
O processamento de linguagem natural (PNL) tem experimentado um rápido progresso, com modelos linguísticos de larga escala (LLMs) sendo usados para resolver uma variedade de problemas desafiadores. Entre as diversas aplicações dos LLMs, a resolução de problemas matemáticos surgiu como um teste às suas capacidades de pensamento. Esses modelos mostraram um desempenho impressionante em benchmarks específicos de matemática, como o GSM8K, que mede sua capacidade de resolver problemas de matemática nas séries escolares. No entanto, há um debate contínuo sobre se esses modelos realmente entendem conceitos estatísticos ou usam padrões nos dados de treinamento para gerar respostas corretas. Isto levou à necessidade de avaliações aprofundadas para compreender a extensão das suas capacidades de raciocínio ao lidar com problemas complexos e interligados.
Apesar do sucesso nos benchmarks matemáticos existentes, os pesquisadores identificaram um problema crítico: muitos LLMs precisam demonstrar um pensamento consistente quando confrontados com questões complexas e integrativas. Embora os benchmarks padrão envolvam a resolução de problemas individuais de forma independente, as situações do mundo real muitas vezes exigem a compreensão das relações entre vários problemas, onde a resposta a uma pergunta deve ser usada para resolver outra. Os testes convencionais não representam adequadamente tais situações, que se concentram apenas na resolução de problemas diversos. Isso cria uma lacuna entre altas pontuações de benchmark e a aplicabilidade prática dos LLMs em tarefas complexas que exigem pensamento passo a passo e compreensão profunda.
Pesquisadores da Mila, Google DeepMind e Microsoft Research introduziram um novo método de avaliação chamado “Matemática Composicional do Ensino Fundamental (GSM)”. Este método envolve a combinação de dois problemas matemáticos diferentes de modo que a solução do primeiro problema seja o inverso do segundo problema. Usando este método, os pesquisadores podem analisar as capacidades dos LLMs para lidar com dependências entre