
Nos últimos tempos, modelos linguísticos de grande escala (LLMs) construídos na arquitetura Transformer mostraram capacidades notáveis em múltiplas tarefas. No entanto, esses recursos impressionantes geralmente vêm com um grande aumento no tamanho do modelo, levando a grandes custos de memória da GPU durante a inferência. O repositório KV é uma técnica popular usada na inferência LLM. Ele salva chaves e valores calculados anteriormente no processo de indexação, que podem ser reutilizados para agilizar etapas futuras, tornando o processo de indexação mais rápido em geral. A maioria dos métodos de compactação de armazenamento KV existentes concentra-se na compactação intracamada dentro de uma camada do Transformer, mas poucos trabalhos consideram a compactação por quadro. A memória usada pelo cache KV (valor-chave) é usada principalmente para armazenar os componentes chave e valor do mapa de atenção, que representa mais de 80% do uso total da memória. Isso torna os recursos do sistema ineficientes e cria a necessidade de mais poder de computação.
Os pesquisadores desenvolveram muitas maneiras de compactar caches KV para reduzir o uso de memória. No entanto, a maioria desses estudos concentrou-se na compressão do buffer KV dentro de cada camada do Transformador LLM. Porém, as técnicas de compactação de cache KV em camadas permanecem inexploradas, computando o cache KV com apenas um pequeno conjunto de camadas para reduzir o consumo de memória. A funcionalidade limitada existente de compactação de cache KV em camadas geralmente requer treinamento adicional para manter um desempenho satisfatório. A maioria dos trabalhos de compactação de cache KV existentes, como H2O, SnapKV e PyramidInfer, são executados em uma única camada de transformador, ou seja, compactação intracamada, mas não consideram a compactação de cache KV inteligente. Outras obras como CLA, LCKV, Ayer, etc. concentra-se em técnicas de compactação inteligentes para cache KV. No entanto, todos eles exigem mais treinamento de modelo, em vez de serem plug-and-play para LLMs bem treinados.
Um grupo de pesquisadores de Universidade Jiao Tong de Xangai, Universidade Central Sul, Instituto de Tecnologia de Harbin, de novo ByteDança proposto KVSharerum método plug-and-play de compactação do cache KV para LLMs bem treinados. Os pesquisadores descobriram uma maneira, quando os caches KV são muito diferentes entre duas camadas, compartilhar o cache KV de uma camada com outra durante a previsão não reduz significativamente o desempenho. Usando o reconhecimento, o KVSharer usa uma estratégia de pesquisa para identificar a estratégia de compartilhamento de cache KV nas diferentes camadas durante a previsão. O KVSharer reduz significativamente o uso de memória da GPU, mantendo a maior parte do desempenho do modelo. Como um método de compactação de cache KV em camadas, o KVSharer funciona bem com métodos existentes que compactam caches KV dentro de cada camada, fornecendo uma maneira adicional de otimizar a memória para LLMs.
Os principais passos de KVSharer dividido em duas partes. Primeiro, um determinado LLM procura uma estratégia de compartilhamento, uma lista que especifica quais caches KV de camadas devem ser substituídos por aqueles de outras camadas. Então, durante as etapas subsequentes de preenchimento e produção de todas as operações, o cache KV é usado.
