
A demanda por modelos personalizáveis e de código aberto que possam funcionar bem em uma variedade de plataformas de hardware tem crescido, e a Meta está na vanguarda para atender a essa demanda. Meta abriu o código para o lançamento de Lama 3.2com LLMs de visão pequena e média (11B e 90B) e modelos leves somente de texto (1B e 3B) projetados para dispositivos periféricos e móveis, disponíveis em versões pré-treinadas e ativadas por instrução. Lama 3.2 atende a essas necessidades com uma coleção de modelos leves e robustos, otimizados para uma variedade de tarefas, incluindo aplicativos somente texto e baseados em visualização. Esses modelos são projetados especificamente para dispositivos de ponta, tornando a IA mais acessível para desenvolvedores e empresas.
Exceção de modelo lançada
EU Lama 3.2 lançou duas categorias de modelos nesta iteração da série Llama:
- LLMs de visão (11B e 90B): Esses são os maiores modelos para tarefas complexas de processamento de imagens, como compreensão em nível de documento, suporte visual e legendagem de imagens. Eles competem com outros modelos de circuito fechado do mercado e os superam em benchmarks de reconhecimento de imagem.
- LLM somente com texto claro (1B e 3B): Esses pequenos modelos são projetados para aplicações de IA no limite. Eles fornecem desempenho robusto para resumo, acompanhamento de instruções e operações rápidas de reescrita, mantendo um baixo impacto computacional. Os modelos também têm um núcleo de 128.000 tokens, uma melhoria significativa em relação às versões anteriores.
Estão disponíveis versões pré-treinadas e otimizadas para instrução desses modelos, com suporte da Qualcomm, MediaTek e Arm, garantindo que os desenvolvedores possam usar esses modelos diretamente em dispositivos móveis e de ponta. Os modelos são disponibilizados para download imediato e uso em llama.com, Hugging Face e plataformas de parceiros como AMD, AWS, Google Cloud e Dell.
Desenvolvimento Tecnológico e Apoio a Ecossistemas
Uma das melhorias mais notáveis no Llama 3.2 é a introdução de uma arquitetura baseada em adaptador para modelos de visão, onde codificadores de imagem são combinados com modelos de texto pré-treinados. Essa estrutura permite o processamento intensivo de dados de imagem e texto, o que amplia bastante os casos de uso desses modelos. Os modelos pré-treinados são otimizados, incluindo treinamento em dados de pares de imagens de alto ruído em grande escala e pós-treinamento em conjuntos de dados de domínio de alta qualidade.
O forte suporte do ecossistema do Llama 3.2 é outro fator chave no seu potencial revolucionário. Com parcerias entre empresas líderes de tecnologia, AWS, Databricks, Dell, Microsoft Azure, NVIDIA e outras, o Llama 3.2 foi projetado para ambientes locais e em nuvem. Além disso, a distribuição Llama Stack simplifica a implantação para desenvolvedores, fornecendo soluções prontas para uso para ambientes de borda, nuvem e no dispositivo. Uma distribuição, como PyTorch ExecuTorch no uso do dispositivo e Ollama para configurar um único nó, fortalece ainda mais a interação desses tipos.
