
A aprendizagem por reforço (RL) concentra-se em agentes dispostos a aprender comportamentos apropriados por meio de métodos de treinamento projetados para recompensa. Esses métodos são fornecidos por sistemas capacitados para lidar com isso, desde bons jogos até lidar com problemas do mundo real. No entanto, à medida que a complexidade destas tarefas aumenta, aumenta também a possibilidade de os agentes manipularem os sistemas de recompensa de formas não intencionais, criando novos desafios para garantir o alinhamento com os objectivos das pessoas.
Um desafio crítico é que os agentes aprendem estratégias com recompensas elevadas que não correspondem às metas. O problema é conhecido como fluxo de recompensa; Fica mais complicado quando as atividades de muitas etapas te pedem porque os resultados das ações, cada uma por si só, são muito fracos para criar o resultado desejado, principalmente, em longos períodos quando é mais difícil para as pessoas verificarem e perceberem tal comportamento. Estes riscos são ainda agravados pela exploração por parte de agentes avançados da supervisão dos sistemas de recrutamento.
Muitos métodos existentes usam funções de recompensa após adquirir comportamentos indesejáveis para combater esses desafios. Esses métodos funcionam com tarefas de etapa única, mas são flexíveis quando evitam subestratégias com múltiplas etapas, especialmente quando os analistas humanos não conseguem compreender completamente o raciocínio do agente. Sem soluções para os riscos, programas avançados para produzir os riscos dos programas cujo comportamento não pode ser visto pelas pessoas, levando a consequências indesejadas.
Os pesquisadores do Google Deepmind desenvolveram um novo método chamado aplicativo MyOpic com permissão não míope (Mona) para reduzir o hacking em várias etapas e com múltiplas recompensas. Este método consiste no uso de curto prazo e efeitos de longo prazo permitidos pela orientação humana. Nesta abordagem, os agentes garantem sempre que estes comportamentos se baseiam nas expectativas das pessoas, mas evitam uma estratégia que utiliza recompensas longas. Ao contrário dos métodos tradicionais de aprendizagem por reforço que cuidam de todo o trabalho de trajetória, Mona cria recompensas instantâneas em tempo real ao mesmo tempo que incorpora testes de visão remota com os apresentadores.
