
Modelos de linguagem em larga escala (LLMs) fazem parte de muitos programas de IA, mostrando capacidades notáveis em uma variedade de aplicações. No entanto, à medida que aumenta a necessidade de processar entradas de conteúdo longas, os pesquisadores enfrentam grandes desafios para melhorar o desempenho do LLM. A capacidade de gerenciar uma ampla gama de sequências de entrada é essencial para melhorar o desempenho dos agentes de IA e melhorar a recuperação de estratégias de produção aprimoradas. Embora os desenvolvimentos recentes tenham aumentado a capacidade do LLM de processar entradas de até 1 milhão de tokens, isso acarreta um custo significativo de recursos computacionais e de tempo. O principal desafio está em acelerar a velocidade de geração de LLM e reduzir o uso de memória GPU para entradas de conteúdo longas, o que é importante para reduzir a latência de resposta e aumentar o rendimento de chamadas de API LLM. Embora técnicas como a otimização do cache KV tenham melhorado a fase de produção iterativa, a fase de integração rápida continua sendo um gargalo significativo, especialmente à medida que os cenários de implantação aumentam. Isto levanta uma questão importante: como os pesquisadores podem acelerar e reduzir o uso de memória durante a fase rápida da computação?
Esforços anteriores para acelerar a geração de LLM com incorporação de contexto longo concentraram-se principalmente em métodos de compactação e extração de cache KV. Métodos como extração especial de conteúdo de longo alcance, streaming LLM com portas de atenção e indexação dinâmica esparsa foram desenvolvidos para melhorar a fase de geração iterativa. Esses métodos visam reduzir o consumo de memória e o tempo de execução associados ao cache KV, especialmente para entradas longas.
Algumas técnicas, como QuickLLaMA e ThinK, particionam e limpam o cache KV para armazenar apenas os tokens ou dimensões que importam. Outros, como H2O e SnapKV, concentram-se na manutenção de tokens que contribuem significativamente para agregar atenção ou são valiosos com base nas janelas de visualização. Embora esses métodos tenham se mostrado promissores no desenvolvimento da fase de fabricação iterativa, eles não resolvem o gargalo na fase computacional rápida.
Uma abordagem diferente envolve compactar a sequência de entrada eliminando a redundância de conteúdo. Porém, este método precisa armazenar grande parte dos tokens de entrada para manter o desempenho do LLM, limitando seu desempenho com compressão significativa. Apesar desses avanços, o desafio de reduzir simultaneamente o tempo de processamento e o uso de memória da GPU durante as fases de cálculo rápido e as fases de produção iterativa permanece sem solução.
Pesquisadores da Universidade de Wisconsin-Madison, da Salesforce AI Research e da Universidade de Hong Kong estão lá Filtro Gemuma compreensão única de como os LLMs processam informações. Esta abordagem baseia-se na observação de que os LLMs frequentemente identificam tokens relevantes nas primeiras camadas, mesmo antes de gerar uma resposta. GemFilter usa essas primeiras camadas, chamadas “camadas de filtro”, para compactar sequências de entrada muito longas.
