
Modelos de linguagem em larga escala (LLMs) ganharam destaque significativo no aprendizado de máquina moderno, principalmente devido à abordagem atencional. Este mecanismo usa mapeamento sequência a sequência para criar representações de token sensíveis ao contexto. Tradicionalmente, a atenção depende da função softmax (SoftmaxAttn) para gerar representações de token como combinações convexas de valores dependentes de dados. No entanto, apesar da sua ampla adoção e eficácia, o SoftmaxAttn enfrenta vários desafios. Um problema principal é a tendência da função softmax de focar a atenção em um número limitado de recursos, o que pode ignorar outros recursos informativos dos dados de entrada. Além disso, o uso de SoftmaxAttn requer uma redução linearmente inteligente no comprimento da sequência de entrada, o que pode desacelerar significativamente o cálculo, especialmente se forem usados limites de atenção eficientes.
Pesquisas recentes em aprendizado de máquina exploraram alternativas para a função softmax geral em vários domínios. Na classificação supervisionada de imagens e na aprendizagem supervisionada, há uma tendência de usar condições ricas de Bernoulli delimitadas por funções sigmóides, a partir da distribuição de fase condicional de saída geralmente parametrizada por softmax. Outros estudos investigaram a substituição do softmax pelo desempenho ReLU em contextos práticos e teóricos. Outros experimentos incluem o uso de ativação de ReLU2, atenção direta e métodos de atenção baseados na correspondência de cosseno. Um método notável ativa as várias funções como n^(-α), onde un é o comprimento da sequência e α é o hiperparâmetro, para substituir o softmax. No entanto, esta abordagem enfrentou problemas de desempenho sem a implementação e uso adequados do LayerScale. Esses vários métodos visam abordar as limitações da atenção baseada em softmax, procurando maneiras mais eficientes e eficazes de representar tokens sensíveis ao contexto.
Os pesquisadores da Apple apresentam uma abordagem robusta para mecanismos de atenção, substituindo a função softmax inteligente por não linearidade sigmóide elemento a elemento. Os pesquisadores apontam que o maior desafio da atenção sigmóide ingênua (SigmoidAttn) reside nos grandes padrões de atenção inicial. Para resolver isso, eles propuseram diversas soluções e fizeram contribuições importantes na área. Primeiro, eles mostram que SigmoidAttn é um aproximador universal para funções sequência a sequência. Em segundo lugar, eles fornecem uma análise da normalidade de SigmoidAttn e estabelecem o seu limite Jacobiano de pior caso. Terceiro, eles melhoram o algoritmo FLASHATTENTION2 com um kernel sigmóide, o que leva a uma redução significativa no tempo de relógio de parede de inferência do kernel e no tempo de interpretação do mundo real. Finalmente, eles mostram que o SigmoidAttn tem um desempenho comparável ao SoftmaxAttn em uma variedade de tarefas e domínios, destacando seu potencial como uma alternativa viável aos mecanismos de atenção.
SigmoidAttn, uma alternativa proposta para a atenção geral do softmax, é analisada de duas maneiras importantes. Primeiro, os pesquisadores mostram que os transformadores que usam SigmoidAttn preservam a Propriedade de Aproximação Universal (UAP), o que garante sua capacidade de aproximar funções contínuas e sequenciais com precisão insignificante. Esta estrutura é importante para manter a disponibilidade de estruturas e a capacidade de representação. A prova adapta a estrutura utilizada para transformadores clássicos, com modificações significativas para se adequar à função sigmóide. Notavelmente, SigmoidAttn requer pelo menos quatro cabeças e turnos de atenção para a consulta e definições de chave para estimar a função de comutação necessária, em comparação com o requisito de atenção softmax de apenas duas cabeças e turnos para a definição de consulta.
Em segundo lugar, o estudo examina a normalidade do SigmoidAttn calculando a constante de Lipschitz. A análise revela que a constante Lipschitz de SigmoidAttn é muito menor do que a aproximação softmax do pior caso. Isso significa que SigmoidAttn apresenta melhor generalização, o que pode levar a maior robustez e simplificação das redes neurais. O limite SigmoidAttn depende da norma quadrada da sequência de substituição para o maior valor, o que permite a aplicação a uma distribuição infinita com segundos momentos limitados.