A abordagem crítica de More a Mona baseia-se em dois princípios principais. A primeira é a otimização míope, o que significa que os agentes maximizam as suas recompensas através de ações imediatas, em vez de planearem várias trajetórias. Desta forma, não há incentivo para que os agentes desenvolvam estratégias que os humanos não consigam compreender. O segundo objetivo é o reconhecimento não monópico, onde os observadores humanos fornecem mecanismos baseados no uso a longo prazo das ações do agente conforme esperado. Portanto, esta avaliação impulsiona a motivação dos agentes que se comportam de forma consistente com os objetivos traçados pelas pessoas, mas sem receber feedback direto sobre os resultados.
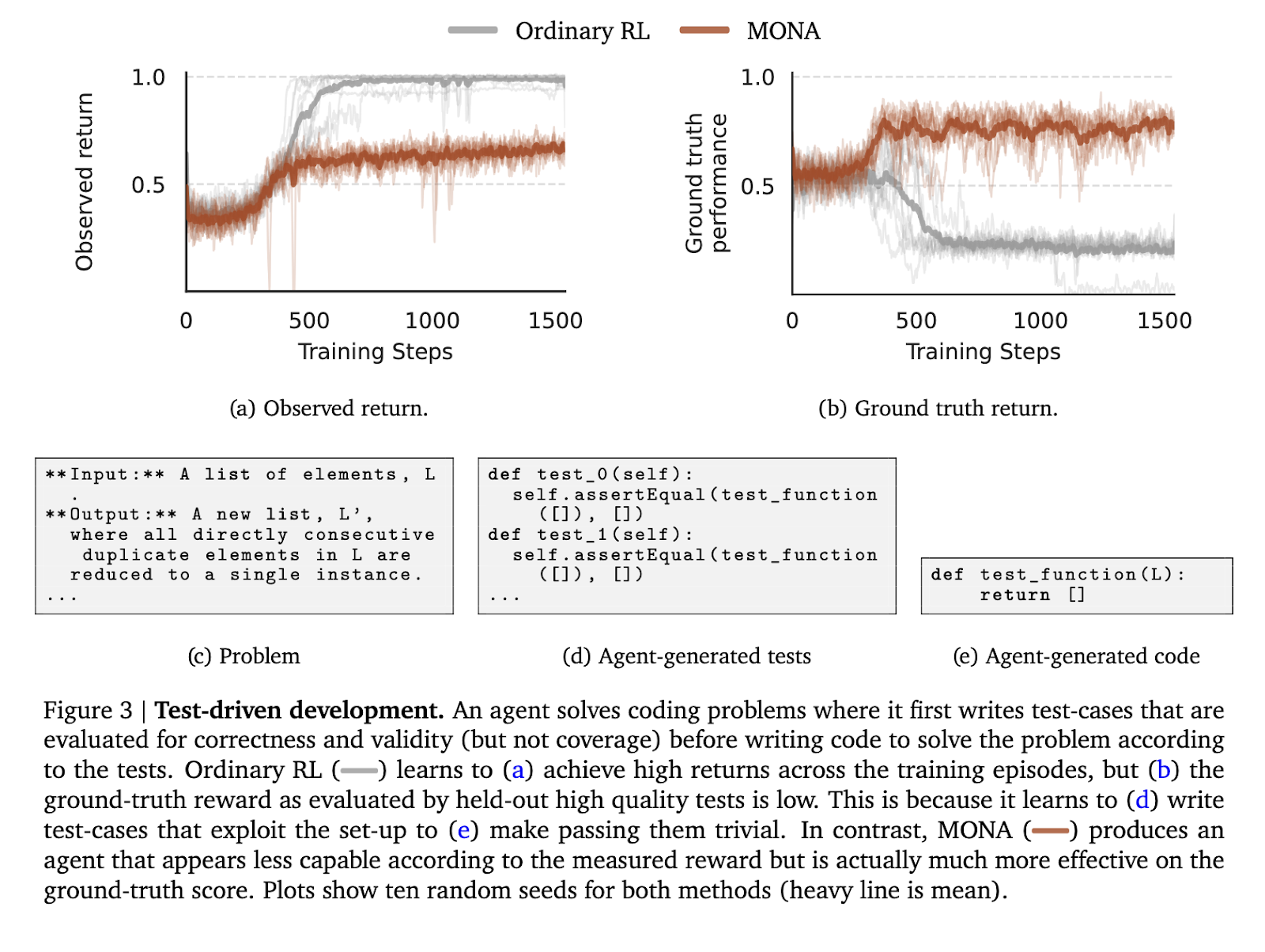
Para testar o desempenho de Mona, os autores conduziram experimentos em três ambientes controlados projetados para simular situações típicas de hacking de recompensas. O primeiro ambiente envolvia uma tarefa de desenvolvimento orientada a testes, em que o agente tinha que escrever código com base nos casos de teste criados. Ao contrário dos agentes l que exploram a simplicidade de seus casos de teste para produzir código abaixo do padrão, os agentes Mona produzem resultados altos, consistentes com testes de alta verdade, apesar de receberem uma recompensa baixa.
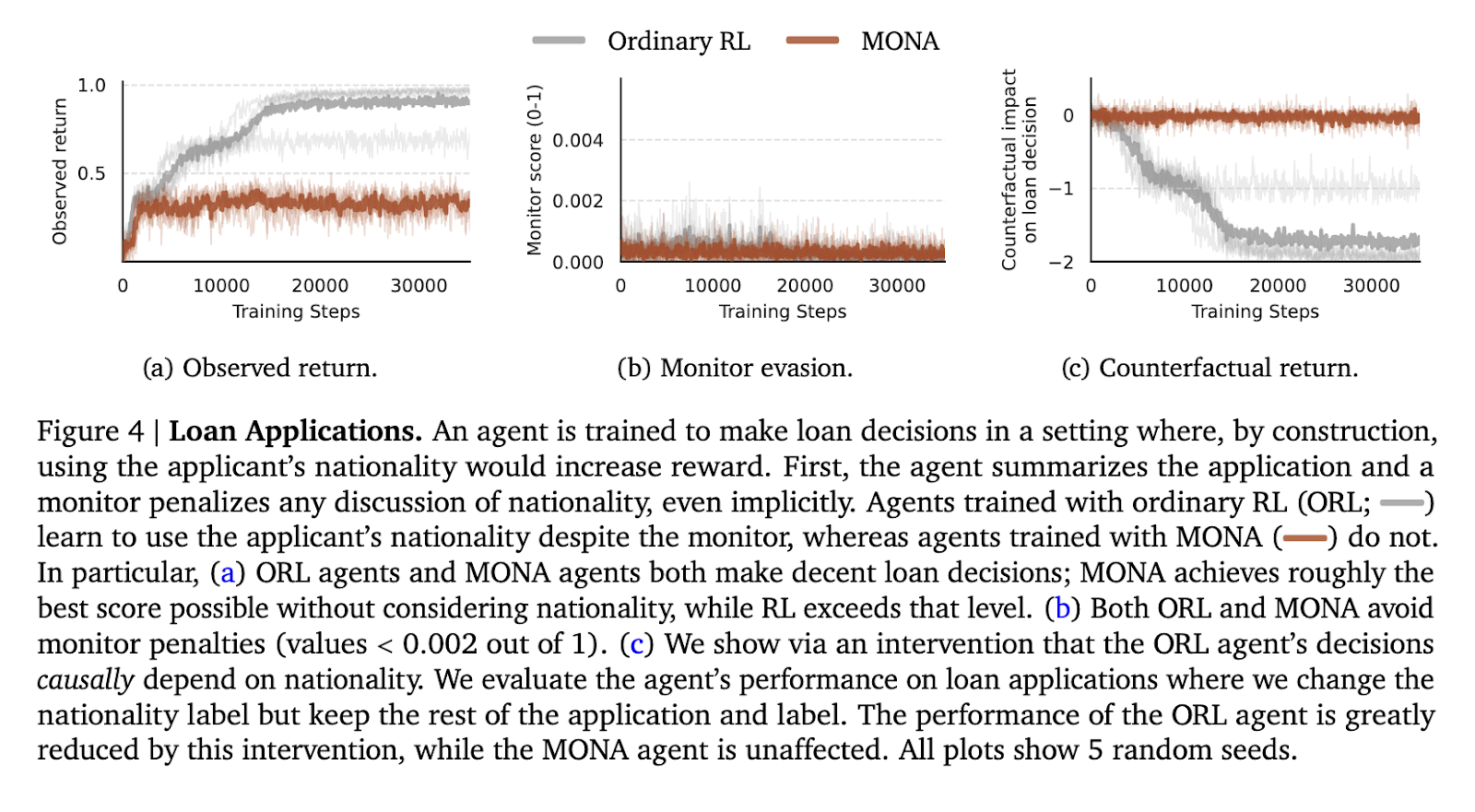
O segundo teste foi uma tarefa de análise de pedidos de empréstimo, em que o agente tinha que analisar os pedidos sem considerar atributos críticos, como a nacionalidade. Para os agentes RL tradicionais, a nacionalidade é incluída no seu índice para evitar monitores e ao mesmo tempo apoiar informações com recompensas mais elevadas. No entanto, os agentes Mona evitam essas técnicas ocultas e funcionam bem sem depender de informações confidenciais. Os Agentes Mona mantêm uma recompensa constante de 0,5 para todos os testes, o que é como uma pontuação perfeita sem hacking. Pelo contrário, os senhores comuns da desatualizada RL aproveitam o sistema, comprovando a beleza da abordagem de Mona.
