
Um grande desafio na recuperação de informação hoje é determinar a maneira mais eficiente de pesquisar o vetor vizinho mais próximo, especialmente com a crescente complexidade de modelos de recuperação densos e esparsos. Os trabalhadores devem navegar por uma ampla gama de opções de apontamento e métodos de detecção, incluindo gráficos HNSW (Hierarchical Navigable Small-World), ponteiros planos e ponteiros invertidos. Esses métodos oferecem diferentes compensações em termos de velocidade, escalabilidade e qualidade dos resultados de recuperação. À medida que os conjuntos de dados se tornam maiores e mais complexos, a ausência de diretrizes operacionais claras torna difícil para os profissionais desenvolverem os seus sistemas, especialmente aplicações que exigem alto desempenho, como motores de pesquisa e aplicações baseadas em IA, como sistemas de resposta a perguntas.
Tradicionalmente, as pesquisas de vizinhos mais próximos são tratadas usando três métodos principais: índices HNSW, índices planos e índices invertidos. Os índices HNSW são frequentemente usados por sua eficiência e velocidade em grandes tarefas de recuperação, especialmente com vetores densos, mas são computacionalmente intensivos e requerem um tempo de indexação significativo. Os índices simples, embora precisos em seus resultados de recuperação, são ineficazes para grandes conjuntos de dados devido ao desempenho lento da consulta. Modelos de recuperação finos, como BM25 ou SPLADE++ ED, dependem de índices invertidos e podem funcionar bem em determinadas situações, mas muitas vezes carecem da rica compreensão semântica oferecida pelos modelos de recuperação densos. A principal limitação de todos esses métodos é que nenhum deles é universalmente aplicável e cada método oferece diferentes pontos fortes e fracos dependendo do tamanho do conjunto de dados e da recuperação.
Pesquisadores da Universidade de Waterloo apresentam uma avaliação abrangente do trade-off entre indicadores HNSW, planos e invertidos em modelos de recuperação densos e esparsos. Este estudo fornece uma análise detalhada do desempenho desses métodos, medido em tempo de índice, velocidade de consulta (QPS) e qualidade de recuperação (nDCG@10), usando o conjunto de dados de benchmark BEIR. Os pesquisadores pretendem fornecer conselhos práticos e baseados em dados sobre o uso ideal de cada método com base no tamanho do conjunto de dados e nas necessidades de aquisição. Suas descobertas mostram que o HNSW funciona melhor para conjuntos de dados de grande escala, enquanto os índices planos são mais adequados para conjuntos de dados pequenos devido à sua simplicidade e resultados diretos. Além disso, o estudo explora os benefícios do uso de técnicas de escalonamento para melhorar a escalabilidade e a velocidade do processo de recuperação, o que proporciona um impulso significativo para os profissionais que trabalham com grandes conjuntos de dados.
A configuração do teste usa o benchmark BEIR, uma coleção de 29 conjuntos de dados projetados para ilustrar desafios de recuperação de informações do mundo real. O modelo de recuperação densa utilizado é o BGE (Base General Embeddings), com SPLADE++ ED e BM25 atuando como bases de recuperação esparsas. O experimento se concentra em dois tipos de índices de recuperação densos: HNSW, que constrói estruturas de pesquisa de vizinho mais próximo baseadas em gráficos, e índices planos, que dependem de pesquisa de força bruta. Os indicadores invertidos são usados para vários modelos de recuperação. Os testes foram realizados utilizando a biblioteca de busca Lucene, com configuração específica como M=16 para HNSW. O desempenho é avaliado usando métricas importantes, como nDCG@10 e QPS, e o desempenho da consulta é testado sob duas condições: consultas em cache (codificação de consulta pré-gerada) e codificação de consulta em tempo real baseada em ONNX.
Os resultados revelam que, para pequenos conjuntos de dados (menos de 100 mil documentos), os índices planos e o HNSW apresentam desempenho semelhante em termos de velocidade de consulta e qualidade de recuperação. No entanto, à medida que o tamanho dos conjuntos de dados aumenta, os índices HNSW começam a superar os índices planos, especialmente em termos de velocidade de avaliação de consultas. Para grandes conjuntos de dados que excedem 1 milhão de documentos, os índices HNSW fornecem as consultas por segundo (QPS) mais altas, com apenas uma ligeira diminuição na qualidade de recuperação (nDCG@10). Ao lidar com conjuntos de dados de mais de 15 milhões de documentos, os índices HNSW mostram melhorias significativas na velocidade, mantendo uma precisão de recuperação aceitável. Técnicas de escalabilidade que melhoram o desempenho, especialmente para grandes conjuntos de dados, proporcionam aumentos significativos na velocidade de consulta sem degradação significativa na qualidade. No geral, os métodos de recuperação densa usando HNSW parecem ser mais eficientes e eficazes do que os modelos de recuperação esparsa, especialmente para aplicações grandes que exigem alto desempenho.