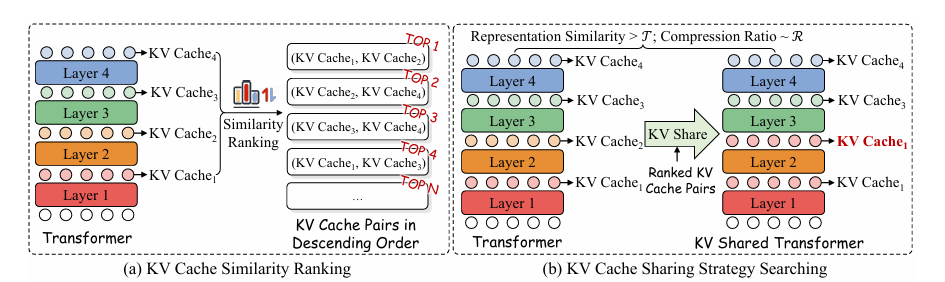
Uma estratégia eficaz de compartilhamento de cache KV para LLMs começa medindo as diferenças entre os caches KV de cada camada no conjunto de dados de teste, concentrando-se no compartilhamento dos pares mais distintos. Os caches KV são compartilhados de uma camada para outra, com prioridade das camadas mais próximas da saída para evitar qualquer degradação no desempenho. Cada par compartilhado é salvo apenas se a saída permanecer igual ao original. Este processo continua até que o número alvo de camadas compartilhadas seja atingido, resultando em uma estratégia que acelera operações futuras ao reutilizar eficientemente o cache KV.
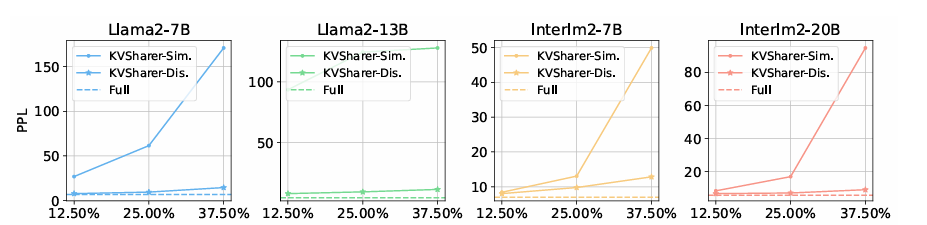
Os pesquisadores testaram o modelo KVSharer em vários modelos ingleses e bilíngues, incluindo Lhama2 de novo EstagiárioLM2e descobriu que ele pode compactar dados de maneira eficaz com perda mínima de desempenho. Usando o benchmark OpenCompass, a equipe de pesquisa testou a capacidade do modelo de pensar, linguagem, informação e compreensão de tarefas com conjuntos de dados como CMNLI, HellaSwagde novo CommonSenseQA. Nos níveis de pressão abaixo 25%KVSharer é mantido por perto 90-95% do desempenho do modelo original e funcionou bem com outras técnicas de compressão semelhantes H2O de novo PirâmideInferirmelhorando a eficiência da memória e a velocidade de processamento. Testes em modelos grandes, como Lhama2-70Bverificou a capacidade do KVSharer de compactar o cache de forma eficaz com impacto mínimo no desempenho.
Para concluir, o método KVSharer proposto fornece uma solução eficiente para reduzir o consumo de memória e melhorar a velocidade de predição em LLMs usando uma contramedida para compartilhar buffers KV heterogêneos. Os testes mostram que o KVSharer mantém mais de 90% do desempenho original dos LLMs convencionais, ao mesmo tempo que reduz os cálculos de cache KV em 30%. Ele também pode fornecer aceleração de geração de pelo menos 1,3 vezes. Além disso, o KVSharer pode ser combinado com métodos de compactação de cache KV intracamadas existentes para obter maior economia de memória e previsões mais rápidas. Portanto, este método funciona bem com as técnicas de compressão atuais, pode ser usado para diferentes tarefas sem exigir treinamento adicional e pode ser usado como base para desenvolvimentos futuros no domínio.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Trending] LLMWare apresenta Model Depot: uma coleção abrangente de modelos de linguagem pequena (SLMs) para PCs Intel
Divyesh é estagiário de consultoria na Marktechpost. Ele está cursando BTech em Engenharia Agrícola e Alimentar pelo Instituto Indiano de Tecnologia, Kharagpur. Ele é um entusiasta de Ciência de Dados e Aprendizado de Máquina que deseja integrar essas tecnologias avançadas no domínio agrícola e resolver desafios.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


")