
A aprendizagem por reforço (RL) mudou fundamentalmente a IA, permitindo que os modelos melhorassem iterativamente o desempenho por meio de interação e feedback. Quando aplicado a modelos linguísticos de grande escala (LLMs), o RL abre novas maneiras de lidar com tarefas que exigem raciocínio complexo, como resolução de problemas matemáticos, codificação e interpretação de dados multimodais. Os métodos tradicionais dependem fortemente do pré-treinamento com grandes conjuntos de dados estáticos. No entanto, as suas limitações tornaram-se aparentes à medida que os modelos resolvem problemas que requerem avaliação dinâmica e tomada de decisão dinâmica.
O maior desafio no desenvolvimento de LLMs é aumentar as suas competências e, ao mesmo tempo, garantir a eficiência informática. Com base em conjuntos de dados estáticos, os métodos de treinamento convencionais lutam para atender às demandas de tarefas complexas que envolvem raciocínio complexo. Além disso, as implementações existentes do LLM RL não conseguiram fornecer resultados modernos devido a ineficiências na concepção rápida, no desenvolvimento de políticas e na gestão de dados. Esta deficiência deixou uma lacuna no desenvolvimento de modelos que possam ter um bom desempenho em vários benchmarks, especialmente aqueles que precisam pensar simultaneamente em entrada de texto e visual. A solução deste problema requer uma estrutura abrangente que alinhe o desenvolvimento do modelo com as necessidades específicas da tarefa, mantendo a eficiência do token.
As soluções anteriores para o desenvolvimento de LLMs incluem configuração bem supervisionada e métodos de pensamento avançados, como informações de cadeia de pensamento (CoT). O pensamento CoT permite que os modeladores dividam os problemas em etapas intermediárias, melhorando sua capacidade de lidar com questões complexas. No entanto, este método é muito caro e muitas vezes limitado pelo tamanho limitado da janela de contexto dos LLMs. Da mesma forma, a busca em árvore de Monte Carlo, uma técnica de otimização popular, introduz sobrecarga e complexidade computacional. A ausência de quadros de RL não regulamentados para LLMs limitou o progresso, sublinhando a necessidade de uma nova abordagem que meça a melhoria do desempenho e a eficiência.
Pesquisadores da Equipe Kimi apresentaram Para mim k1.5é um LLM multimodal de próxima geração projetado para superar esses desafios, combinando RL com recursos estendidos ao contexto. Este modelo utiliza novas técnicas, como o dimensionamento de conteúdo longo, que expande a janela de contexto para 128.000 tokens, permitindo processar grandes casos de problemas de forma eficaz. Ao contrário dos métodos anteriores, Kimi k1.5 evita depender de métodos complexos, como busca em árvore de Monte Carlo ou funções de valor, optando por uma estrutura RL simples. A equipe de pesquisa desenvolveu um conjunto rápido de configuração de RL para melhorar a flexibilidade do modelo, incorporando uma variedade de entradas, incluindo STEM, codificação e tarefas de pensamento geral.
Kimi k1.5 foi desenvolvido em duas versões:
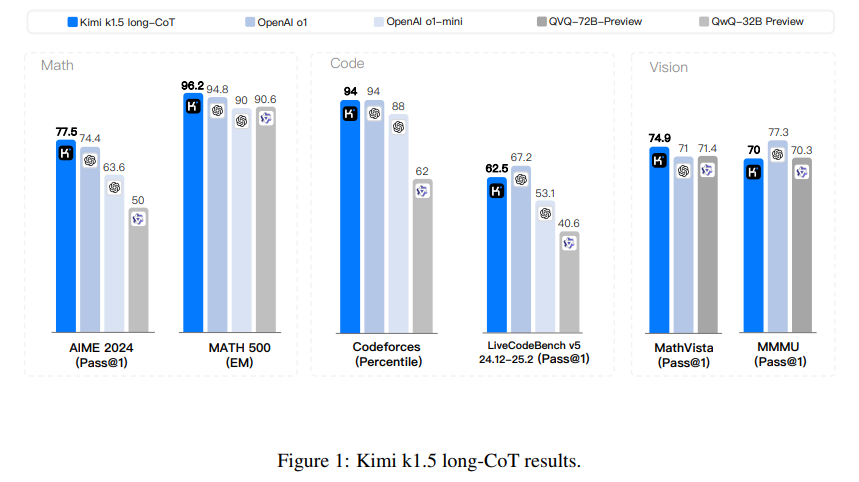
- Modelo CoT longo: Ele funciona muito bem em tarefas lógicas estendidas, usando sua janela total de tokens de 128k para obter os melhores resultados em todos os benchmarks. Por exemplo, obteve uma pontuação de 96,2% no MATH500 e o percentil 94 no Codeforces, demonstrando a sua capacidade de lidar com problemas complexos e de várias etapas.
- Modelo Short-CoT: O modelo Short-CoT é otimizado para desempenho usando métodos avançados de treinamento de contexto longo a curto. Este método transferiu com sucesso a prioridade lógica do modelo CoT longo, permitindo que o modelo CoT curto mantivesse alto desempenho, 60,8% no AIME e 94,6% no MATH500, enquanto reduzia significativamente o consumo de tokens.
