez que as empresas comerciais muitas vezes se concentram em línguas lucrativas. A natureza aberta do conjunto de dados permite que qualquer pessoa construa sistemas de IA adaptados às necessidades específicas da sociedade, ao mesmo tempo que facilita a aprendizagem de forma eficaz em diferentes idiomas.
FineWeb-Edu usa múltiplas anotações por página em alguns idiomas, permitindo o cálculo dinâmico da concordância anotada. As medidas de controle de qualidade incluem planos para aumentar a sobreposição de anotações em idiomas multianotados. Os dados contêm uma coluna lógica 'problematic_content_label_present' para identificar páginas com sinalizadores de conteúdo problemáticos, geralmente causados pela detecção incorreta de idioma. Os usuários podem filtrar o conteúdo com base em rótulos problemáticos individuais ou acordo de rótulo por meio da coluna 'problematic_content_label_agreement'. O conjunto de dados é licenciado sob a licença ODC-By v1.0 e os Termos de Uso do CommonCrawl.
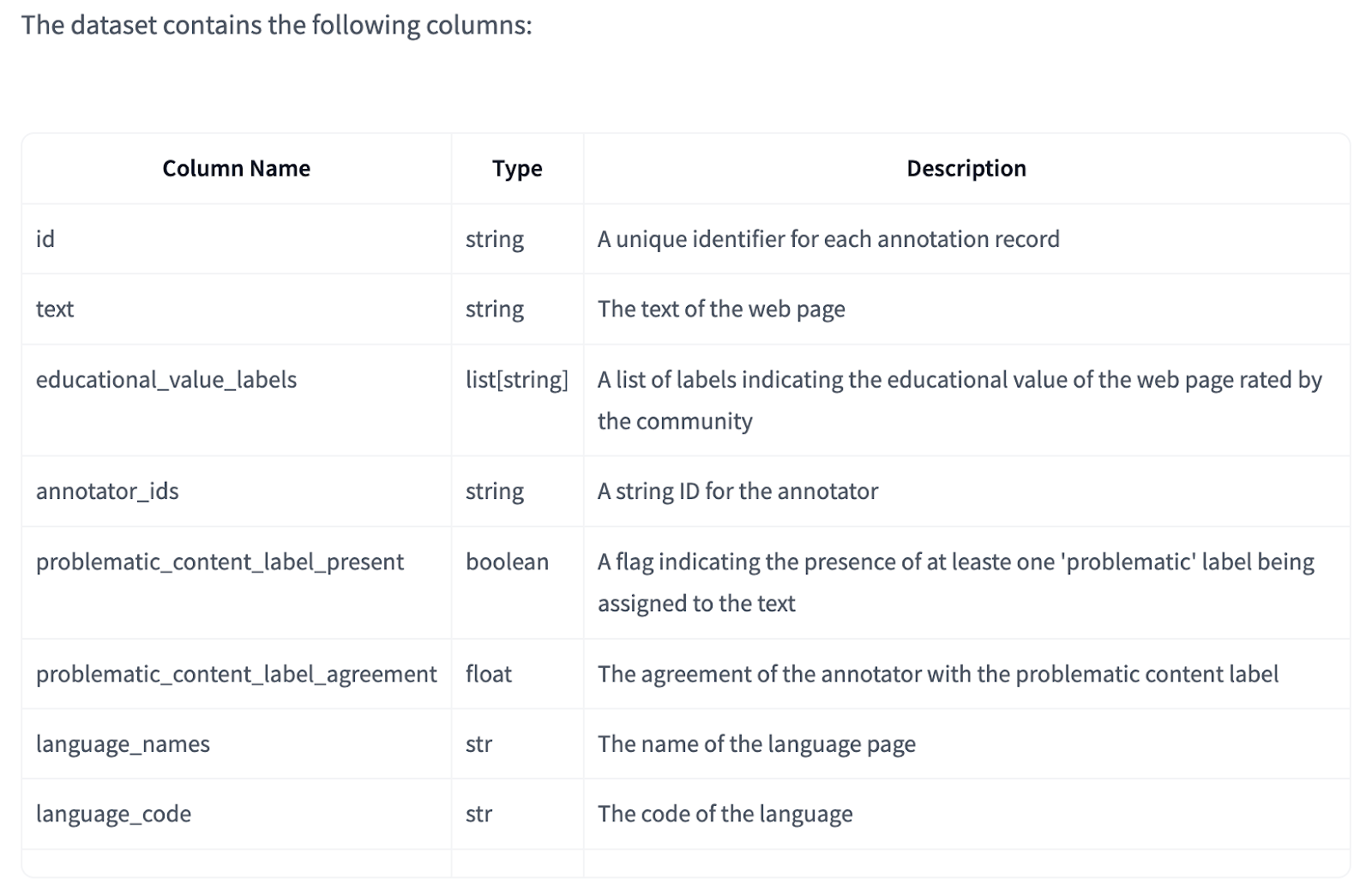
Concluindo, a extensão comunitária do FineWeb2, FineWeb-C, coletou 32.863 anotações de 318 participantes, com foco na rotulagem de conteúdo acadêmico. Este projeto mostra um desempenho muito alto em comparação com conjuntos de dados existentes com dados de treinamento mínimos para a categoria de conteúdo educacional especializado FineWeb-Edu. Ao contrário dos métodos comerciais, este programa de código aberto prioriza anotações humanas em detrimento das baseadas em LLM, especialmente em linguagens de poucos recursos. O conjunto de dados inclui medidas rigorosas de controle de qualidade, incluindo múltiplas camadas de anotações e filtragem de conteúdo problemático, enquanto opera sob a licença ODC-By v1.0.
Confira eu detalhes. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 60k + ML.
🚨 Tendências: LG AI Research Release EXAONE 3.5: Modelos de três níveis de IA bilíngue de código aberto oferecem seguimento de comando incomparável e insights profundos de conteúdo Liderança global em excelência em IA generativa….

Sajjad Ansari se formou no último ano do IIT Kharagpur. Como entusiasta da tecnologia, ele examina as aplicações da IA com foco na compreensão do impacto das tecnologias de IA e suas implicações no mundo real. Seu objetivo é transmitir conceitos complexos de IA de maneira clara e acessível.
🧵🧵 [Download] Avaliação do relatório de trauma do modelo de linguagem principal (estendido)