consultas, um conceito que precisa ser capturado adequadamente pelos benchmarks existentes. A abordagem GSM Composicional fornece um teste mais abrangente das habilidades de pensamento dos LLMs, apresentando problemas interligados que exigem que o modelo transporte informações de um problema para outro, tornando necessário resolver ambos corretamente para um resultado bem-sucedido.
Experimentos foram realizados usando vários LLMs, incluindo modelos ponderados abertos, como LLAMA3, e modelos ponderados fechados, como as famílias GPT e Gemini. O estudo incluiu três conjuntos de testes: a classificação de teste GSM8K original, uma versão modificada do GSM8K na qual algumas variáveis foram alteradas e um novo conjunto de testes Composicional GSM, cada um contendo 1.200 exemplos. Os modelos foram testados usando um método de prompt de 8 itens, onde foram dados vários exemplos antes de serem solicitados a resolver problemas de composição. Este método permitiu aos investigadores avaliar de forma completa o desempenho dos modelos, tendo em conta a sua capacidade de resolução de problemas individualmente e em contexto de integração.
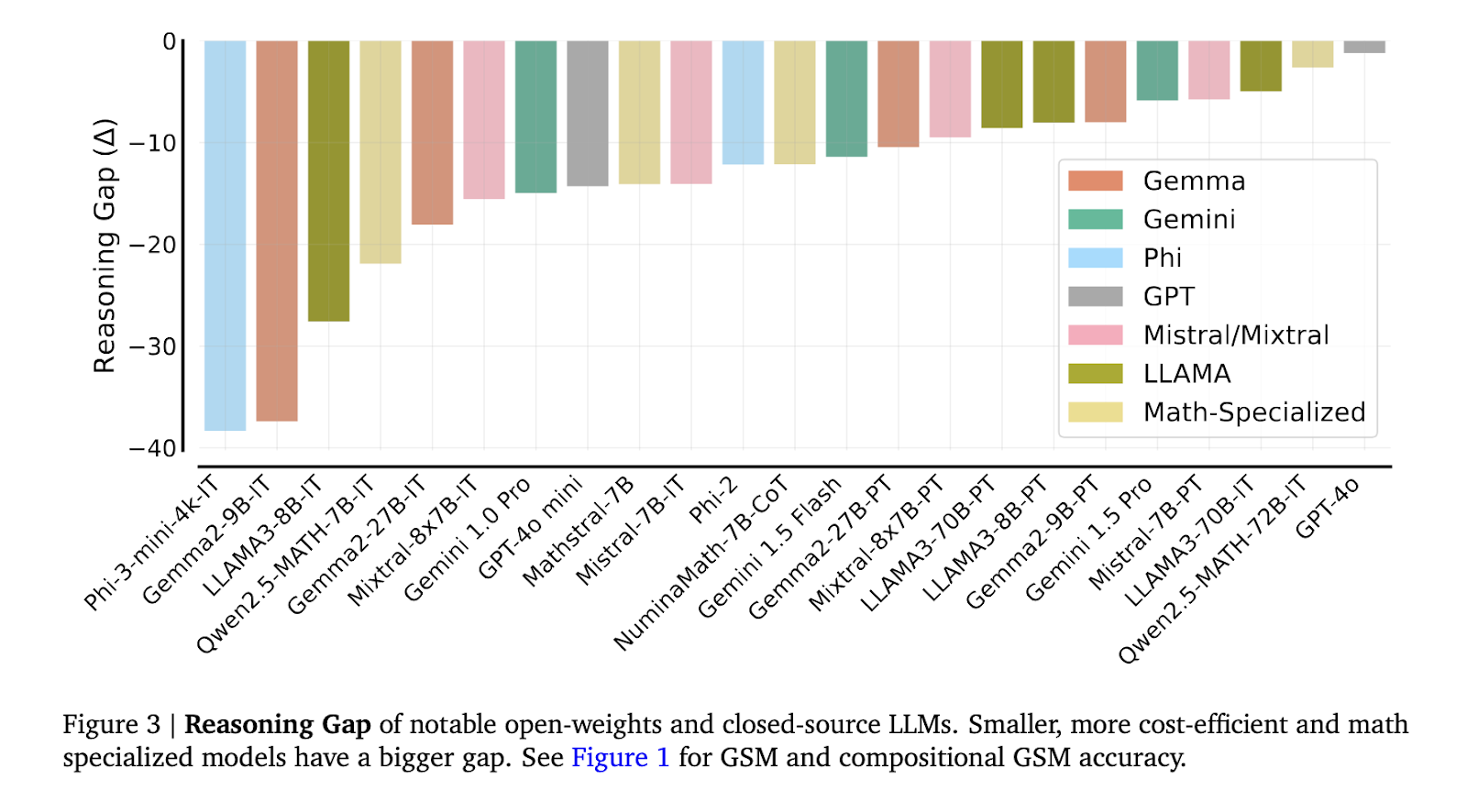
Os resultados mostraram uma enorme lacuna nas habilidades de pensamento. Por exemplo, modelos de baixo custo, como o GPT-4o mini, mostraram uma lacuna de imagem 2 a 12 vezes pior no GSM inovador em comparação com o seu desempenho no GSM8K padrão. Além disso, modelos matemáticos especializados, como o Qwen2.5-MATH-72B, que alcançou mais de 80% de precisão em questões de nível competitivo do ensino médio, só conseguiram resolver menos de 60% dos problemas de matemática das séries escolares. Este grande declínio sugere que é necessário mais do que formação matemática especializada para desenvolver modelos de tarefas cognitivas suficientemente multi-etapas. Além disso, observou-se que modelos como LLAMA3-8B e Mistral-7B, apesar de obterem pontuações altas para problemas individuais, apresentaram diminuição significativa quando foi necessário vincular respostas entre problemas relacionados.
