
A pesquisa do vizinho mais próximo (ANNS) é uma tecnologia chave que alimenta vários aplicativos baseados em IA, como mineração de dados, mecanismos de pesquisa e sistemas de recomendação. O principal objetivo do ANNS é identificar os vetores mais próximos de uma determinada consulta em espaços de alta dimensão. Essa técnica é importante em situações em que encontrar itens semelhantes rapidamente é importante, como reconhecimento de imagem, processamento de linguagem natural e grandes mecanismos de recomendação. No entanto, à medida que o tamanho dos dados aumenta para milhares de milhões de vetores, os sistemas ANNS enfrentam desafios significativos em termos de desempenho e escalabilidade. O gerenciamento adequado desses conjuntos de dados requer recursos computacionais e de memória significativos, tornando-se uma tarefa muito complexa e cara.
O principal problema que esta pesquisa aborda é que as soluções ANNS existentes muitas vezes precisam de ajuda para lidar com a grande escala dos conjuntos de dados modernos, mantendo a eficiência e a precisão. Os métodos tradicionais não são suficientes para dados em escala de bilhões porque exigem alto uso de memória e poder de processamento. Técnicas como arquivo invertido (FIV) e métodos de indexação baseados em gráficos foram desenvolvidas para resolver essas limitações. No entanto, eles geralmente exigem memória em escala de terabytes, o que os torna caros e consomem muitos recursos. Além disso, a complexidade computacional de realizar cálculos de grandes distâncias entre vetores de alta dimensão em grandes conjuntos de dados é um gargalo para os sistemas ANNS atuais.
No estado atual da tecnologia ANNS, métodos que consomem muita memória, como fertilização in vitro e índices baseados em gráficos, são frequentemente usados para organizar o espaço de busca. Embora esses métodos possam melhorar o desempenho da consulta, eles também aumentam significativamente o uso de memória, especialmente para grandes conjuntos de dados contendo bilhões de vetores. As técnicas de indexação hierárquica (HI) e quantidade de produto (PQ) melhoram a utilização da memória armazenando índices em SSDs e usando representações vetoriais compactadas. No entanto, essas soluções podem causar degradação significativa do desempenho devido à sobrecarga introduzida pelas operações de compactação e desduplicação de dados, o que pode levar à perda de precisão. Sistemas atuais como SPANN e RUMMY têm mostrado vários graus de sucesso, mas permanecem limitados pela sua incapacidade de equilibrar o uso de memória e a eficiência computacional.
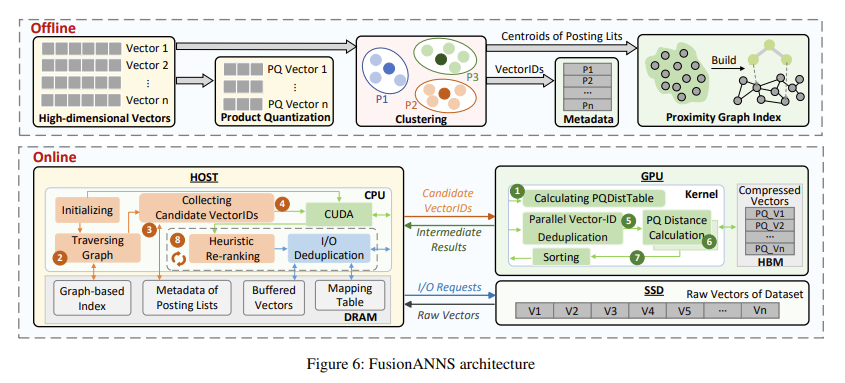
Pesquisadores da Universidade de Ciência e Tecnologia de Huazhong e da Huawei Technologies Co., Ltd apresentaram FusãoANNSuma nova arquitetura de coprocessamento CPU/GPU projetada especificamente para conjuntos de dados em escala de bilhões para enfrentar esses desafios. FusionANNS usa uma estrutura de índice multicamadas que otimiza o poder de CPUs e GPUs. Essa arquitetura permite simulações de busca de vizinhos em alta velocidade e baixa latência usando apenas uma única GPU básica, tornando-a uma solução econômica. A abordagem dos pesquisadores se concentra em três inovações básicas: indexação multinível, reordenação heurística e desduplicação de E/S, que reduz a transferência de dados entre CPUs, GPUs e SSDs para eliminar gargalos de desempenho.
