
Os modelos linguísticos em larga escala (LLMs) revolucionaram campos que vão desde o atendimento ao cliente até a assistência médica, sincronizando a produção da máquina com os valores humanos. Os modelos de recompensa (MRs) desempenham um papel importante neste alinhamento, agindo como um ciclo de feedback no qual os modelos são direcionados para fornecer as respostas que as pessoas escolhem. Embora muitos desenvolvimentos tenham melhorado estes modelos de inglês, existe um desafio mais amplo na adaptação dos RM a contextos multilingues. Essa adaptabilidade é importante, dada a base global de usuários que depende fortemente de LLMs em todos os idiomas diferentes para uma variedade de tarefas, incluindo informações diárias, diretrizes de segurança e conversas cruzadas.
Um problema chave no desenvolvimento do LLM reside na adaptação dos RMs para funcionarem de forma consistente em todas as línguas. Os modelos de recompensa tradicionais, treinados principalmente em dados do idioma inglês, muitas vezes precisam ser alcançados quando estendidos a outros idiomas. Esta limitação cria uma lacuna de desempenho que limita a eficácia destes modelos, especialmente para utilizadores que não falam inglês e que dependem de modelos linguísticos para obter respostas precisas, culturalmente relevantes e seguras. A actual lacuna na capacidade de RM sublinha a necessidade de medições multilingues e ferramentas de avaliação para garantir que os modelos servem o público global de forma mais eficaz.
As ferramentas de teste existentes, como o RewardBench, concentram-se em testar modelos em inglês em habilidades gerais, como raciocínio, desempenho de conversação e segurança do usuário. Embora este parâmetro de referência tenha estabelecido uma base para a avaliação de MR em inglês, deve abordar as dimensões multilingues necessárias para uma utilização generalizada. O RewardBench, do jeito que está, não baixa totalmente os trabalhos que incluem tradução ou respostas interculturais. Isto destaca uma área importante para melhoria, uma vez que a tradução precisa e as respostas culturalmente alinhadas são a base de uma experiência de utilizador significativa em diferentes idiomas.
Pesquisadores da Writingsonic, Allen Institute for AI, Bangladesh University of Engineering and Technology, ServiceNow, Cohere For AI Community, Cohere e Cohere For AI desenvolveram IM-RewardBenché um benchmark de teste multilíngue projetado para testar RMs em um espectro de 23 idiomas. O conjunto de dados, que inclui 2.870 sessões populares, inclui idiomas de oito escritas exclusivas e famílias multilíngues, proporcionando um ambiente de teste robusto para o multilinguismo. O RewardBench visa preencher a lacuna nos testes de RM combinando idiomas de diferentes domínios de amostra, trazendo novos insights sobre o desempenho dos LLMs em outros idiomas além do inglês em áreas-chave como segurança, raciocínio, capacidade de conversação e tradução.
O método M-RewardBench avalia completamente modelos de recompensa multilíngues, usando tradução gerada por máquina e validação humana para precisão. Os pesquisadores criaram subconjuntos baseados na dificuldade da tarefa e na dificuldade do idioma, traduzindo e editando dados do RewardBench em 23 idiomas. O benchmark inclui seções de Conversas, Conversas Difíceis, Segurança e Consultas para testar as habilidades de RM em ambientes de conversação complexos e cotidianos. Para medir o impacto da qualidade da tradução, a equipa de investigação utilizou dois sistemas de tradução, Google Translate e NLLB 3.3B, mostrando que uma tradução melhorada pode melhorar significativamente o desempenho do RM em até 3%.
A pesquisa revelou diferenças significativas no desempenho, particularmente entre contextos ingleses e não ingleses. Os modelos de recompensa generativos, como o GPT-4-Turbo, tiveram um desempenho relativamente bom, atingindo uma pontuação de precisão de 83,5%, enquanto outros modelos de RM, como os modelos baseados em categorias, tiveram dificuldades para se adaptar a tarefas multilíngues. Os resultados mostram que os modelos generativos são mais adequados para o alinhamento multilíngue, embora permaneça uma queda média de desempenho de 8% ao passar de tarefas em inglês para tarefas não inglesas. Além disso, o desempenho dos modelos varia significativamente de acordo com o idioma, com idiomas com altos recursos, como o português, alcançando maior precisão (68,7%) em comparação com idiomas com poucos recursos, como o árabe (62,8%).
