
Os gráficos de informações (KGAs) são o básico da aplicação de inteligência de solicitações artificiais, mas não são perfeitas, afetando seu desempenho. KGs bem estabelecidos, como DBPepia e Wikidata, não têm relacionamentos comerciais importantes, reduzem seu trabalho nos reembolsos de reembolso (RAG) e outras atividades de aprendizado de máquina. Os métodos tradicionais de liberação podem fornecer gráficos esparsos com conexões importantes ou barulhentas, apresentações indesejadas. Portanto, é difícil obter as melhores informações de qualidade no texto aleatório. Superar esses desafios é importante para aprimorar a restauração do conhecimento, pensamento e compreensão avançados da ajuda da inteligência artificial.
Caminhos do reino para remover KGs em um texto verde para obter informações e gravidade abertas. O Openie, uma dependência da dependência de, produz sistemático (título, relacionamentos) três vezes, mas produz sites muito complexos e incessantes, reduzindo a conformidade. O Graphrag, incluindo os modelos de restauração, retorna diretamente e idioma, aprimora os negócios que vinculam, mas não produzem gráficos altamente, o que restringe o processo. Ambas as listas estão afetando a organização para resolver o consenso, a faísca na comunicação e completar o normal, liberá -las sem KG bem -sucedidas.
Os investigadores da Universidade de Stanford, da Universidade de Toronto, o gerador AI-Toronto-KG criou modelos de idiomas e algoritmos conjuntos para remover informações formais no texto organizado. Ao contrário das rotas frontais, o Kggen apresenta o método baseado em LM de LM desenvolvendo um gráfico relacionado ao gráfico, integrando negócios semelhantes e relacionamentos organizacionais. Isso melhora a escassez e a reciclagem, fornece um kg correspondente e bem conectado. KGGEN e Introduce a Mina (taxa de informação), referência da implementação do texto, permitindo medidas padrão de emissão de métodos.
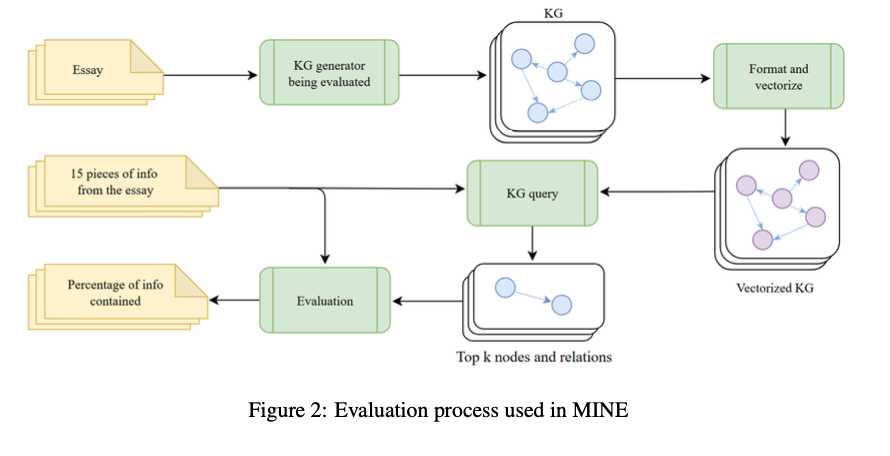
A Kggen está trabalhando em um pacote dinâmico de Python com módulos de negócios e a questão dos relacionamentos, integração e organização e fusão da fronteira. O módulo organizacional e a descarga de relacionamento usam o GPT-4O para obter triplos (título, previsão, item) em um texto aleatório. O módulo de agregação inclui triplos liberados de diferentes fontes em conhecimento integrado de informações (kg), e é por isso que certamente será uma multa para a penalidade. A organização da organização e a borda da borda usam o algoritmo acostativo para distinguir o SymononyStiture Ormogos, a mesma conclusão e desenvolver a conexão do gráfico. Ao usar fortes obstáculos ao modelo de idioma usando DSPY, o KGGEN permite o acesso à liberação formal e alta confiabilidade. O gráfico de resultados é dividido por sua comunicação apertada, conformidade semântica e desempenho de espiões artificiais.