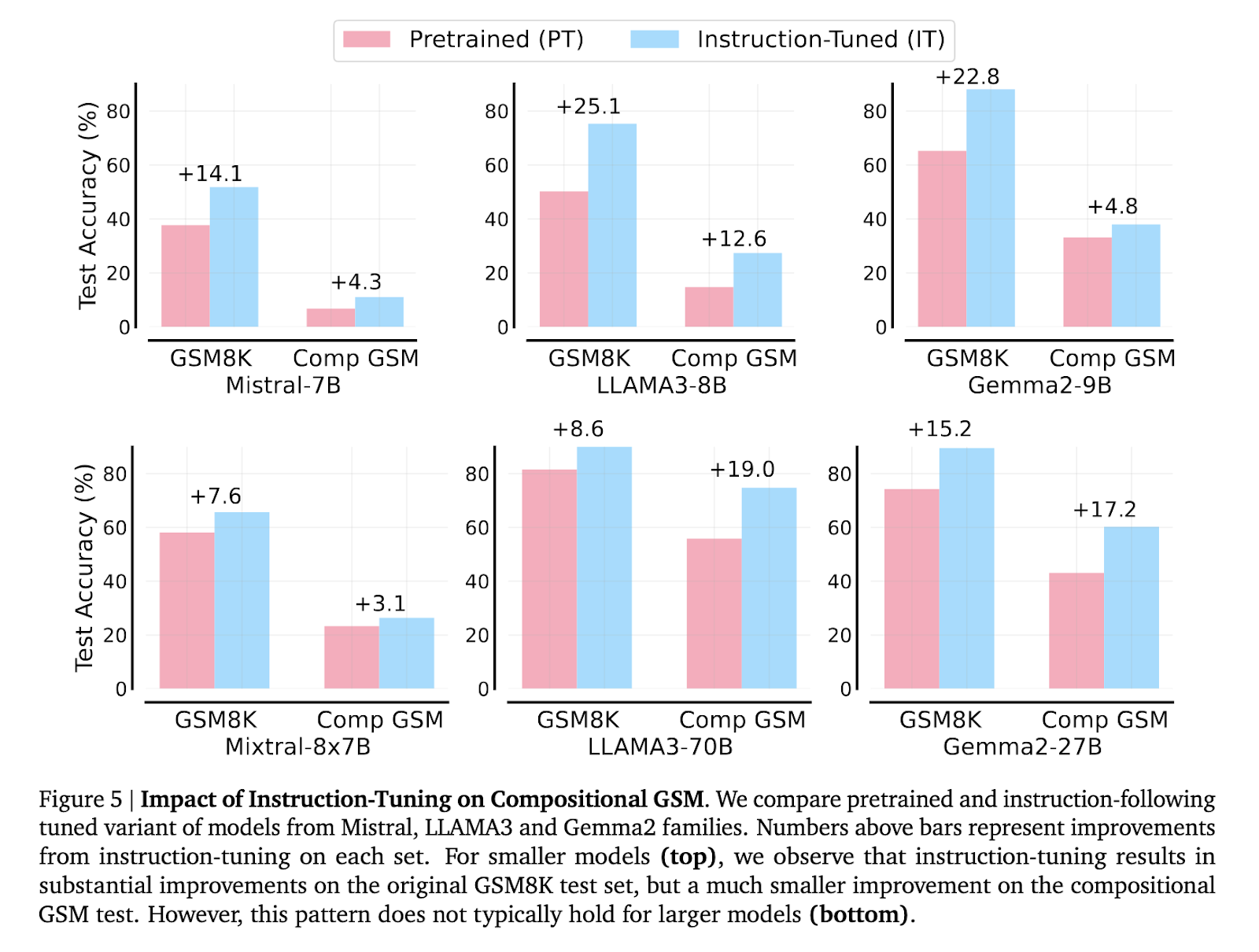
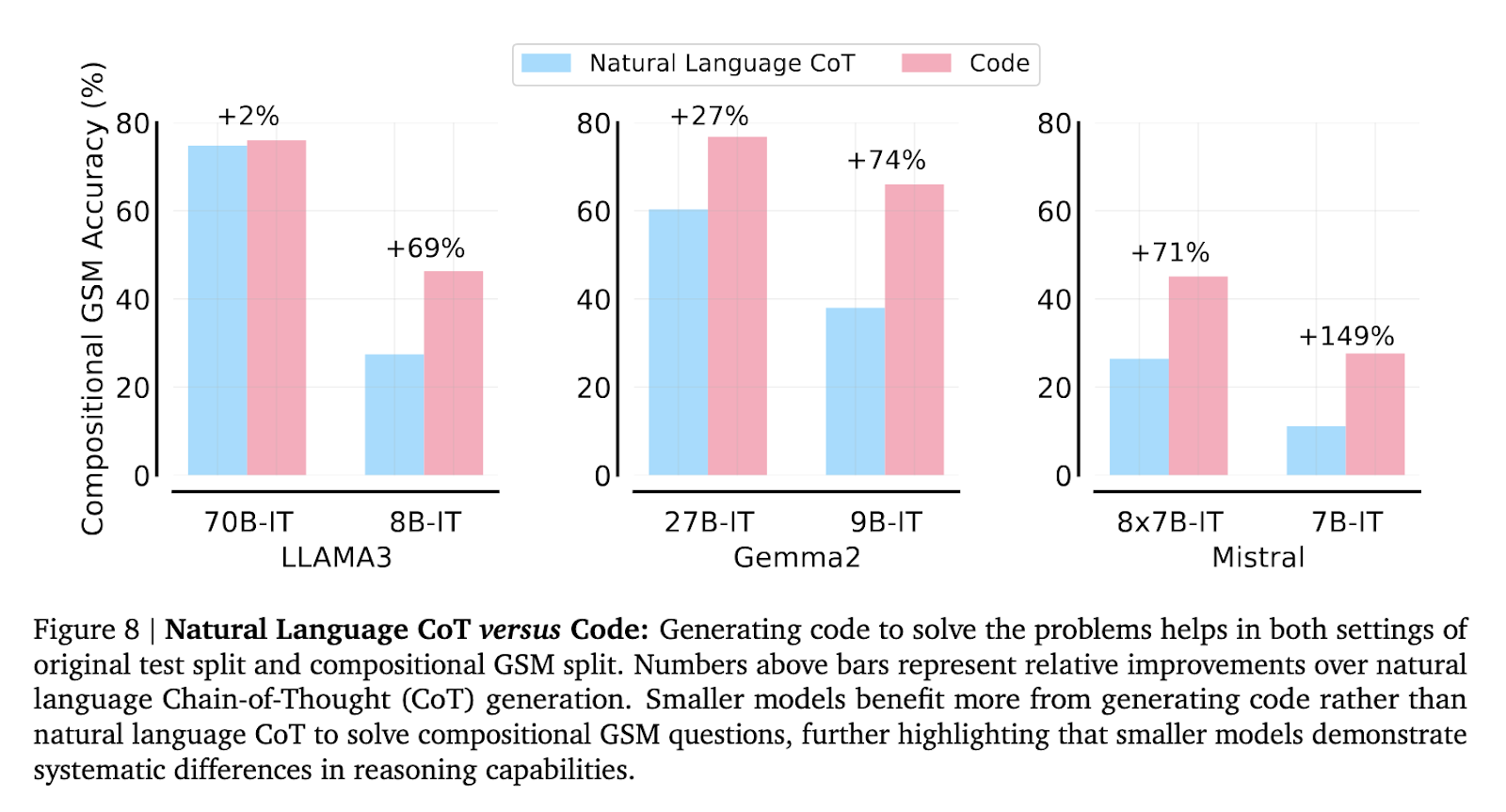
Os pesquisadores também examinaram o impacto da otimização de instruções e da geração de código no desempenho dos modelos. O ajuste das instruções melhorou os resultados dos submodelos nos problemas padrão GSM8K, mas levou apenas a uma pequena melhoria na composição do GSM. Entretanto, a geração de soluções codificadas em vez de utilizar linguagem natural levou a melhorias de 71% a 149% em alguns submodelos na inovação GSM. Esta descoberta mostra que embora a geração de código ajude a reduzir a lacuna de raciocínio, ela não a elimina, e persistem diferenças sistemáticas na capacidade de raciocínio entre os vários modelos.
Uma análise das lacunas lógicas revelou que a degradação do desempenho não se deveu ao vazamento do conjunto de testes, mas sim à interferência causada por contexto extra e lógica de segundo salto deficiente. Por exemplo, quando modelos como LLAMA3-70B-IT e Gemini 1.5 Pro tiveram que resolver a segunda questão usando a primeira resposta, muitas vezes precisaram usar a solução com precisão, levando a respostas finais incorretas. Esse fenômeno, denominado lacuna de raciocínio do segundo salto, era mais proeminente em modelos pequenos, que tendiam a ignorar detalhes importantes na resolução de problemas complexos.
