: uma estrutura integrada de aprendizado de máquina para geração condicional de modelos distribuídos com melhor desempenho e flexibilidade em todos os domínios")
Os modelos de difusão surgiram como ferramentas revolucionárias em aprendizado de máquina, fornecendo recursos incomparáveis para gerar amostras de alta qualidade em todos os domínios, como fusão de imagens, estrutura molecular e geração de áudio. Esses modelos funcionam refinando iterativamente os dados ruidosos para corresponder à distribuição desejada, usando procedimentos avançados de remoção de ruído. Com seu crescimento em muitos conjuntos de dados e aplicabilidade em diversas tarefas, os modelos de distribuição são cada vez mais considerados como base para modelagem generativa. No entanto, a sua utilização prática na geração condicional continua a ser um grande desafio, especialmente quando a saída deve satisfazer certos critérios definidos pelo utilizador.
Um grande obstáculo na modelagem de distribuição reside na geração condicional, onde os modelos devem combinar resultados para corresponder a atributos como rótulos, pontos fortes ou recursos sem reciclagem adicional. Os métodos tradicionais, incluindo classificação baseada em classificador e classificador livre, geralmente envolvem o treinamento de preditores especiais para cada sinal de parada. Embora eficientes, esses métodos são computacionalmente intensivos e inflexíveis, especialmente quando aplicados a novos conjuntos de dados ou tarefas. A ausência de quadros unificados ou de parâmetros de referência sistemáticos dificulta a sua adoção generalizada. Isto cria uma necessidade crítica de métodos eficientes e flexíveis para estender o uso de modelos de distribuição a aplicações do mundo real.
As abordagens existentes baseadas em treinamento dependem fortemente de preditores condicionais pré-treinados incorporados no processo de extração de ruído. Por exemplo, a orientação baseada em fase utiliza classificadores ruidosos, enquanto a orientação livre incorpora sinais de estado diretamente no treinamento do modelo de distribuição. Embora sejam sólidos em teoria, esses métodos requerem recursos computacionais significativos e esforços de reciclagem para cada novo cenário. Além disso, os métodos existentes muitas vezes precisam de lidar com situações complexas ou bem caracterizadas, como evidenciado pelo seu sucesso limitado em conjuntos de dados como o CIFAR10 ou situações que requerem reprodução geral sem distribuição. É evidente a necessidade de métodos que vão além da reciclagem, mantendo o alto desempenho.
Pesquisadores da Universidade de Stanford, da Universidade de Pequim e da Universidade de Tsinghua introduziram uma nova estrutura chamada Guia de treinamento gratuito (TFG). Esta inovação algorítmica integra métodos de fabricação condicional existentes em um único ambiente de design, eliminando a necessidade de retreinamento e melhorando a flexibilidade e o desempenho. O TFG reformula a geração condicional como um problema de otimização de hiperparâmetros dentro de uma estrutura unificada, que pode ser facilmente aplicada a vários aplicativos. Ao combinar ferramentas como orientação direta, orientação de diversidade e modelagem dinâmica transparente, o TFG expande o espaço de design disponível para gerar resultados sem treinamento condicional, fornecendo uma alternativa robusta aos métodos tradicionais.
O TFG atinge sua eficiência agilizando o processo de difusão usando parâmetros mais elevados do que o treinamento especializado. O método utiliza técnicas avançadas como a reamostragem, onde o modelo reobjetiva e regenera as amostras para melhorar seu alinhamento com as estruturas alvo. Recursos importantes, como modelagem dinâmica difusa, adicionam ruído às funções direcionais para melhorar as previsões em áreas densas, enquanto a diversidade incorpora informações secundárias para melhorar a estabilidade do gradiente. Ao combinar esses recursos, o TFG simplifica o processo de fabricação condicional e permite seu uso em domínios anteriormente inacessíveis, incluindo direcionamento de rótulo fino e fabricação molecular.