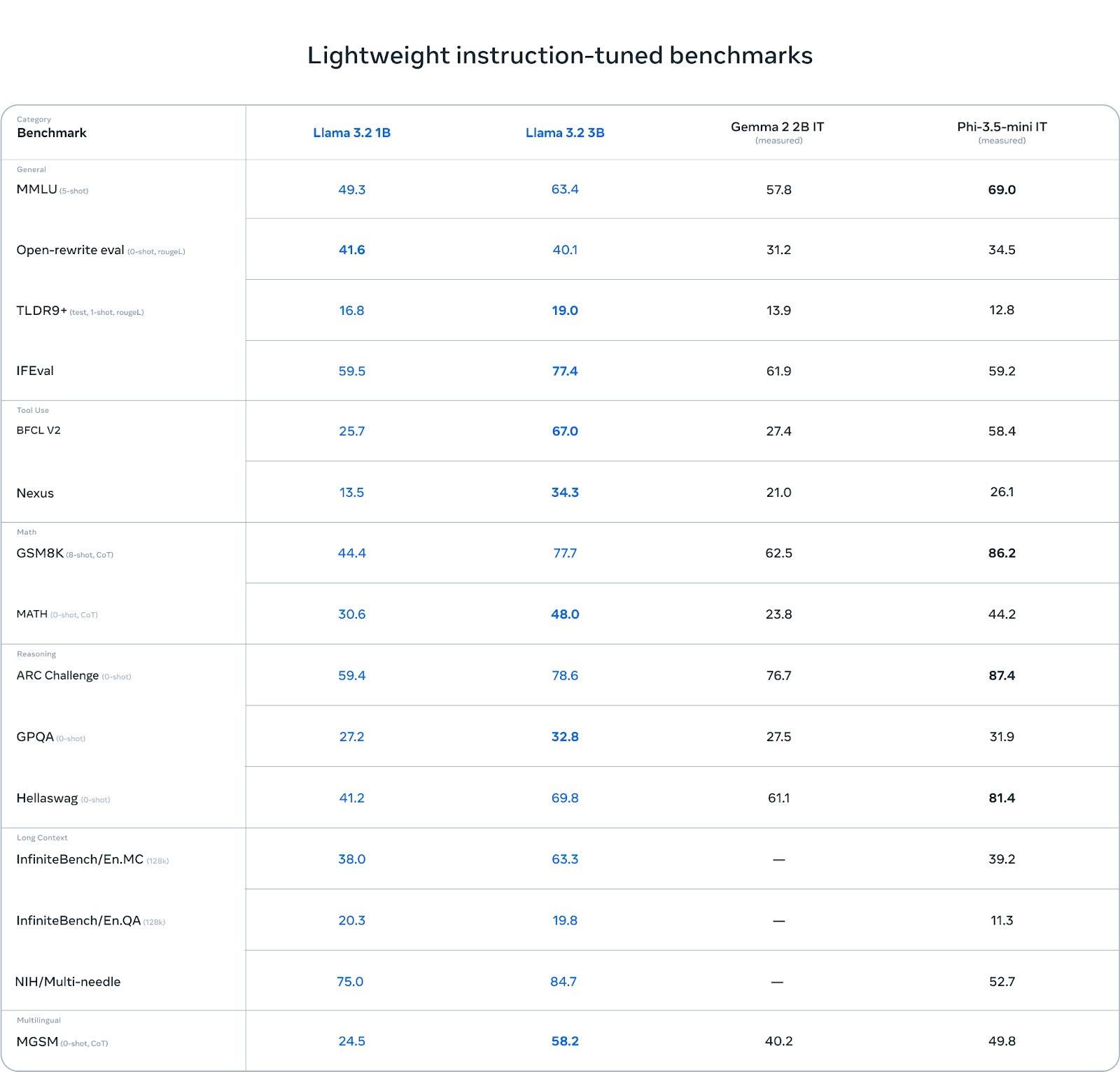
Métricas de desempenho
A variante Llama 3.2 oferece desempenho impressionante em todas as tarefas de texto e visuais. Os modelos leves de texto 1B e 3B, otimizados para dispositivos móveis e de borda, se destacam em compactação, rastreamento de instruções e reescrita rápida, mantendo um comprimento de contexto de token de 128K. Esses modelos superam concorrentes como o Gemma 2.6B e o Phi 3.5-mini em vários benchmarks. No lado visual, os modelos 11B e 90B apresentam capacidades superiores em reconhecimento de imagem, raciocínio e tarefas visuais baseadas no solo, com modelos fechados superando o Claude 3 Haiku e o GPT4o-mini nos principais benchmarks. Esses modelos combinam bem texto e gráficos, tornando-os ideais para aplicações multimodais.