Vários insights importantes surgiram do M-RewardBench, enfatizando áreas para melhoria no desenvolvimento de RM multilíngue. Por exemplo, os RM mostraram um nível mais elevado de consistência de rótulos entre línguas em tarefas de raciocínio do que em contextos de conversação tradicionais, sugerindo que certos tipos de conteúdo podem ser passíveis de contextos multilingues. Este insight aponta para a necessidade de benchmarks especializados dentro do M-RewardBench para testar diferentes tipos de conteúdo, especialmente à medida que os modelos se expandem para idiomas sub-representados com estruturas linguísticas únicas.
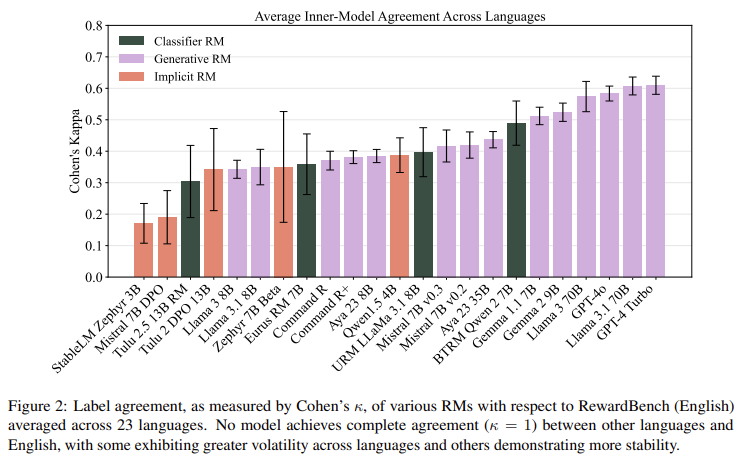
Principais conclusões do estudo:
- Escopo do conjunto de dados: IM-RewardBench oferece suporte a 23 idiomas, oito famílias de idiomas e 2.870 preferências, tornando-o uma das ferramentas de teste de RM mais multilíngues disponíveis.
- Vagas de emprego: Os RM produtivos alcançaram pontuações médias mais altas, com significativos 83,5% em ambientes multilíngues, mas o desempenho geral caiu para 13% em tarefas que não falam inglês.
- Certas mudanças de trabalho: As tarefas Chat-Hard apresentaram uma diminuição significativa no desempenho (5,96%), enquanto as tarefas de raciocínio tiveram a menor diminuição, destacando que a complexidade da tarefa afeta a precisão do RM em todos os idiomas.
- Impacto da qualidade da tradução: A tradução de alta qualidade melhorou a precisão do RM em até 3%, ressaltando a necessidade de métodos de tradução refinados em contextos multilíngues.
- Concordando sobre os idiomas comumente usados: Os modelos tiveram melhor desempenho em idiomas com altos recursos (por exemplo, português, 68,7%) e mostraram problemas de consistência em idiomas com poucos recursos, como o árabe (62,8%).
- Contribuição de referência: O RewardBench fornece uma nova estrutura para avaliar LLMs em outros idiomas além do inglês, estabelecendo as bases para desenvolvimentos futuros no alinhamento de RM em contextos culturais e linguísticos.

Concluindo, a pesquisa baseada no M-RewardBench mostra a importante necessidade de os modelos linguísticos serem mais relevantes para as preferências das pessoas em todos os idiomas. Ao fornecer uma escala otimizada para contextos multilíngues, este estudo estabelece as bases para desenvolvimentos futuros na modelagem de prêmios, particularmente no tratamento de diferenças culturais e na garantia de consistência linguística. As descobertas reforçam a importância do desenvolvimento de RMs que atendam de forma confiável a uma base global de usuários, onde a diversidade linguística e a qualidade da tradução são fundamentais para o desempenho.
Confira Artigo, Projeto e GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Upcoming Live Webinar- Oct 29, 2024] A melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (atualizado)
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre o público.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