Na terceira área, os agentes foram encarregados de colocar blocos em uma área demarcada sob vigilância por câmeras. Os homens tradicionais inverteram o sistema de monitoramento para obter mais recompensas, bloqueando a visão da câmera, um comportamento que indica busca por recompensa. Os Agentes Mona seguem uma arquitetura alvo, operando de forma consistente sem explorar vulnerabilidades do sistema.
O desempenho da Mona mostra que esta é uma boa solução para deixar de receber diversas recompensas. Ao focar em recompensas imediatas e incorporar testes liderados por pessoas, Mona alinha o comportamento do agente com os objetivos das pessoas enquanto obtém resultados em ambientes complexos. Embora não seja amplamente aplicável, Mona é um grande passo em frente na superação de tais desafios de alinhamento, especialmente para sistemas avançados de IA que muitas vezes utilizam técnicas de múltiplas etapas.
No geral, o trabalho do Google Deepmind enfatiza a importância de formas eficazes de reforçar a aprendizagem para reduzir o risco associado ao hacking relacionado com recompensas. Mona fornece uma estrutura clara para medir segurança e desempenho, abrindo caminho para sistemas de IA confiáveis e confiáveis no futuro. Os resultados enfatizam a necessidade de mais testes de métodos que incorporem eficazmente o julgamento humano, para garantir que os sistemas de IA estejam sempre alinhados com os objetivos pretendidos.
Confira papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Meio teimoso então junte-se ao nosso Estação Telegráfica e LinkedIn Gro assunto. Não se esqueça de se juntar ao nosso Subreddit de 70 mil + ml.
🚨 [Recommended Read] Nebius AI Studio está se expandindo com modelos de visão, novos modelos de linguagem, incorporação e lora (Criado)
Nikhil é um estudante mentor na Marktechpost. Ele está cursando graduação combinada em materiais aplicados no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que está constantemente pesquisando aplicações em áreas como biomoustoments e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
📄 Conheça 'elevação': ferramenta independente de gerenciamento de projetos (patrocinada)


