
Novak Zivanic deu uma grande contribuição ao campo do Processamento de Linguagem Natural com o lançamento de Embedićuma coleção de modelos de incorporação de texto sérvio. Esses modelos são projetados especificamente para tarefas de recuperação de informações e geração avançada de recuperação (RAG). Especificamente, o menor modelo do conjunto alcançou um desempenho impressionante, superando o desempenho de última geração anterior e usando 5 vezes menos parâmetros. Esta conquista demonstra a eficiência e eficácia dos modelos de Embedić no tratamento de tarefas de processamento da língua sérvia.
Os modelos Embedić são aprimorados a partir dos modelos e5 multilíngues e vêm em 3 tamanhos (pequeno, básico e grande).
A suíte Embedić mostra notável flexibilidade em seu poder linguístico. Embora especializados em sérvio, incluindo escrita cirílica e latina, esses modelos também apresentam funcionalidade entre idiomas, compreendendo também o inglês. Este recurso permite aos usuários incorporar documentos em inglês, sérvio ou uma combinação dos dois idiomas. Usando uma estrutura de transformação de sentenças, Embedić mapeia sentenças e cláusulas em um Um espaço vetorial denso de 786 dimensões. Esta representação torna os modelos particularmente úteis para tarefas como agrupamento e pesquisa semântica, o que melhora a sua utilização prática em diferentes contextos linguísticos.
Ao usar o Embedić, é importante observar algumas diretrizes de uso importantes. O uso de “ošišana latinica” (escrita latina simplificada sem alfabetos) pode reduzir significativamente a qualidade da pesquisa, por isso é aconselhável usar a notação sérvia adequada. Além disso, o uso de letras maiúsculas para entidades nomeadas pode melhorar os resultados da pesquisa.
A suíte Embedić oferece três tamanhos de modelo: pequeno, básico e grande, todos ajustados a partir dos modelos e5 multilíngues. O processo de treinamento, executado em uma única Super GPU 4070ti, envolve uma abordagem de três etapas: destilação, treinamento em pares (consulta, texto) e ajuste final em trigêmeos.
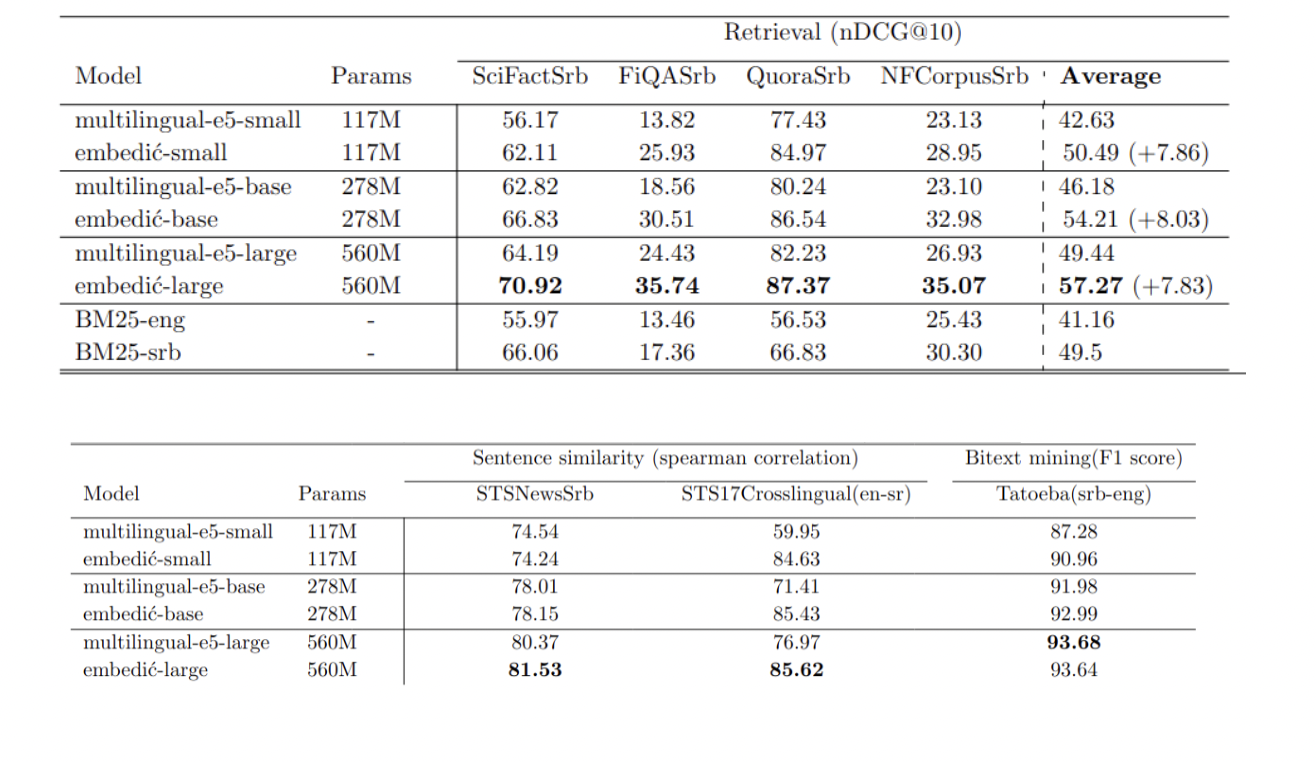
Os modelos Embedić foram rigorosamente testados em três tarefas principais: recuperação de informações, similaridade de frases e mineração de bittexto. Para garantir uma avaliação abrangente, foram investidos esforços e recursos significativos na criação de conjuntos de dados relevantes em língua sérvia. O desenvolvedor traduziu manualmente o conjunto de dados de teste STS17 para diferentes idiomas, demonstrando um compromisso com a precisão. Além disso, um grande investimento de US$ 6.000 foi feito na API de tradução do Google para converter quatro conjuntos de dados de teste de recuperação de informações para sérvio. Esta abordagem cuidadosa à preparação do conjunto de dados enfatiza o rigor do processo de avaliação e a potencial eficácia dos modelos nas atividades de língua sérvia.
O lançamento de Embedić marca um grande desenvolvimento no estudo da língua sérvia. Desenvolvido por Novak Zivanic, este conjunto de modelos de incorporação de texto oferece desempenho moderno para recuperação de informações e funções RAG, com um modelo menor que tem desempenho melhor do que benchmarks anteriores usando poucos parâmetros. Os modelos, disponíveis em três tamanhos, são bem ajustados a partir do multilingual-e5 e oferecem recursos multilíngues, compreendendo tanto o sérvio (escrita cirílica e latina) quanto o inglês.
Embedić usa uma estrutura de transformação de frases, mapeando texto para um espaço vetorial de 786 dimensões, tornando-o ideal para combinar funções de pesquisa semântica. O processo de desenvolvimento envolveu treinamento e análise cuidadosos, incluindo esforços de tradução pessoal e investimento significativo na criação de conjuntos de dados sérvios completos.
Confira Cartão Modelo em HF.. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre o público.
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)


 para testar o desempenho da computação quântica em condições de ruído")