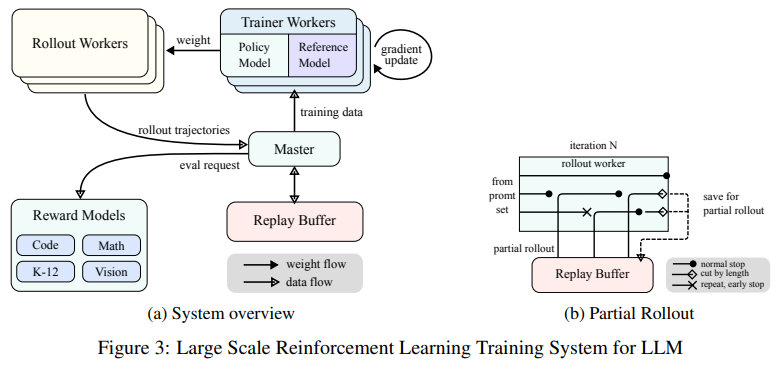
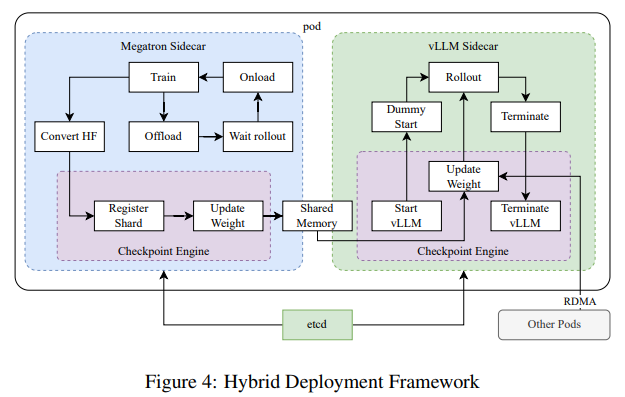
O processo de treinamento incluiu ajuste fino supervisionado, pensamento de cadeia longa e RL para criar uma estrutura sólida de resolução de problemas. Uma inovação importante incluiu a abstração parcial, um método que reutiliza métodos previamente calculados para melhorar a eficiência da computação durante longos processamentos de conteúdo. O uso de fontes de dados multimodais, como conjuntos de dados virtuais sintéticos e do mundo real, fortaleceu ainda mais a capacidade do modelo de interpretar e raciocinar em textos e imagens. Técnicas avançadas de amostragem, incluindo currículo e amostragem priorizada, garantem que a formação se concentre em áreas onde o modelo apresentou fraco desempenho.
Kimi k1.5 mostrou uma melhoria significativa na eficiência do token usando seu método de treinamento de contexto de longo a curto prazo, que permite a transferência de prioridades cognitivas de modelos de longo prazo para modelos de curto prazo, mantendo o alto desempenho e reduzindo o consumo de tokens . O modelo alcançou resultados impressionantes em vários benchmarks, incluindo uma precisão de correspondência de 96,2% no MATH500, 94% no Codeforces e uma taxa de aprovação de 77,5% no AIME, modelos de alto nível como GPT-4o e Claude. Soneto 3.5 por grandes margens. Seu desempenho de CoT curto superou GPT-4o e Claude Sonnet 3.5 em benchmarks como AIME e LiveCodeBench em até 550%, enquanto seu desempenho de CoT longo correspondeu a 01 na maioria dos benchmarks, incluindo -MathVista e Codeforces. Os principais recursos incluem dimensionamento de conteúdo longo com RL usando janelas de contexto de até 128 mil tokens, treinamento eficiente com extração parcial, otimização aprimorada de políticas com espelhamento online, técnicas de amostragem aprimoradas e penalidades de comprimento. Além disso, o Kimi k1.5 se destaca no pensamento colaborativo em relação ao texto e à visão, destacando suas capacidades multimodais.
O estudo revelou várias conclusões importantes:
- Ao permitir que os modelos sejam testados dinamicamente com recompensas, o RL remove as restrições dos conjuntos de dados estáticos, expandindo o escopo do pensamento e da resolução de problemas.
- O uso de uma janela total de tokens de 128.000 permitiu que o modelo executasse efetivamente o raciocínio na cadeia, um fator chave em seus resultados de alto nível.
- A liberação parcial e as técnicas de amostragem priorizada melhoraram o processo de treinamento, garantindo que os recursos fossem alocados às áreas de maior impacto.
- A incorporação de uma variedade de dados visuais e textuais tornou o modelo bem-sucedido em todos os benchmarks que exigem consideração simultânea de vários tipos de entrada.
- A estrutura RL otimizada usada no Kimi k1.5 evita as armadilhas de técnicas computacionalmente intensivas, alcançando alto desempenho sem consumo excessivo de recursos.
Concluindo, Kimi k1.5 aborda as limitações dos métodos tradicionais de pré-treinamento e utiliza novas técnicas para medir o contexto e o desempenho do token; a pesquisa estabelece um novo padrão de desempenho para todas as tarefas cognitivas e multimodais. Os modelos Long-CoT e Short-CoT juntos demonstram a versatilidade do Kimi k1.5, desde o tratamento de tarefas complexas e de pensamento estendido até a obtenção de soluções de token eficientes para cenários curtos.
Confira Página de papel e GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Não se esqueça de participar do nosso SubReddit de 65k + ML.
🚨 [Recommended Read] Nebius AI Studio se estende com modelos de visão, novos modelos de linguagem, embeddings e LoRA (Promovido)
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre o público.
📄 Conheça 'Height': ferramenta independente de gerenciamento de projetos (patrocinado)


