: Novel Ai Como melhorar o raciocínio do LLM para consultar o aprendizado formal")
Os métodos tradicionais de treinamento de modelos multilíngues dependem muito de boas orientações, onde os modelos estão aprendendo imitando respostas apropriadas. Enquanto trabalha com serviços básicos, essa opção é controlada automaticamente com o poder de habilidades mais profundas de desenvolvimento de habilidades. À medida que os aplicativos do Apêndito continuam a aparecer, há uma necessidade crescente de modelos que podem produzir respostas e avaliar seus resultados para garantir a precisão e a admissão razoável.
As maiores limitações dos métodos de treinamento tradicionais são basear -se nas implicações e proteger os modelos na análise sensível das respostas. Como resultado, as estratégias mais baseadas não apresentaram profundidades lógicas que enfrentam problemas complexos de consulta, e os efeitos produzidos são frequentemente semelhantes às respostas apropriadas. Mais importante ainda, os tamanhos de dados não levam automaticamente à qualidade aprimorada dos trens de impacto negativo gerado para modelos grandes. Esses desafios chamam a atenção para a refeição de vários métodos que melhoram o pensamento melhor, em vez de cultivar compuções.
As soluções existentes estão tentando reduzir esses problemas usando a validade da aprendizagem e ordem da instrução. O reforço da resposta das pessoas mostrou resultados promissores, mas requer grandes recursos computacionais. Uma maneira inclui críticas – quando os modelos testam os resultados por erros, mas isso geralmente falta. Além do desenvolvimento, muitos métodos de treinamento ainda estão focados em volumes de dados maiores, em vez de melhorar seu desempenho básico, o que restringe seu desempenho na resolução de problemas.
A equipe de pesquisa da Universidade de Waterloo, da Universidade Carnegie Mellon e da Instituição vetorial propôs críticas críticas (CFT) como uma outra maneira de orientar uma boa direção. Esse método muda se concentra no aprendizado baseado em imitação em profundidade, onde os modelos são treinados para explorar e a análise de respostas em vez de repeti -las. Para conseguir isso, os pesquisadores criam um conjunto de dados de 50.000 Critaset usando o GPT-4O, os modelos que permitem identificar erros de resposta e aumentar a melhoria. Essa abordagem funciona bem para domínios que exigem o pensamento planejado, como resolver problemas matemáticos.
Os métodos de CFT em torno dos modelos de treinamento usam coltiques organizadas fixadas em vez de ambos os entrevistados. Durante o treinamento, os modelos apresentados para a primeira pergunta e resposta, seguidos de críticas testando a precisão da resposta e da coesão lógica. Ao aumentar o modelo para expressar críticas, os pesquisadores promovem um profundo processo de análise que desenvolve habilidades de consulta. Ao contrário do tradicional tradicional, onde os modelos são recompensados simplesmente gerando as respostas corretas, a CFT prioriza para cobrir os erros e elevar melhorias, levando a mais expansão e descrições.