O estudo destaca que os atuais LLMs, independentemente do seu desempenho em benchmarks padrão, ainda enfrentam dificuldades com tarefas de pensamento integrado. O benchmark Compositional GSM apresentado no estudo fornece uma ferramenta importante para avaliar as habilidades de pensamento dos LLMs além da resolução de problemas. Estes resultados sugerem que técnicas robustas de treinamento e projetos de benchmark são necessários para melhorar as capacidades computacionais desses modelos, tornando-os mais eficientes em situações complexas de resolução de problemas. Este estudo enfatiza a importância de reavaliar os métodos de avaliação existentes e priorizar o desenvolvimento de modelos capazes de raciocínio em várias etapas.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Interessado em promover sua empresa, produto, serviço ou evento para mais de 1 milhão de desenvolvedores e pesquisadores de IA? Vamos trabalhar juntos!
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.


![Laboratórios da Floresta Negra revelaram FLUX1.1 [pro] e BFL API: a solução definitiva para profissionais criativos que buscam geração de imagens de alto desempenho e integração de API escalonável](https://i0.wp.com/www.marktechpost.com/wp-content/uploads/2024/10/Screenshot-2024-10-04-at-10.28.06-AM.png?w=320&resize=320,200&ssl=1 "Laboratórios da Floresta Negra revelaram FLUX1.1 [pro] e BFL API: a solução definitiva para profissionais criativos que buscam geração de imagens de alto desempenho e integração de API escalonável")