O poder dos modelos leves
A introdução de modelos leves no Llama 3.2, especialmente as variantes 1B e 3B, é importante para computação de ponta e aplicações sensíveis à privacidade. Trabalhar localmente em dispositivos móveis garante que os dados permaneçam no dispositivo, melhorando a privacidade do usuário ao evitar o processamento baseado em nuvem. Isto é especialmente benéfico em situações como resumir mensagens pessoais ou gerar itens de ação em reuniões sem enviar informações confidenciais a servidores externos. Meta usou técnicas de poda e filtragem de informações para obter modelos menores, mantendo alto desempenho. Os modelos 1B e 3B foram cortados dos modelos maiores do Llama 3.1, usando poda sistemática para remover parâmetros irrelevantes sem sacrificar a qualidade geral do modelo. A destilação de informações foi usada para transferir informações para modelos maiores, melhorando bastante o desempenho desses modelos leves.
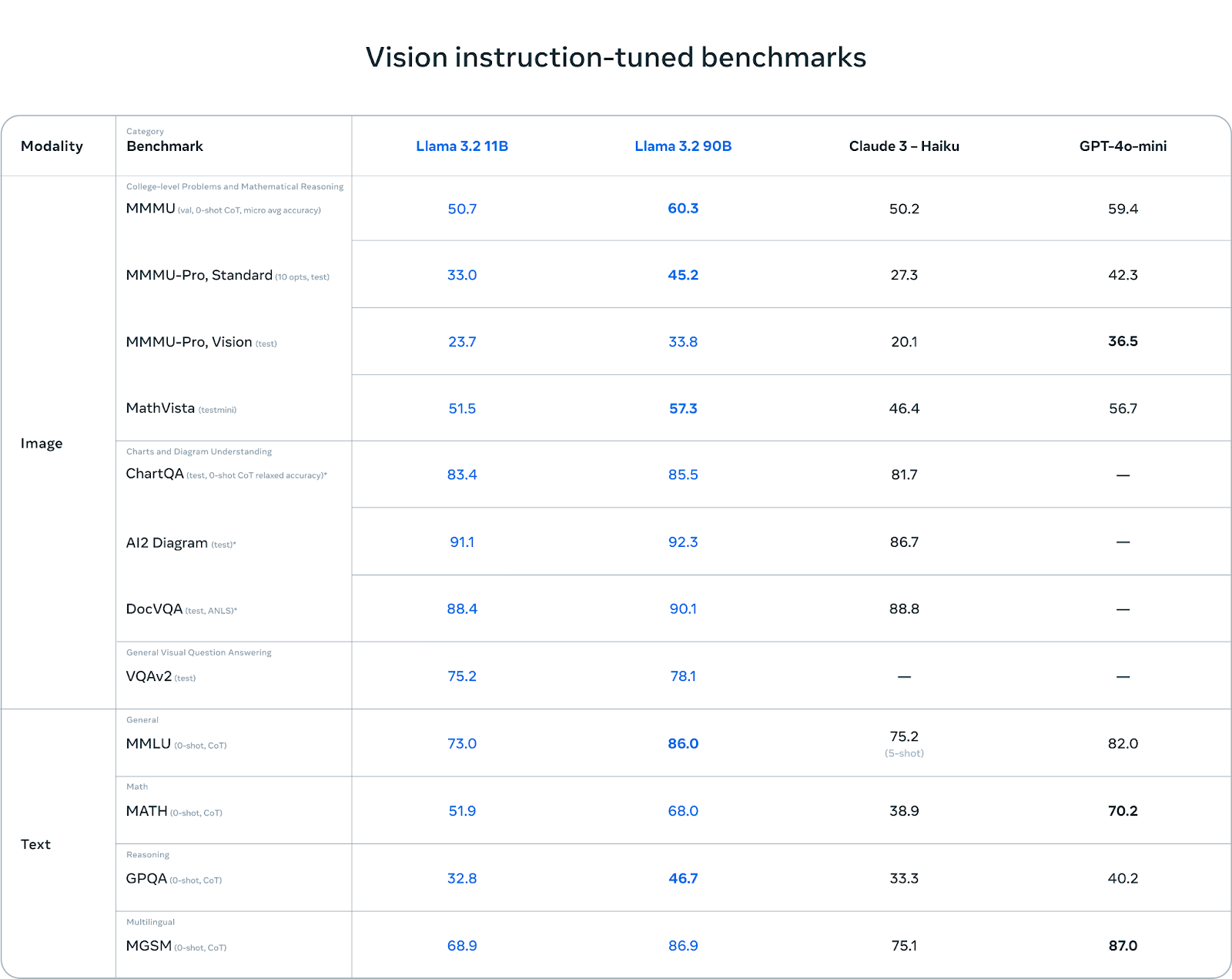
Llama 3.2 Vision: potencializando o raciocínio de imagem com os modelos 11B e 90B
Os LLMs de visão 11B e 90B no Llama 3.2 são projetados para funções visuais e cognitivas aprimoradas, introduzindo um modelo de arquitetura completamente novo que integra perfeitamente recursos visuais e de texto. Esses modelos podem lidar com compreensão em nível de documento, legenda de imagens e tarefas visuais básicas. Por exemplo, os modelos 11B e 90B podem analisar gráficos de negócios para determinar o melhor mês de vendas ou navegar por dados visuais complexos, como mapas, para fornecer informações de localização ou distâncias. O método de atenção inversa, desenvolvido combinando um codificador de imagem pré-treinado com um modelo de linguagem, permite que esses modelos extraiam informações de imagens com sucesso e criem legendas coerentes e significativas que preenchem a lacuna entre o texto e os dados visuais. Esta arquitetura permite que os modelos 11B e 90B concorram com modelos de circuito fechado, como o Claude 3 Haiku e o GPT4o-mini, em benchmarks de percepção visual, superando-os em tarefas que exigem percepção multimodal profunda. Eles são otimizados para configuração suave e programação personalizada usando ferramentas de código aberto, como torchtune e torchchat.
