
O design atual de modelos de linguagem causal, como GPTs, está sobrecarregado com o desafio da associação semântica a longas distâncias devido ao seu design one-token-ahead. Isto ajudou o desenvolvimento da IA para uma produção significativa, mas muitas vezes leva a uma “inundação de tópicos” quando uma longa sequência é produzida, uma vez que cada token previsto depende apenas da presença de tokens anteriores, e não numa perspectiva mais ampla. Isso limita a utilidade desses modelos para aplicações complexas do mundo real com subjetividade estrita, como geração de narrativas, criação de conteúdo e tarefas de codificação. Superar esse desafio ao permitir a previsão de vários tokens pode melhorar muito a continuidade semântica, a precisão e a consistência das sequências geradas dos atuais modelos de linguagem generativa.
Houve várias maneiras de lidar com a previsão de vários tokens, cada uma com limitações diferentes. Modelos que visam fazer previsões de vários tokens classificando embeddings ou tendo múltiplos cabeçalhos de linguagem são estatisticamente robustos e muitas vezes ineficientes. Para modelos Seq2Seq em conjuntos codificadores-decodificadores, embora isso permita a previsão de vários tokens, eles não conseguem capturar o conteúdo após uma única incorporação; portanto, existem muitas causas de ineficiência. Embora o BERT e outros modelos de linguagem oculta possam prever muitos tokens de sequência codificados, eles falham na geração da esquerda para a direita, limitando assim seu uso à previsão do texto da sequência. Por outro lado, o ProphetNet usa uma estratégia de previsão em gramas; no entanto, isso não é consistente em uma ampla variedade de tipos de dados. As limitações básicas dos métodos acima mencionados são problemas de escala, desperdício computacional e resultados muitas vezes indesejáveis, ao mesmo tempo que produzem previsões de alta qualidade sobre problemas de contexto de longo prazo.
Pesquisadores da EPFL apresentam o modelo Future Token Prediction, que representa uma nova arquitetura para criar tokens incorporados para uma conscientização mais ampla. Isso permitirá a previsão contínua de vários tokens onde, diferentemente dos modelos convencionais, a incorporação das camadas superiores é usada por um codificador de transformador para fornecer uma “pseudosequência” acompanhada por um pequeno decodificador para a próxima previsão de token. Dessa forma, o modelo usa esses recursos de codificador-decodificador FTP para armazenar informações de contexto de tokens históricos para fazer transições suaves e manter a consistência do tópico em várias previsões de token. Com o contexto de sequência mais difundido escrito em sua incorporação, o FTP fornece uma forte continuidade de geração de sequência e se tornou uma das melhores maneiras de gerar conteúdo e outras aplicações que exigem compatibilidade semântica de formato longo.
O modelo FTP usa uma arquitetura GPT-2 modificada que consiste em um codificador de 12 camadas com um codificador de 3 camadas. Seu codificador gera uma incorporação de tokens projetados linearmente em comprimento máximo em uma sequência pseudo-12-dimensional que o decodificador colapsa para dar sentido à sequência de conteúdo. Compartilhe pesos de incorporação entre codificador e decodificador; ele é treinado em dados OpenWebText e usa o token GPT-2. Enquanto isso, o melhor desempenho é do AdamW, com tamanho de cluster de 500 e taxa de aprendizado de 4e-4. Há um parâmetro gama definido como 0,8 neste modelo para reduzir gradualmente a atenção dada aos tokens longe do futuro, para que as previsões imediatas permaneçam altamente precisas. Desta forma, o modelo FTP é capaz de manter a consistência semântica sem grande sobrecarga computacional e, assim, consegue um bom compromisso entre eficiência e desempenho.
De fato, esses resultados e testes mostram que o modelo traz melhorias significativas em comparação com os GPTs tradicionais em muitas métricas de desempenho importantes: redução significativa de confusão, melhor precisão de previsão e maior estabilidade de tarefas sequenciais de longo prazo. Ele também fornece alta recuperação, precisão e pontuações F1 em testes de qualidade de texto baseados em BERT, o que pode significar consistentemente um melhor alinhamento semântico em relação a sequências de texto reais. Ele também tem desempenho melhor do que os modelos GPT em tarefas de classificação de texto, como análises do IMDB e da Amazon, e sempre fornece melhor perda de validação com maior precisão. Mais importante ainda, o FTP segue o tópico de texto produzido de forma mais coerente, apoiado por altas pontuações semelhantes a cossenos em testes sequenciais de longo prazo, continuando a encontrar a sua capacidade de produzir conteúdo coerente e contextualmente relevante em uma variedade de aplicações.
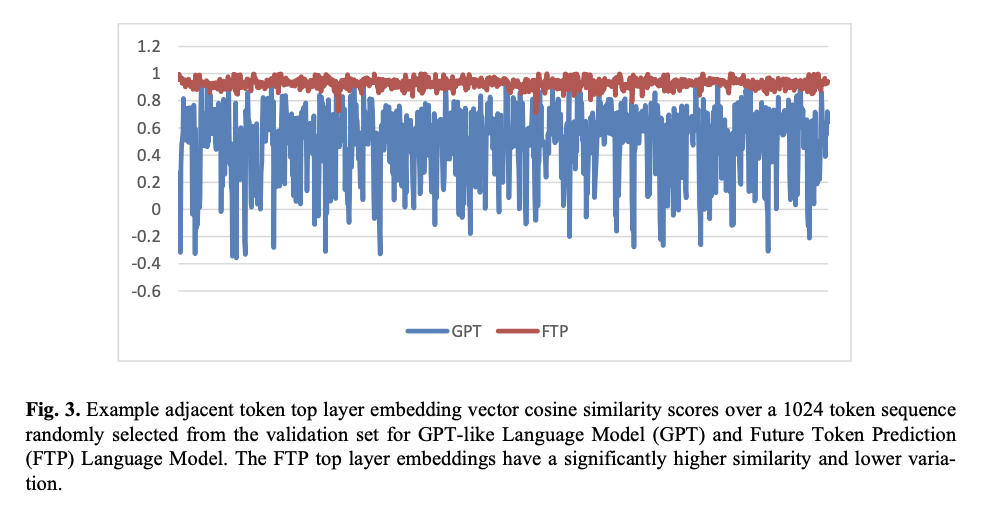
O modelo FTP representa uma mudança de paradigma na modelagem linguística causal, que avança as ineficiências críticas das abordagens clássicas de token único para incorporações que suportam visões mais amplas e sensíveis ao contexto para fazer previsões de vários tokens. Ao melhorar a precisão preditiva e a relevância semântica, esta diferença é sublinhada por melhores pontuações tanto na confusão como nas métricas baseadas em BERT numa vasta gama de tarefas. A abordagem pseudo-sequencial para chamar a atenção neste modelo melhora a IA generativa, extraindo um fluxo de história consistente – um requisito crítico para modelagem de alto valor de linguagem relevante para o tópico em todos os aplicativos que exigem integridade semântica.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Trending] LLMWare apresenta Model Depot: uma coleção abrangente de modelos de linguagem pequena (SLMs) para PCs Intel
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