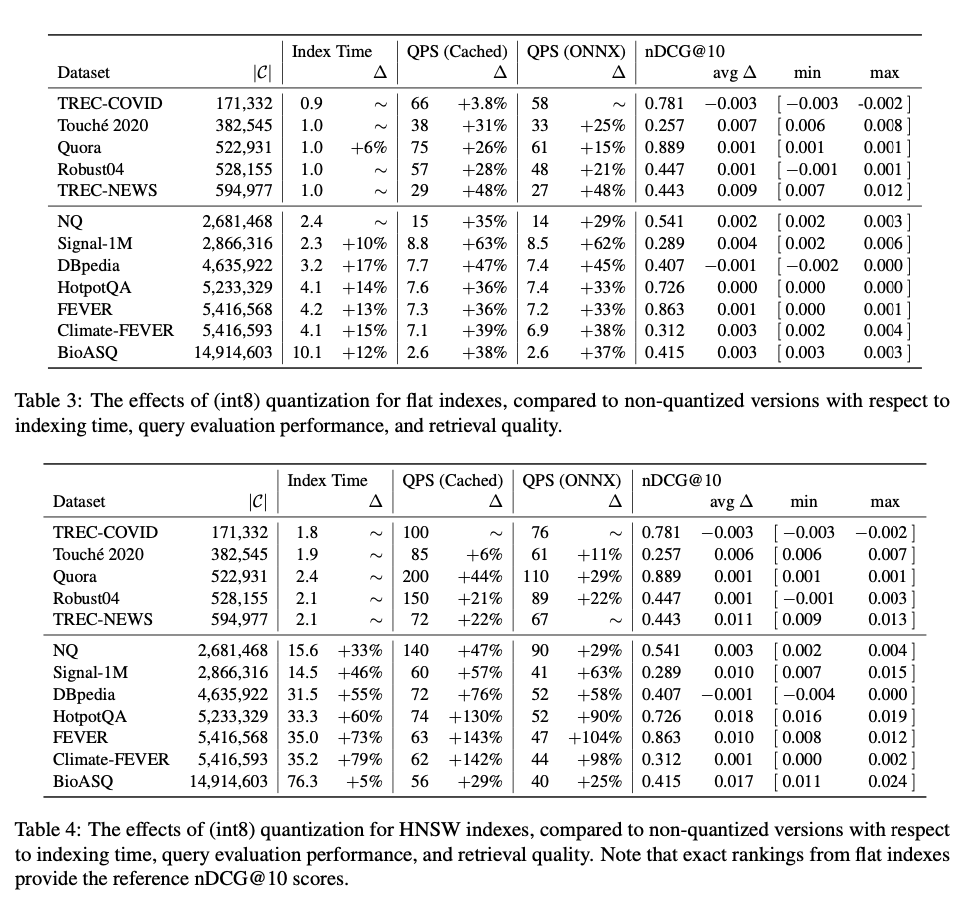
Este estudo fornece orientação valiosa para os profissionais na identificação de indicadores densos e esparsos, fornecendo uma avaliação abrangente do trade-off entre indicadores HNSW, planos e invertidos. As descobertas sugerem que os índices HNSW são adequados para grandes tarefas de descoberta devido à sua eficiência no tratamento de consultas, enquanto os índices planos são adequados para pequenos conjuntos de dados e prototipagem rápida devido à sua simplicidade e precisão. Ao fornecer recomendações com base empírica, este trabalho contribui significativamente para a compreensão e desenvolvimento de sistemas modernos de recuperação de informação, ajudando os médicos a tomar decisões informadas para aplicações de pesquisa orientadas por IA.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Aswin AK é consultor da MarkTechPost. Ele está cursando seu diploma duplo no Instituto Indiano de Tecnologia, Kharagpur. Ele é apaixonado por ciência de dados e aprendizado de máquina, o que traz consigo uma sólida formação acadêmica e experiência prática na solução de desafios de domínio da vida real.
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
: um novo método de IA que remove seletivamente logs infiéis para melhorar a precisão da resposta em modelos de percepção de linguagem em grande escala")