Principais conclusões da versão Llama 3.2:
- Apresentações de novos modelos: O Llama 3.2 apresenta duas novas categorias de modelos: os modelos leves 1B e 3B, somente texto, e os modelos de visão multimodal 11B e 90B. Os modelos 1B e 3B, projetados para uso na borda e em dispositivos móveis, usam 9 trilhões de tokens para treinamento, fornecendo funcionalidade avançada para resumo, acompanhamento de instruções e funções de reescrita. Esses modelos pequenos são ideais para aplicativos no dispositivo devido aos seus baixos requisitos de computação. Enquanto isso, os modelos de visão maior 11B e 90B trazem recursos multimodais para o conjunto Llama, que é mais eficaz em tarefas complexas de reconhecimento de imagem e texto e difere das versões anteriores.
- Comprimento do núcleo aprimorado: Uma das melhorias importantes no Llama 3.2 é o suporte para núcleo de 128K, especialmente nos modelos 1B e 3B. Esse comprimento de contexto estendido permite que entradas estendidas sejam processadas simultaneamente, melhorando tarefas que exigem longas análises de documentos, como resumos e raciocínio em nível de documento. Também permite que esses modelos lidem com grandes quantidades de dados com eficiência.
- Destilação de conhecimento para modelos leves: Os modelos 1B e 3B do Llama 3.2 se beneficiam do processo de destilação nos modelos maiores, especialmente as variantes 8B e 70B do Llama 3.1. Este processo de destilação transfere informações de modelos grandes para modelos pequenos, permitindo que modelos leves alcancem desempenho competitivo com uma redução significativa na sobrecarga computacional, tornando-os particularmente adequados para ambientes com uso intensivo de recursos.