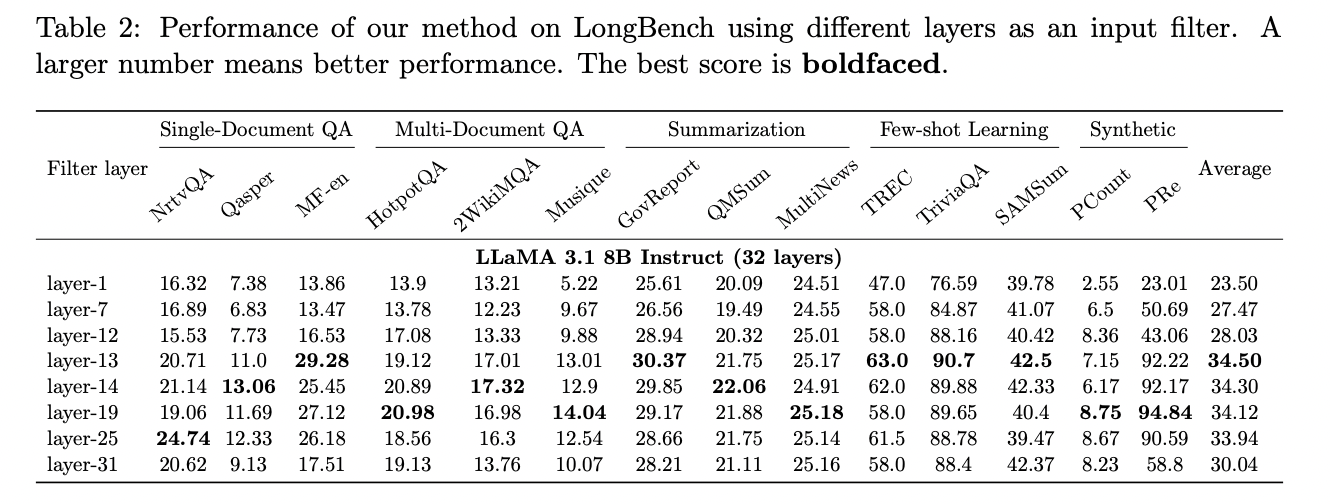
O método funciona analisando a matriz de atenção dessas camadas iniciais para integrar as informações necessárias para responder às perguntas. Por exemplo, no modelo LLaMA 3.1 8B, as camadas 13 a 19 podem resumir com eficácia as informações necessárias. Isso permite que o GemFilter execute uma enumeração rápida apenas de entradas de contexto longas nessas camadas de filtro, compactando tokens de entrada de até 128K para apenas 100.
Ao selecionar um subconjunto de tokens com base nos padrões de atenção nessas camadas iniciais, o GemFilter consegue uma redução significativa no tempo de processamento e no uso de memória da GPU. Os tokens selecionados são então inseridos no modelo completo para orientação, seguidos por operações de fabricação padrão. Este método aborda o problema na fase de computação rápida, mantendo um desempenho comparável aos métodos existentes na fase de produção iterativa.
A arquitetura do GemFilter foi projetada para melhorar o desempenho do LLM usando uma camada de pré-processamento para selecionar tokens com eficiência. O método usa matrizes de atenção das primeiras camadas, especificamente “camadas de filtragem”, para identificar e suprimir tokens de entrada relevantes. Este processo envolve a análise de padrões de atenção para selecionar um subconjunto de tokens que contenham as informações relevantes necessárias para a tarefa.
O núcleo da criação do GemFilter é sua abordagem em duas etapas:
1. Seleção de token: GemFilter usa a matriz de atenção da primeira camada (por exemplo, camada 13 no LLaMA 3.1 8B) para compactar os tokens de entrada. Ele seleciona os k principais índices na última linha da matriz de atenção, reduzindo efetivamente o tamanho da entrada de possíveis 128 mil tokens para cerca de 100 tokens.
2. Descrição completa do modelo: Os tokens selecionados são então processados em todo o LLM para obter uma descrição completa, seguida por operações de produção padrão.
Este recurso permite que o GemFilter obtenha aceleração significativa e redução de memória durante a fase de compilação rápida, mantendo o desempenho na fase de produção iterativa. O método é baseado no Algoritmo 1, que descreve as etapas específicas de seleção e processamento de tokens. O design do GemFilter é notável por sua simplicidade, falta de requisitos de treinamento e ampla aplicabilidade a todos os tipos de arquiteturas LLM, tornando-o uma solução versátil para melhorar a eficiência do LLM.
As arquiteturas GemFilter são construídas em uma abordagem de duas passagens para melhorar o desempenho do LLM. O algoritmo principal, descrito no Algoritmo 1, consiste nas seguintes etapas importantes:
1. Passagem direta inicial: O algoritmo usa apenas as primeiras r camadas da rede conversora de camada m na ordem das T entradas. Esta etapa gera as matrizes de consulta e chave (Q(r) e K(r)) para a r-ésima camada, que atua como uma camada de filtragem.