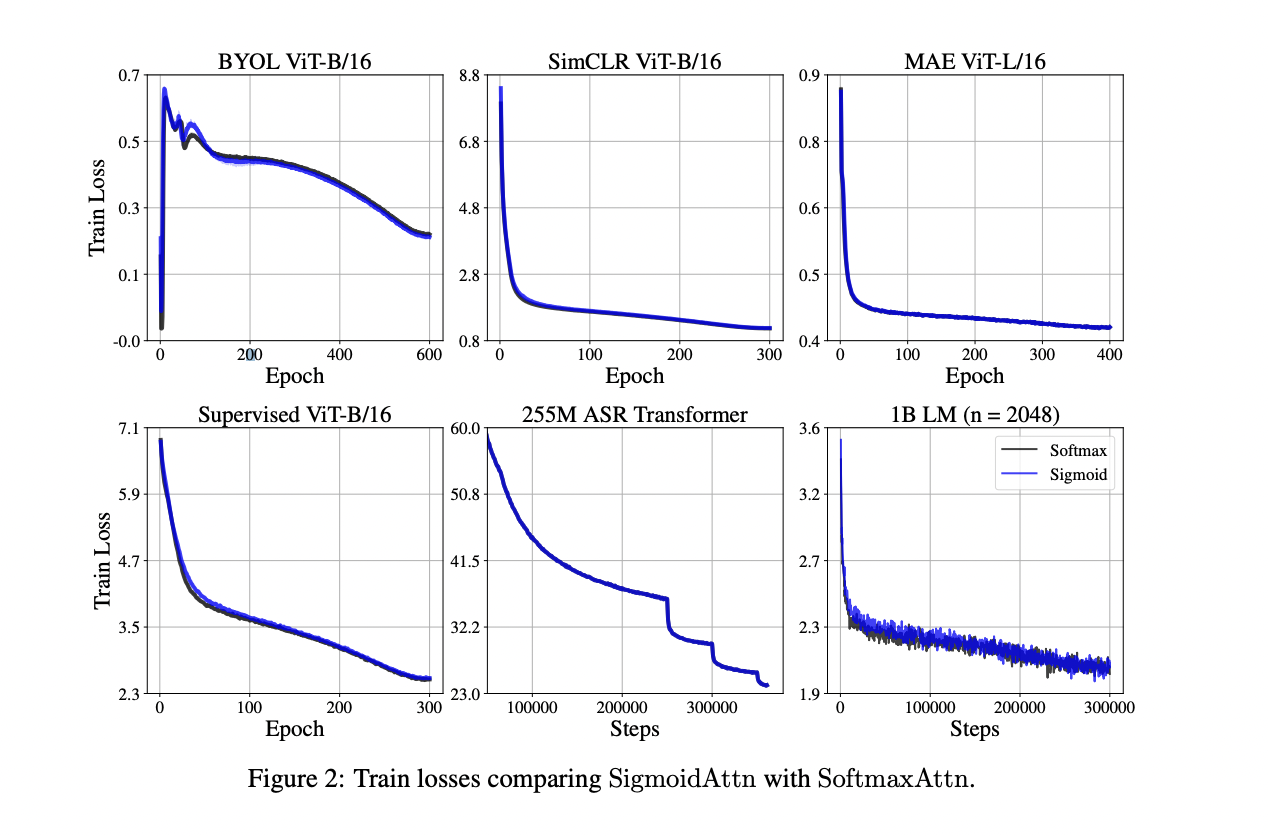
Os pesquisadores conduziram uma avaliação completa do SigmoidAttn em vários domínios para confirmar sua eficácia. Esses experimentos incluem segmentação supervisionada de imagens usando transformações de visão, aprendizagem de representação de imagens supervisionadas com métodos como SimCLR, BYOL e MAE, bem como reconhecimento automático de fala (ASR) e modelagem automática de linguagem (LM). Além disso, eles testaram o comprimento de sequência padrão no TED-LIUM v3 para ASR e testes sintéticos em pequena escala.
Os resultados mostram que o SigmoidAttn corresponde consistentemente ao desempenho do SoftmaxAttn para todos os domínios e algoritmos testados. Este nível de desempenho é alcançado proporcionando treinamento e melhoria na velocidade de projeção, conforme descrito nas seções anteriores. As principais observações de estudos empíricos incluem:
1. Para funções teóricas, SigmoidAttn prova ser eficaz sem exigir um termo de polarização, exceto no caso de MAE. No entanto, ele depende do LayerScale para corresponder ao desempenho do SoftmaxAttn sem parâmetros.
2. Em tarefas de modelagem de linguagem e ASR, o desempenho é sensível ao viés de atenção inicial. Para lidar com isso, é necessária flexibilidade usando incorporação de posição relativa, como ALiBi, que altera a magnitude do log para zero no estado sob SigmoidAttn, ou uma implementação adequada do parâmetro b para obter o mesmo resultado.
Essas descobertas sugerem que o SigmoidAttn é uma alternativa viável ao SoftmaxAttn, proporcionando desempenho semelhante em todos os tipos de aplicativos e, ao mesmo tempo, vantagens computacionais.
Este estudo fornece uma análise abrangente da sensibilidade sigmóide como um possível método de sensibilidade softmax na arquitetura do transformador. Os investigadores fornecem fundamentos teóricos e evidências empíricas para apoiar a eficácia desta abordagem alternativa. Eles mostram que os transformadores que usam aproximação sigmóide retêm a importante propriedade de serem um aproximador de desempenho universal, ao mesmo tempo que exibem uma generalização melhorada em comparação com seus equivalentes softmax. A pesquisa aponta para dois fatores importantes para o sucesso da implementação da atenção sigmóide: uso de LayerScale assim como evitando grandes tendências de atenção inicial. Esta informação contribui para o estabelecimento de melhores práticas para aplicação de atenção sigmoidal a modelos de transformadores. Além disso, os pesquisadores introduziram o FLASHSIGMOID, uma variante da atenção sigmóide com uso eficiente de memória que atinge uma aceleração de 17% no desempenho do kernel de inferência. Testes extensivos em uma variedade de domínios – incluindo processamento de linguagem, visão computacional e reconhecimento de fala – mostram que a atenção sigmóide normalizada supera consistentemente a atenção softmax em uma variedade de tarefas e escalas.
Confira Papel de novo GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.
👨💻 HyperAgent: agentes genéricos de engenharia de software para resolver tarefas de codificação em escala.


