
Modelos de incorporação de texto têm sido fundamentais para o processamento de linguagem natural (PNL). Esses modelos transformam texto em vetores de alta dimensão que capturam relacionamentos semânticos, permitindo operações como recuperação de documentos, classificação, agrupamento e muito mais. A incorporação é particularmente importante em sistemas avançados, como os modelos Retrieval-Augmented Generation (RAG), onde a incorporação suporta a recuperação de documentos relevantes. Com a crescente necessidade de modelos que possam lidar com vários idiomas e longas sequências de texto, os modelos baseados em transformadores revolucionaram a forma como a incorporação é feita. No entanto, embora estes modelos tenham capacidades avançadas, enfrentam limitações em aplicações do mundo real, especialmente no tratamento de grandes quantidades de dados multilingues e de documentos de contexto longos.
Os modelos de incorporação de texto enfrentaram vários desafios nos últimos anos. Embora anunciado como de uso geral, o principal problema é que a maioria dos modelos geralmente requer alguns ajustes para funcionar bem em uma variedade de tarefas. Esses modelos geralmente lutam para equilibrar o desempenho entre idiomas e lidar com longas sequências de texto. Em sistemas multilíngues, os modelos de incorporação devem lidar com a complexidade das relações de codificação entre diferentes idiomas, cada um com estruturas linguísticas únicas. A dificuldade aumenta com tarefas que exigem o processamento de sequências de texto estendidas, que muitas vezes excedem a capacidade de muitos modelos atuais. Além disso, a execução de modelos tão grandes, muitas vezes com milhares de milhões de parâmetros, apresenta custos computacionais significativos e desafios de escalabilidade, especialmente se pequenas melhorias não justificarem a utilização de recursos.
As tentativas anteriores para resolver estes desafios basearam-se fortemente em grandes modelos linguísticos (LLMs), que podem exceder 7 mil milhões de parâmetros. Esses modelos demonstraram experiência no tratamento de diversas tarefas em diferentes idiomas, desde análise de texto até recuperação de documentos. No entanto, apesar do grande tamanho do parâmetro, os ganhos de desempenho são pequenos em comparação com modelos somente com codificador, como XLM-RoBERTa e mBERT. A complexidade destes modelos torna-os impraticáveis em muitas aplicações do mundo real onde os recursos são limitados. Os esforços para tornar a incorporação mais eficiente incluíram inovações como ajuste de instruções e métodos de codificação, como Rotary Position Embedding (RoPE), que ajuda os modelos a processar longas sequências de texto. No entanto, mesmo com estes avanços, os modelos muitas vezes não conseguem satisfazer as necessidades das tarefas de recuperação multilingues do mundo real, conforme desejado.
Pesquisadores da Jina AI GmbH introduziram um novo modelo, Jina-embeddings-v3projetado especificamente para resolver as ineficiências dos modelos de incorporação anteriores. Este modelo, que inclui 570 milhões de parâmetros, oferece desempenho aprimorado em diversas tarefas, ao mesmo tempo em que oferece suporte a documentos de texto longo de até 8.192 tokens. O modelo inclui uma inovação importante: adaptadores de adaptação de baixa classificação (LoRA) específicos para tarefas. Esses adaptadores permitem que o modelo gere com sucesso incorporações de alta qualidade para uma variedade de tarefas, incluindo recuperação de documentos de consulta, segmentação, clustering e correspondência de texto. A capacidade do Jina-embeddings-v3 de fornecer alguma personalização dessas funções garante o gerenciamento eficaz de dados multilíngues, documentos longos e situações complexas de recuperação, medição e medição de desempenho.
A arquitetura do modelo Jina-embeddings-v3 baseia-se no amplamente conhecido modelo XLM-RoBERTa, mas com vários aprimoramentos importantes. Ele usa FlashAttention 2 para melhorar a eficiência da computação e integra incorporação RoPE local para lidar com longas operações de conteúdo de até 8.192 tokens. Um dos novos recursos do modelo é o Matryoshka Representation Learning, que permite aos usuários reduzir a incorporação sem afetar o desempenho. Este método proporciona flexibilidade na escolha de diferentes tamanhos de incorporação, como a redução de uma incorporação de 1.024 dimensões para apenas 16 ou 32 dimensões, o que melhora o compromisso entre eficiência de espaço e desempenho de trabalho. Com a adição de adaptadores LoRA específicos para tarefas, que representam menos de 3% do total de parâmetros, o modelo pode se adaptar de forma flexível a diferentes tarefas, como segmentação e recuperação. Ao congelar os pesos do modelo original, os pesquisadores garantiram que o treinamento desses adaptadores permanecesse muito eficiente, utilizando uma fração da memória exigida pelos modelos tradicionais. Essa eficiência o torna útil para uso em ambientes reais.
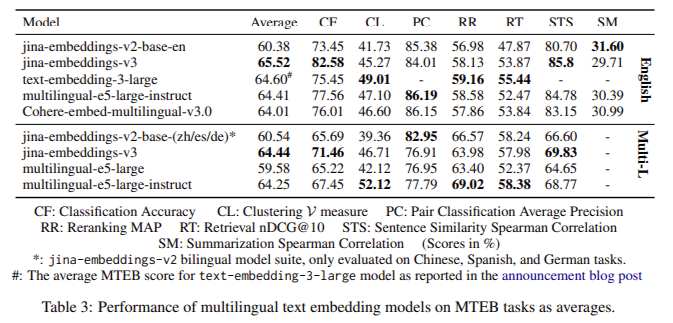
O modelo Jina-embeddings-v3 mostrou melhorias notáveis de desempenho em vários testes de benchmark. O modelo supera concorrentes como os modelos proprietários da OpenAI e a incorporação multilíngue da Cohere em testes multilíngues, especialmente para tarefas de inglês. O modelo jina-embeddings-v3 apresentou resultados mais elevados em precisão de classificação (82,58%) e similaridade de sentenças (85,8%) no benchmark MTEB, superando modelos maiores como e5-mistral-7b-instruct, com mais de 7 bilhões de parâmetros, mas mostra apenas uma pequena melhoria de 1% em certas funções. Jina-embeddings-v3 obteve os melhores resultados em tarefas multilíngues, superando multilingual-e5-large-instruct em todas as tarefas, apesar de seu tamanho muito menor. Sua capacidade de funcionar bem em tarefas de recuperação de contexto longas e multilíngues, ao mesmo tempo em que requer menos recursos computacionais, o torna altamente eficiente e econômico, especialmente para aplicativos de computação de ponta rápidos.

Concluindo, Jina-embeddings-v3 fornece uma solução escalável e eficiente para os desafios de longa data que os modelos de incorporação de texto enfrentam em projetos multilíngues e de formato longo. A combinação de adaptadores LoRA, aprendizado de representação Matryoshka e outras técnicas avançadas garante que o modelo possa lidar com uma variedade de tarefas sem a carga computacional excessiva vista em modelos com bilhões de parâmetros. Os pesquisadores desenvolveram um modelo eficaz e eficiente que supera muitos dos principais modelos e estabelece um novo padrão para incorporação de eficiência. A introdução dessas inovações fornece um caminho claro para avanços adicionais na aquisição multilíngue e de textos longos, tornando o Word-embeddings-v3 uma ferramenta importante na PNL.
Confira Papel de novo Cartão Modelo em HF. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)