- Modelos de percepção treinados com Big Data: Os modelos de linguagem visual (VLMs), 11B e 90B, são treinados em um grande conjunto de dados de 6 bilhões de pares imagem-texto, equipando-os com capacidades multimodais robustas. Esses modelos incluem CLIP do tipo MLP usando GeLU para codificador de visão, que é diferente da arquitetura MLP do Llama 3, que usa SwiGLU. Esta escolha de design melhora sua capacidade de lidar com tarefas complexas de percepção visual, tornando-os mais eficientes no pensamento visual e nas interações multimodais.
- Arquitetura de visão avançada: Os modelos de visão no Llama 3.2 incluem recursos arquitetônicos avançados, como a norma de camada normal do codificador de visão, em vez da norma de camada RMS vista em outros modelos, e incluem um multiplicador de porta usado nas regiões ocultas. Essa técnica de gating usa a função de ativação tanh para dimensionar o vetor de -1 a 1, o que ajuda a ajustar a saída dos modelos de visão. Estas inovações arquitetônicas contribuem para melhorar a precisão e a eficiência nas tarefas de pensamento visual.
- Métricas de desempenho: Os testes dos modelos Llama 3.2 mostram resultados promissores. O modelo 1B obteve pontuação de 49,3 no MMLU, enquanto o modelo 3B obteve pontuação de 63,4. O modelo multimodal de visão 11B obteve pontuação de 50,7 no MMMU, enquanto o modelo 90B obteve pontuação de 60,3 no lado de visão. Essas métricas destacam a vantagem competitiva dos modelos Llama 3.2 em tarefas baseadas em texto e visão, especialmente quando comparados com outros modelos líderes.
- Integração com UnslothAI para velocidade e eficiência: Os modelos 1B e 3B são totalmente integrados ao UnslothAI, permitindo correção 2x mais rápida, previsão 2x mais rápida e utilização de 70% de VRAM. Esta integração também melhora a aplicabilidade destes modelos em aplicações de tempo real. Estão em andamento trabalhos para integrar o VLM 11B e 90B na estrutura UnslothAI, estendendo esses benefícios de velocidade e eficiência a modelos multimodais maiores.
Essas melhorias tornam o Llama 3.2 um conjunto flexível e poderoso de modelos, adequado para uma ampla gama de aplicações, desde soluções leves de IA no dispositivo até tarefas multimodais complexas que exigem compreensão de imagens e textos em grande escala.
A conclusão
O lançamento do Llama 3.2 representa um marco importante no desenvolvimento de modelos de IA e modelos de visão. Sua arquitetura aberta e personalizável, forte suporte ao ecossistema e modelos leves e focados na privacidade fornecem uma solução atraente para desenvolvedores e empresas que buscam integrar IA em seus aplicativos de borda e no dispositivo. A disponibilidade de modelos pequenos e grandes garante que os usuários possam escolher a variante que melhor se adapta aos seus recursos computacionais e casos de uso.
Confira Modelos e detalhes de rostos abraçados. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Asif Razzaq é o CEO da Marktechpost Media Inc. Como empresário e engenheiro visionário, Asif está empenhado em aproveitar o poder da Inteligência Artificial em benefício da sociedade. Seu mais recente empreendimento é o lançamento da Plataforma de Mídia de Inteligência Artificial, Marktechpost, que se destaca por sua ampla cobertura de histórias de aprendizado de máquina e aprendizado profundo que parecem tecnicamente sólidas e facilmente compreendidas por um amplo público. A plataforma possui mais de 2 milhões de visualizações mensais, o que mostra sua popularidade entre os telespectadores.
⏩ ⏩ WEBINAR GRATUITO DE IA: 'Vídeo SAM 2: Como sintonizar seus dados' (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)