O desempenho da estrutura foi rigorosamente verificado por meio de medições abrangentes em sete modelos de distribuição e 16 tarefas, abrangendo 40 metas. O TFG proporcionou uma melhoria média de 8,5% no desempenho em relação aos métodos existentes. Por exemplo, em tarefas de orientação de rótulos CIFAR10, o TFG alcançou 77,1% de precisão em comparação com 52% dos métodos anteriores sem redundância. No ImageNet, a direção do rótulo TFG atingiu uma precisão de 59,8%, o que mostra sua superioridade no tratamento de conjuntos de dados desafiadores. Seus resultados na otimização da estrutura molecular foram particularmente notáveis, com uma melhoria de 5,64% no erro absoluto em relação aos métodos concorrentes. O TFG também teve um desempenho muito bom em tarefas multimodais, como orientar a geração de imagens faciais com base em combinações de sexo e idade ou cabelo, superando os modelos existentes e minimizando o viés do conjunto de dados.
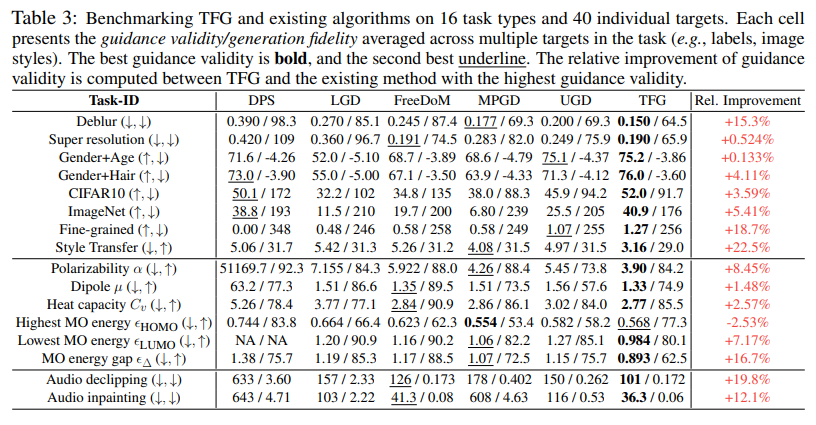
Principais conclusões do estudo:
- Benefícios de eficiência: O TFG elimina a necessidade de reciclagem, reduzindo significativamente os custos computacionais e mantendo alta precisão em todas as operações.
- Desempenho Extenso: A estrutura mostrou desempenho superior em diferentes domínios, incluindo CIFAR10 (77,1% de precisão), ImageNet (59,8% de precisão) e geração de moléculas (5,64% de melhoria no MAE).
- Referências fortes: Testes abrangentes em sete modelos, 16 funções e 40 alvos estabelecem um novo padrão para testar modelos de distribuição.
- Novas técnicas: Este processo inclui a direção da média e da variância, modelagem clara de variáveis e refinamento iterativo para melhorar a qualidade da amostra.
- Reduzindo o preconceito: Lidou com sucesso com o desequilíbrio do conjunto de dados em tarefas multimodais, alcançando 46,7% de precisão para classes raras como “cabelos masculinos + loiros”.
- Design Escalável: o método de otimização de hiperparâmetros garante escalabilidade para novas tarefas e conjuntos de dados sem comprometer o desempenho.

Em conclusão, o TFG representa um avanço importante na modelagem de distribuição, abordando limitações importantes na produção condicional. A integração de vários métodos em uma única estrutura facilita a adaptação de modelos de distribuição a diversas tarefas sem treinamento adicional. Seu desempenho nos domínios visual, auditivo e molecular destaca sua versatilidade e potencial como ferramenta fundamental de aprendizado de máquina. O estudo desenvolve modelos de distribuição de última geração e estabelece uma referência sólida para pesquisas futuras, abrindo caminho para uma modelagem de produção mais acessível e eficiente.
Confira Papel aqui. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Conferência Virtual GenAI gratuita com. Meta, Mistral, Salesforce, Harvey AI e mais. Junte-se a nós em 11 de dezembro para este evento de visualização gratuito para aprender o que é necessário para construir grande com pequenos modelos de pioneiros em IA como Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face e muito mais.
Sana Hassan, estagiária de consultoria na Marktechpost e estudante de pós-graduação dupla no IIT Madras, é apaixonada pelo uso de tecnologia e IA para enfrentar desafios do mundo real. Com um profundo interesse em resolver problemas do mundo real, ele traz uma nova perspectiva para a intersecção entre IA e soluções da vida real.
🐝🐝 Leia este relatório de pesquisa de IA da Kili Technology 'Avaliação de vulnerabilidade de um modelo de linguagem grande: uma análise comparativa de métodos de passagem vermelha'


