
A regressão exponencial é um método estatístico avançado para encontrar equações estatísticas que melhor descrevem um conjunto de dados. Ao contrário da regressão convencional, que ajusta os dados a modelos predefinidos, a regressão logística procura propriedades estatísticas subjacentes a partir do zero. Esta abordagem ganhou destaque em campos científicos como física, química e biologia, onde os pesquisadores pretendem descobrir as leis fundamentais que regem os fenômenos naturais. Ao produzir estatísticas interpretáveis, a regressão do modelo permite aos cientistas interpretar padrões nos dados de forma intuitiva, tornando-a uma ferramenta valiosa na busca mais ampla de descobertas científicas automatizadas.
Um grande desafio na regressão simbólica é o grande espaço de busca por hipóteses potenciais. À medida que a complexidade dos dados aumenta, o número de soluções possíveis aumenta rapidamente, dificultando uma pesquisa eficaz. Os métodos tradicionais, como algoritmos genéticos, dependem de mutações aleatórias e cruzamentos para desenvolver soluções, mas muitas vezes precisam de ajuda com robustez e eficiência. Como resultado, existe uma necessidade urgente de formas mais eficientes de gerir grandes conjuntos de dados sem comprometer a precisão ou a interpretação, avançando assim a descoberta científica.
Vários métodos existentes tentam resolver este problema, cada um com as suas limitações. Algoritmos genéticos, que utilizam processos que imitam a evolução natural para avaliar o espaço de busca, continuam sendo os mais comuns. No entanto, estas técnicas tendem a aparecer aleatoriamente e não conseguem integrar informações específicas do domínio, o que atrasa a procura de soluções úteis. Outros métodos, como busca guiada por neurônios ou aprendizagem por reforço profundo, foram usados, mas ainda precisam ser ampliados. Esses métodos normalmente requerem extensos recursos computacionais e podem não ser aplicáveis a aplicações científicas do mundo real.
Pesquisadores da UT Austin, MIT, Foundry Technologies e da Universidade de Cambridge desenvolveram um novo método chamado LASR (Regressão Simbólica Abstrata Aprendida). Esta abordagem inovadora combina a regressão de características tradicionais com modelos linguísticos de grande escala (LLMs) para introduzir uma nova camada de eficiência e precisão. Os pesquisadores projetaram o LASR para construir uma biblioteca de conceitos abstratos e reutilizáveis para orientar o processo de geração de hipóteses. Ao utilizar LLMs, o método reduz a dependência de etapas evolutivas aleatórias e introduz uma abordagem orientada à informação que direciona a busca para as soluções mais adequadas.
A metodologia LASR está organizada em três fases principais. Na primeira etapa, evolução de hipóteses, funções genéticas como mutação e cruzamento são aplicadas ao conjunto de hipóteses. Porém, diferentemente dos métodos tradicionais, essas atividades são baseadas em conceitos abstratos produzidos pelos LLMs. Na segunda etapa, as hipóteses mais eficazes são resumidas nos conceitos do texto. Essas hipóteses são armazenadas na biblioteca para influenciar a busca de hipóteses em iterações subsequentes. Na etapa final, geração de conceitos, os conceitos armazenados são filtrados e desenvolvidos por meio de atividades adicionais orientadas pelo LLM. Este ciclo iterativo entre a abstração de conceitos e a evolução de hipóteses acelera a busca por soluções precisas e interpretáveis. O método garante que o conhecimento prévio seja utilizado e evolua junto com as ideias que estão sendo testadas.