2. Selecionando Tokens: Usando a matriz de atenção da r-ésima camada, GemFilter seleciona os k tokens mais relevantes. Isso é feito identificando os maiores valores k da última linha da matriz de atenção, que representa a interação entre o último token de consulta e todos os tokens principais.
3. Tratamento de atenção múltipla: Para atenção multicabeças, o processo de seleção considera a soma da última linha em todas as matrizes das cabeças de atenção.
4. Reordenação de tokens: Os tokens selecionados são então reorganizados para preservar sua ordem de entrada original, garantindo a formação adequada da sequência (por exemplo, mantendo
5. Geração Final: O algoritmo usa um passe direto completo e a função de geração usa apenas k tokens selecionados, reduzindo significativamente o comprimento do contexto de entrada (por exemplo, de 128K para 1024 tokens).
Este método permite que o GemFilter processe com eficiência entradas longas usando informações da camada inicial para selecionar tokens, reduzindo assim o tempo de computação e o uso de memória nas fases de computação rápida e nas fases de geração iterativa.

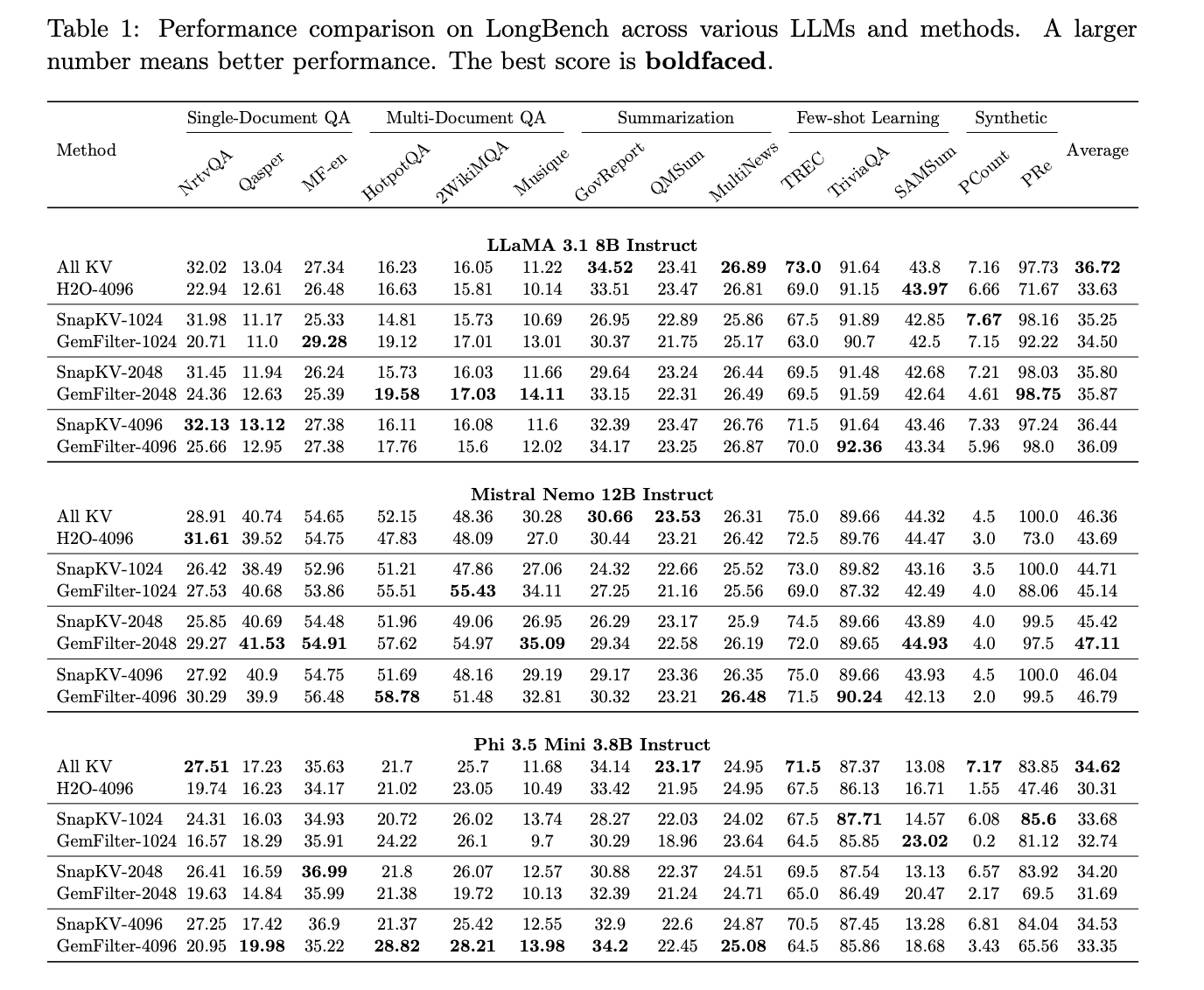
GemFilter mostra um desempenho impressionante em vários benchmarks, demonstrando sua eficácia no tratamento de longas entradas de conteúdo para LLMs.