A estrutura de índice multinível do FusionANNS permite a filtragem conjunta de CPU/GPU, armazenando vetores brutos em SSDs, vetores compactados na memória de alta largura de banda da GPU (HBM) e identificadores de vetor na memória do host. Essa arquitetura evita a troca excessiva de dados entre CPUs e GPUs, reduzindo bastante o desempenho de E/S. A reordenação heurística melhora a precisão da consulta, dividindo o processo de reordenação em lotes menores e usando um método de controle de feedback para eliminar antecipadamente cálculos desnecessários. O componente final, desduplicação de E/S com reconhecimento de redundância, combina vetores paralelos de alto nível para planejamento de armazenamento otimizado, reduzindo em 30% o número de solicitações de E/S durante o reordenamento e eliminando operações de E/S redundantes com técnicas eficazes de armazenamento em cache.
Os resultados dos testes mostram que o FusionANNS supera os sistemas de última geração, como SPANN e RUMMY, em várias métricas. O sistema atinge 13,1 vezes mais consultas por segundo (QPS) e 8,8 vezes mais eficiência de custo em comparação com SPANN, e 2-4,9 vezes mais QPS e 6,8 vezes mais eficiência de custo em comparação com RUMMY. Para um conjunto de dados contendo um bilhão de vetores, o FusionANNS pode lidar com um processo de consulta em mais de 12.000 QPS, mantendo a latência tão baixa quanto 15 milissegundos. Esses resultados mostram que o FusionANNS é muito eficaz no tratamento de conjuntos de dados em escala multibilionária sem recursos de memória extensos.
As principais conclusões deste estudo incluem:
- Melhoria de desempenho: FusionANNS atinge QPS 13,1x maior e eficiência de custo 8,8x do que o sistema SPANN baseado em SSD de última geração.
- Alcançando Eficiência: Ele oferece eficiência 5,7-8,8× maior no tratamento de acesso e processamento de dados baseados em SSD.
- Escalabilidade: FusionANNS pode lidar com conjuntos de dados em escala de bilhões usando apenas uma única GPU básica e recursos mínimos de memória.
- Eficácia de custos: O sistema mostra uma melhoria de 2 a 4,9× na eficiência de custos em comparação com soluções de memória existentes, como RUMMY.
- Redução de latência: FusionANNS mantém uma latência de consulta de 15 milissegundos, muito menor do que outras soluções baseadas em SSD e GPU.
- Inovação em Design: O uso de indexação multinível, redimensionamento heurístico e redução de E/S com reconhecimento de redundância são as contribuições fundamentais que tornam o FusionANNS diferente dos métodos existentes.

Concluindo, FusionANNS representa um avanço na tecnologia ANNS ao fornecer alto rendimento, baixa latência e alta eficiência de custos. A nova abordagem dos pesquisadores de colaboração CPU/GPU e indexação multinível fornece uma solução eficiente para dimensionar ANNS para suportar grandes conjuntos de dados. FusionANNS estabelece um novo padrão para lidar com dados de alta dimensão em aplicações do mundo real, reduzindo a memória e eliminando cálculos desnecessários.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
Convidamos startups, empresas e institutos de pesquisa que trabalham em modelos de microlinguagem para participar deste próximo evento Revista/Relatório 'Modelos de Linguagem Pequena' Marketchpost.com. Esta revista/relatório será lançada no final de outubro/início de novembro de 2024. Clique aqui para agendar uma chamada!
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.
![OCR (Ocline Character Recognition) – Definição, vantagens, desafios e casos de uso [Infographic]](https://i0.wp.com/f5b623aa.rocketcdn.me/wp-content/uploads/2022/09/Blog-SM_What-is-OCR.jpg?w=320&resize=320,200&ssl=1 "OCR (Ocline Character Recognition) – Definição, vantagens, desafios e casos de uso [Infographic]")