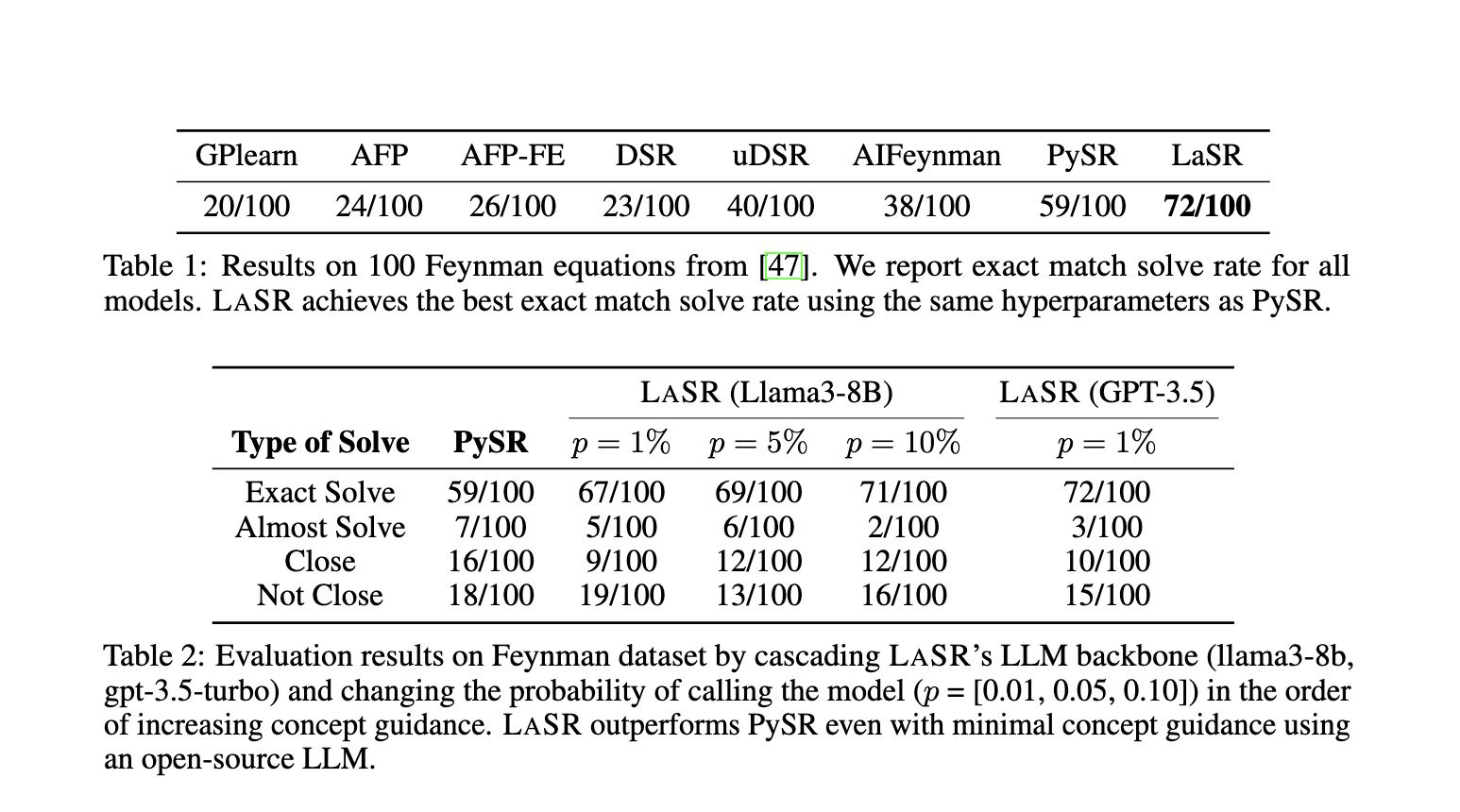
O desempenho do LASR foi testado em vários benchmarks, incluindo Equações de Feynman, que inclui 100 equações físicas extraídas das famosas *Feynman Lectures on Physics*. O LASR teve um desempenho significativamente melhor do que os métodos de regressão simbólica de última geração nesses testes. Enquanto os melhores métodos tradicionais resolveram 59 equações em 100, o LASR resolveu 66 com sucesso. Esta é uma melhoria significativa, especialmente considerando que o método foi testado com os mesmos hiperparâmetros dos seus concorrentes. Além disso, em benchmarks sintéticos concebidos para simular tarefas de descoberta científica do mundo real, o LASR demonstrou consistentemente um desempenho superior em comparação com os métodos de referência. Os resultados enfatizam a eficácia da combinação de LLMs com algoritmos evolutivos para melhorar a regressão simbólica.
Uma descoberta importante do método LASR foi a sua capacidade de encontrar novas regras de escala para grandes tipos linguísticos, um factor chave para melhorar o desempenho do LLM. Por exemplo, o LASR identificou um novo benchmark analisando dados do programa de avaliação BIG-Bench, um benchmark para LLMs. A equipe de pesquisa descobriu que aumentar o número de exemplos no contexto durante o treinamento do modelo melhora significativamente o desempenho de modelos com poucos recursos, mas esse ganho diminui à medida que o treinamento avança. Este novo insight indica uma aplicação mais ampla do LASR além da regressão simbólica, o que pode influenciar o desenvolvimento futuro dos LLMs.
No geral, o método LASR representa um importante passo em frente na regressão simbólica. Ao introduzir uma abordagem orientada pelo conhecimento e pela lógica, oferece uma solução para problemas de escala que há muito atormentam as abordagens tradicionais. O uso de LLMs para gerar conceitos abstratos fornece uma nova camada de eficiência, permitindo que o método convirja rapidamente para estatísticas precisas e interpretáveis. O sucesso do LASR em superar os métodos existentes em testes de benchmark e em descobrir novos insights sobre as regras de escalonamento do LLM destaca seu potencial para melhorar a regressão simbólica e o aprendizado de máquina.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
⏩ ⏩ WEBINAR GRATUITO DE IA: ‘Vídeo SAM 2: Como sintonizar seus dados’ (quarta-feira, 25 de setembro, 4h00 – 4h45 EST)