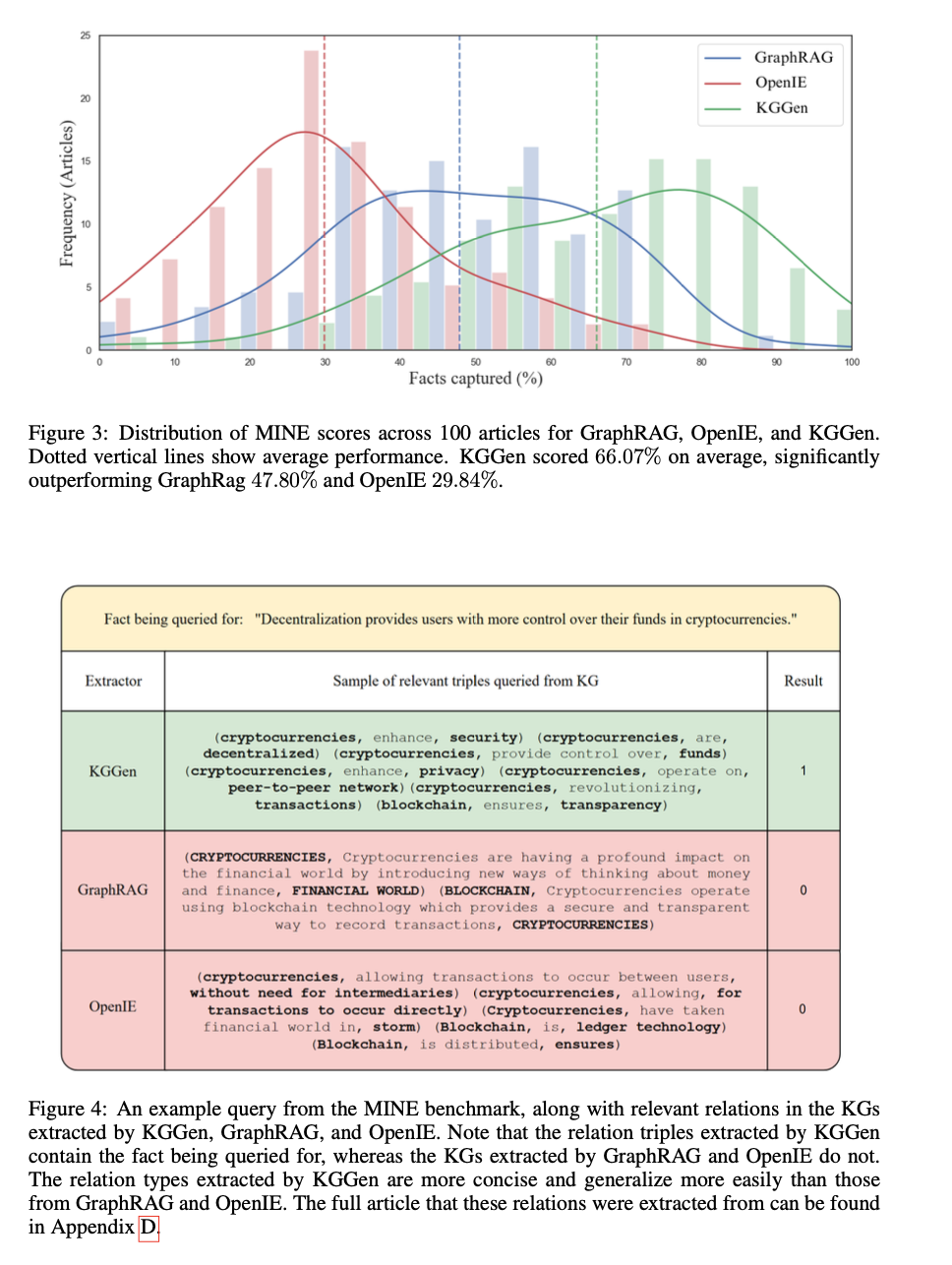
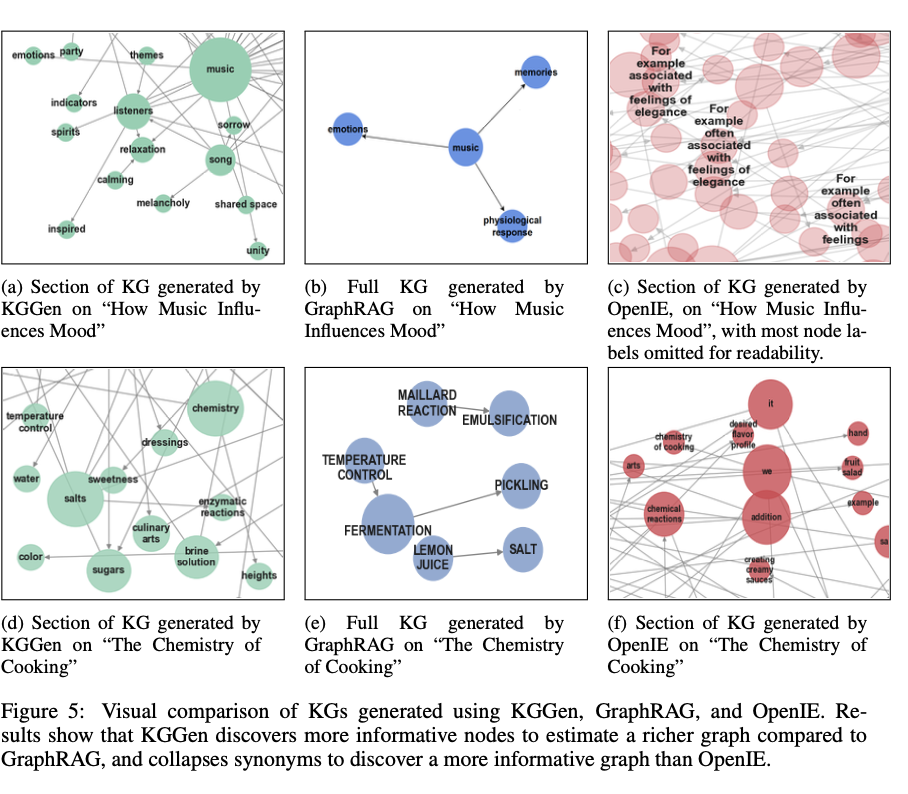
Os efeitos da medição do ícone indica o sucesso do caminho na remoção de informações sistemáticas de fontes de texto. Kggen recebe uma taxa de 66,07%, mais que o Graphrag em 47,80%e o Openie em 29,84%. O programa ajuda o poder de descarregar e fabricar informações sem repetir e melhorar a comunicação e a conformidade. A comparação de análises confirma o desenvolvimento de 18% na confiabilidade dos sistemas de emissão, destacando seu poder de produzir gráficos de informações organizadas adequadas. Os exames indicam que os gráficos são produzidos por mais densos e educados mais, o que os torna particularmente preparados nos contextos das informações e pensamentos baseados na IA.
Kggen é uma maneira de sucesso no gráfico gráfico de informações, porque combina os termos de avaliação de avaliação de atribuição de idioma Rocture de Iteract Clastering Clastering. Ao obter a precisão mais avançada de um limite de mina, ele levanta uma barra de texto aleatória para as apresentações de impacto. Isso é bem -sucedido do que o acesso mais longo a informações artificiais, atividades de consulta e aprendizado com base no aprendizado, produzindo assim como melhorar os gráficos de gráficos. O desenvolvimento do futuro se concentrará em melhorar as estratégias de integração e expor os testes de bancada para cobrir grandes informações.
Enquete o papel. Todo o crédito deste estudo é pesquisado para este projeto. Além disso, fique à vontade para segui -lo Sane E não se esqueça de se juntar ao nosso 75k + ml subreddit.
🚨 Pesquisa recomendada recomendada para nexo
Aswin AK é consultor em Marktechpost. Ele persegue seus dois títulos no Instituto Indiano de Tecnologia, Kharagpur. Você está interessado na leitura científica e científica e de máquinas, que traz uma forte formação e experiências educacionais para resolver os desafios reais de desenvolvimento de fundo.