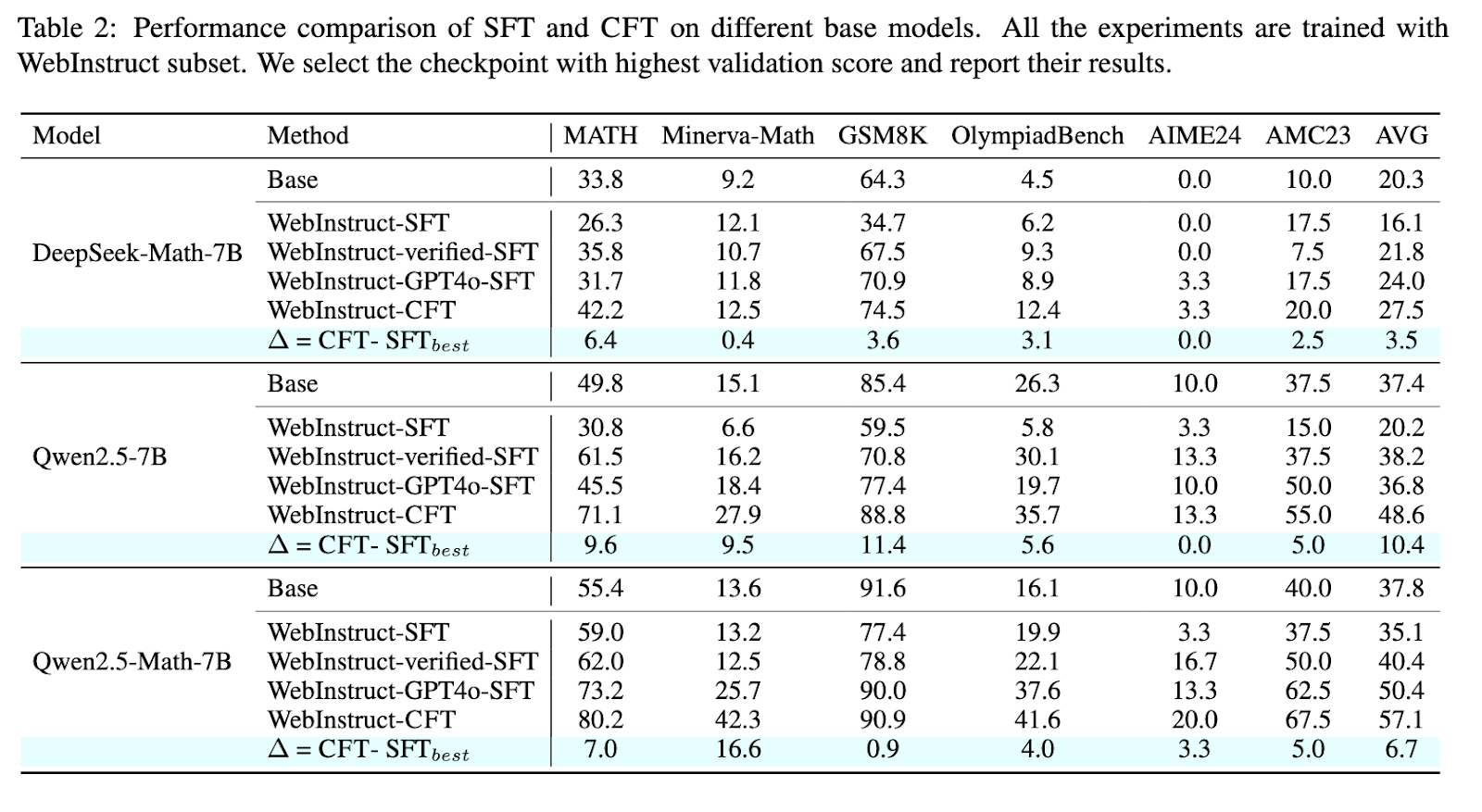
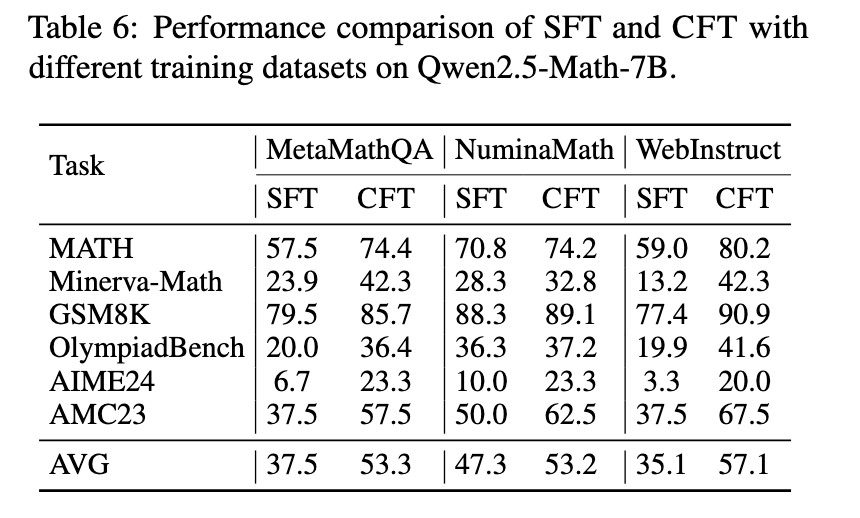
Os resultados do teste indicam que os ciclos estão mudando consistentemente aqueles treinados usando métodos normais. Os investigadores procuram estatísticas numéricas, incluindo estatísticas, Minersava-Math e Olympikidbench. Os modelos são treinados para usar a CFT para indicar o desenvolvimento de 4-10% de desempenho significativo sobre seus preços designados. Especialmente, QWEN2.5-MATH-CFT, treinado para alguns 50.000 exemplos, que geralmente são maiores do que os modelos competitivos com mais de dois milhões de amostras de treinamento. Além disso, a estrutura permitiu ser aprimorada em 7,0% na precisão do benchmark matemática e 16,6% nos centros MINVA em comparação com as estratégias normais de conversão. Esse importante desenvolvimento mostra a eficiência das críticas, que geralmente promovem bons resultados com algumas amostras de treinamento e recursos computacionais.
A aquisição deste estudo enfatiza os benefícios de aprendizagem baseados na Bíblia nos idiomas de treinamento de idiomas. Ao mudar o desejo de pedir a ajuda de críticas, os pesquisadores trouxeram a maneira que promove o modelo e promove as habilidades de pensamento profundo. A capacidade de explorar mais e a análise das respostas, em vez de fingir usar os modelos de gerenciamento de modelos. Este estudo fornece orientação promissora para melhorar o treinamento genético, reduzindo o custo da integração. Trabalhos futuros podem analisar o caminho através de outras medidas críticas para aprimorar o modelo e a confiança comum na outra, além de diferentes problemas para resolver problemas.
Enquete Página e papel do github. Todo o crédito deste estudo é pesquisado para este projeto. Além disso, não se esqueça de seguir Sane e junte -se ao nosso Estação de telégrafo incluindo LinkedIn grtópico. Não se esqueça de se juntar ao nosso 75k + ml subreddit.
🚨 O Marktechpost está gritando para as empresas / inicialização / grupos cooperarem com as próximas revistas da IA a seguinte 'fonte AI em produção' e 'e' Agentic AI '.
Nikhil é um estudante de estudantes em Marktechpost. Perseguindo graduados integrados combinados no Instituto Indiano de Tecnologia, Kharagpur. Nikhl é um entusiasmo de interface do usuário / ml que procura aplicativos como biomotomentores e ciências biomédicas. Após um sólido na ciência material, ele examina novos empreendimentos e desenvolvendo oportunidades de contribuir.
✅ [Recommended] Junte -se ao nosso canal de telégrafo


