
A aprendizagem autodirigida a partir de conjuntos de dados off-line permitiu que modelos em grande escala alcançassem capacidades notáveis nos domínios de texto e imagem. Contudo, generalizações sobre agentes que atuam sequencialmente em problemas de tomada de decisão são difíceis de serem alcançadas. As situações clássicas de Aprendizagem por Reforço (RL) são muito pequenas e uniformes e, portanto, difíceis de adaptar.
Os métodos atuais de aprendizagem por reforço (RL) tendem a treinar agentes em tarefas fixas, o que limita sua capacidade de adaptação a novos ambientes. Plataformas semelhantes MuJoCo de novo Ginásio OpenAI focar em situações específicas, limitando a flexibilidade do agente. RL é baseado em Processos de Decisão Markov (MDPs), onde os agentes maximizam recompensas coletivas interagindo com os ambientes. O Design de Ambiente Não Supervisionado (UED) aborda essas limitações introduzindo uma estrutura professor-aluno, onde o professor cria atividades para desafiar o agente e promover uma aprendizagem eficaz. Certas métricas garantem que as tarefas não sejam muito fáceis e impossíveis. Ferramentas como JAX permitem o treinamento RL baseado em GPU em paralelo, enquanto os conversores, usando mecanismos de atenção, melhoram o desempenho do agente modelando relacionamentos complexos em dados sequenciais ou não estruturados.
Para resolver essas limitações, a equipe de pesquisa desenvolveu Kinetixum espaço aberto para ambientes RL baseados em física.
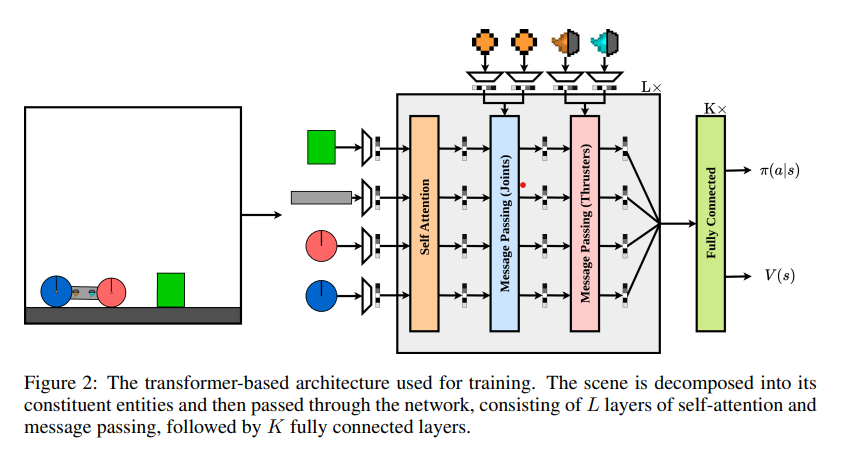
Kinetixproposta por uma equipe de pesquisadores da Universidade de Oxfordpode representar tarefas que vão desde locomoção e preensão robótica até videogames e ambientes RL clássicos. Kinetix usa um mecanismo de física acelerado por hardware, Jax2Do que permite a simulação barata de bilhões de etapas ambientais durante o treinamento. Um agente treinado demonstra fortes habilidades de raciocínio físico, capaz de acertar zero para resolver ambientes invisíveis criados pelo homem. Além disso, o ajuste fino deste agente geral para as tarefas de interesse mostra um desempenho muito mais forte do que o treinamento do agente RL tabula rasa. Jax2D usa passos exatos de Euler para velocidades rotacionais e espaciais e usa impulsos e correções de alta ordem para atrasar sequências rápidas para simular efetivamente várias funções corporais. Kinetix é adequado para muitas áreas de ação diferentes e contínuas e uma ampla gama de atividades de RL.
Os pesquisadores treinaram um agente RL padrão em dezenas de milhões de tarefas baseadas em um modelo físico 2D. O agente demonstrou fortes habilidades de raciocínio físico, capaz de resolver problemas abstratos projetados pelo homem. O ajuste fino disso demonstra a viabilidade do pré-treinamento de RL online híbrido e em larga escala.
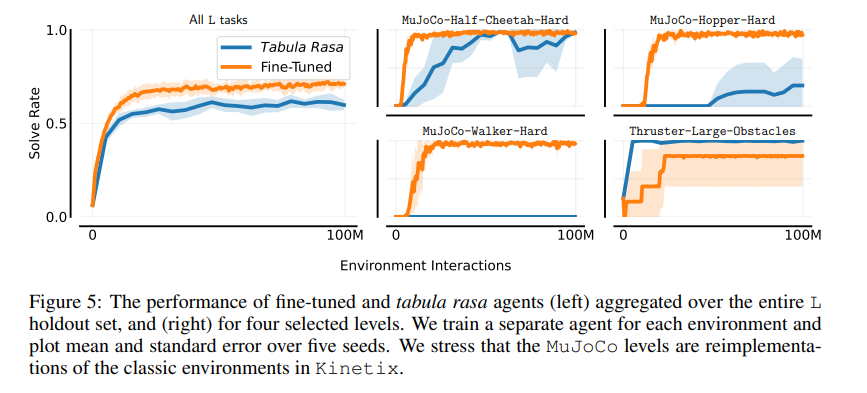
Concluindo, Kinetix é uma descoberta que aborda as limitações dos ambientes RL tradicionais, fornecendo um ambiente diversificado e aberto para treinamento, levando ao desenvolvimento geral e ao desempenho dos agentes RL. Este trabalho pode servir de base para pesquisas futuras sobre pré-treinamento on-line em larga escala de agentes gerais de RL e projeto espacial não supervisionado.
Confira Página de papel e GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[FREE AI WEBINAR] Usando processamento inteligente de documentos e GenAI em serviços financeiros e transações imobiliárias– Da estrutura à produção
Nazmi Syed é estagiária de consultoria na MarktechPost e está cursando bacharelado em ciências no Instituto Indiano de Tecnologia (IIT) Kharagpur. Ele tem uma profunda paixão pela Ciência de Dados e está explorando ativamente a ampla aplicação da inteligência artificial em vários setores. Fascinada pelos avanços tecnológicos, a Nazmi está comprometida em compreender e aplicar inovações de ponta em situações do mundo real.
🐝🐝 Evento do LinkedIn, 'Uma plataforma, possibilidades multimodais', onde o CEO da Encord, Eric Landau, e o chefe de engenharia de produto, Justin Sharps, falarão sobre como estão reinventando o processo de desenvolvimento de dados para ajudar o modelo de suas equipes – a IA está mudando o jogo, rápido.

 para PCs Intel")