No benchmark Needle in the Haystack, que testa a capacidade do LLM de encontrar informações específicas em documentos extensos, o GemFilter supera significativamente os métodos de atenção padrão (All KV) e SnapKV. Esse alto desempenho é observado nos modelos Mistral Nemo 12B Instruct e LLaMA 3.1 8B Instruct, que possuem comprimentos de entrada de 60K e 120K tokens, respectivamente.
No benchmark multitarefa do LongBench, que testa a compreensão de conteúdo longo em uma variedade de tarefas, o GemFilter mostra desempenho comparável ou melhor no atendimento padrão, mesmo ao usar apenas 1.024 tokens selecionados. Por exemplo, GemFilter-2048 passa pela atenção padrão do modelo Mistral Nemo 12B Instruct. GemFilter também apresenta melhor desempenho que H2O e desempenho comparável ao SnapKV.
Notavelmente, o GemFilter alcança esses resultados ao mesmo tempo em que compacta efetivamente o conteúdo de entrada. Reduz os tokens de entrada em média 8% ao usar 1.024 tokens e 32% ao usar 4.096 tokens, com uma precisão que não se importa com quedas. Esses recursos de compactação, combinados com sua capacidade de filtrar informações importantes e fornecer resumos interpretáveis, fazem do GemFilter uma ferramenta poderosa para melhorar o desempenho do LLM em projetos de conteúdo longos.
GemFilter mostra melhorias significativas na eficiência computacional e utilização de recursos. Comparado aos métodos existentes, como SnapKV e atenção padrão, o GemFilter atinge uma aceleração de 2,4× enquanto reduz o uso de memória da GPU em 30% e 70%, respectivamente. Esta vantagem de eficiência decorre do método de processamento trifásico do GemFilter, onde contextos de entrada longos são tratados apenas durante a primeira fase. As seções a seguir trabalham com entrada compactada, resultando em economias significativas de recursos. Os testes com os modelos Mistral Nemo 12B Instruct e Phi 3.5 Mini 3.8B Instruct também confirmam o desempenho superior do GemFilter em termos de tempo de execução e uso de memória GPU em comparação com métodos de última geração.
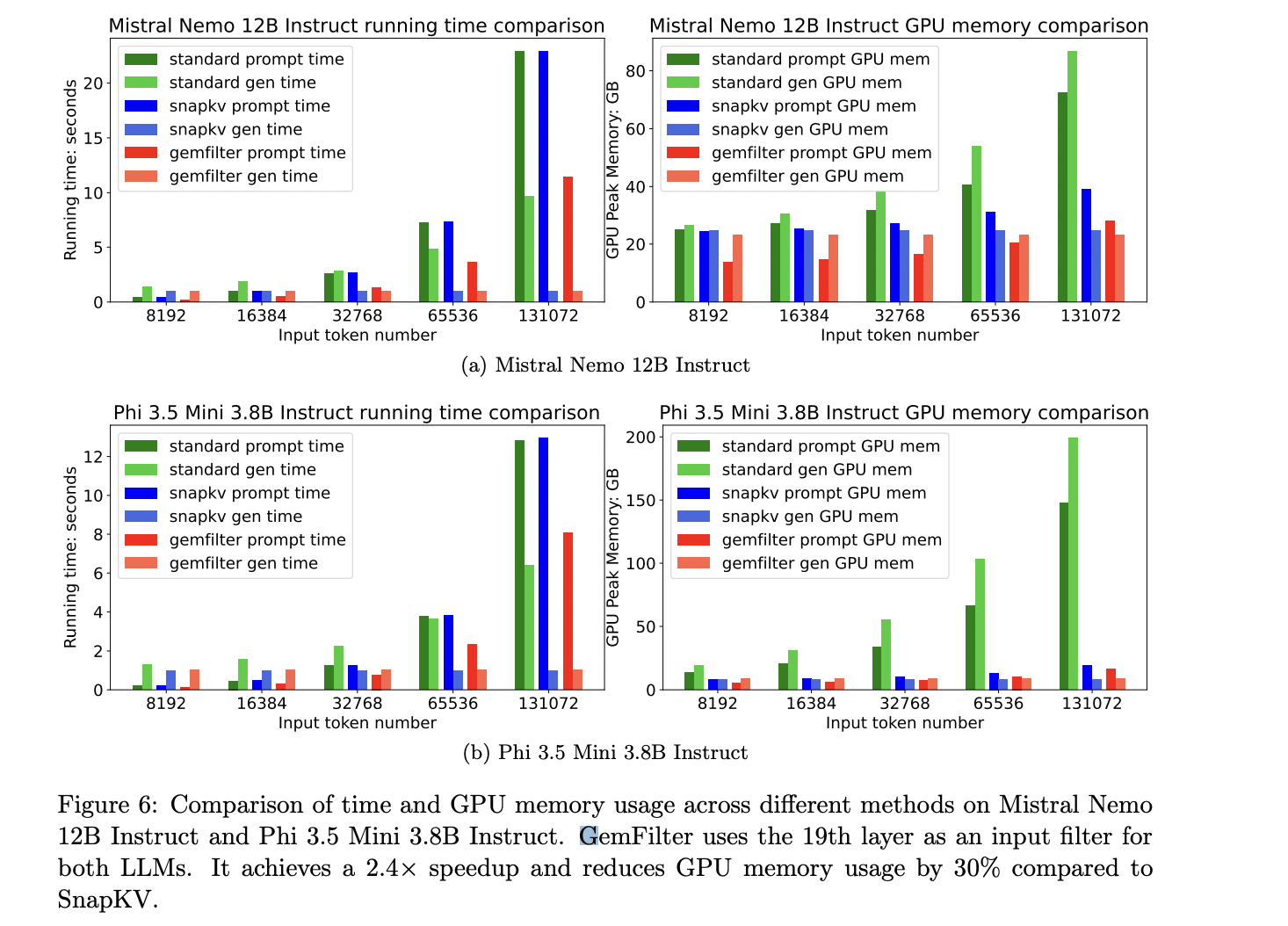
Esta pesquisa está chegando Filtro Gemabordagem robusta para melhorar a interpretação LLM de entradas de contexto longas, abordando desafios críticos em velocidade e eficiência de memória. Ao aproveitar o poder das camadas originais do LLM para identificar informações relevantes, o GemFilter alcança melhorias significativas em relação às técnicas existentes. Um mecanismo de aceleração de 2,4× e uma redução de 30% no uso de memória da GPU, juntamente com seu desempenho superior em relação ao benchmark Needle in Haystack, ressaltam seu desempenho. A simplicidade do GemFilter, a natureza sem treinamento e a ampla compatibilidade com vários LLMs o tornam uma solução versátil. Além disso, sua interpretação aprimorada por meio de testes diretos de tokens fornece insights importantes sobre os mecanismos internos do LLM, contribuindo tanto para avanços práticos no uso do LLM quanto para uma compreensão mais profunda desses modelos complexos.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Interessado em promover sua empresa, produto, serviço ou evento para mais de 1 milhão de desenvolvedores e pesquisadores de IA? Vamos trabalhar juntos!
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que está constantemente pesquisando a aplicação do aprendizado de máquina na área da saúde.


