
A Discovery Open-Vocabulary (OVD) visa encontrar objetos de argumentos pelo email do usuário fornecido. Embora o mais recente progresso melhore a capacidade de receber estratégias existentes, com três desafios importantes. Eles dependem fortemente de explicações de alta e alta qualidade, difíceis de medir. Seus abrigos são tipicamente curtos e não são ricos na condição, o que os faz intervir para explicar a relação entre as coisas. Esses modelos também são interações inadequadas em novos parágrafos do item, pretendem sincronizar os recursos de um item individual no texto do entendimento. Superar esse limite é importante para avançar o campo e cria modelos pertencentes a uma ativa e variável.
As formas anteriores tentaram melhorar o desempenho da OVD, fazendo uso de idiomas. Modelos como GLIP, GLIPV2 e DEVCLIPV3 incluem aprendizado e métodos diferentes para levantar o item para alinhar o texto do item. No entanto, esses processos ainda são importantes. Os diretórios estão descrevendo apenas um objeto sem olhar para qualquer lugar, incluindo o verdadeiro entendimento. O treinamento inclui corantes tingidos, portanto a maquiagem é um problema importante. Além de uma maneira de entender a imagem total das seleções de imagem, esses modelos não conseguem encontrar coisas novas corretamente.
Investigadores da Sun Yat-sen University, Peng Cheng Laborator, Tecnologia do Trabalho Provincial de Guangdong e Pazhou Laboradamente Proposta Proposta Proposta Proposta Proposta Proposta de Proposta de Proposta de Linguagem Adequada. Essa estrutura lança um novo conjunto de dados, GroundCap-1M, contendo 1,12 milhão de fotos, cada uma especificada com asas detalhadas com imagem detalhada e descrições curtas do distrito. A consolidação de ambas as informações é detalhada e curta para fortalecer o alinhamento do idioma na visão, fornecendo uma rica consideração de um item. Desenvolvendo um processo de aprendizado adequado, o Plano Estratégico usa duas vigilância, incluindo as perdas básicas que se adaptam aos rótulos de texto com as descobertas das disposições da legenda, ajudam as definições das imagens existentes. Um grande modelo de linguagem produz longas queixas descrevendo todas as cenas e frases curtas de objetos individuais, melhorando a precisão da aquisição, utilidade normal e reconhecimento de categoria incomum. Essa abordagem contribuiu para o aprendizado detalhado, fortalecendo a comunicação entre a aquisição do item e os grandes modelos da linguagem de qualidade.
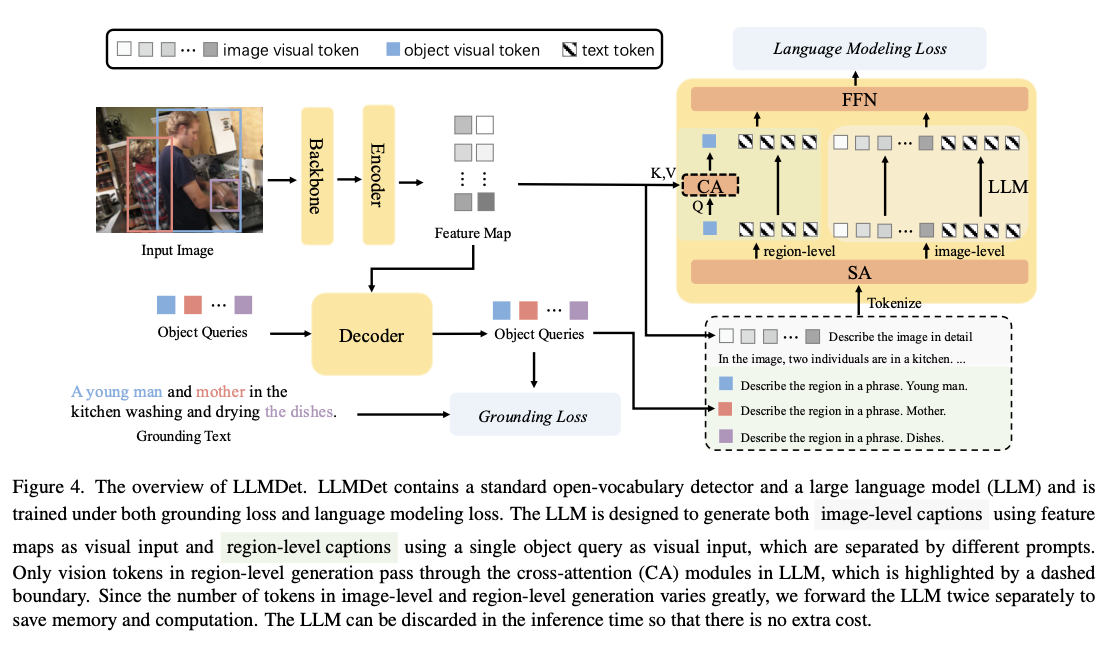
O tubo de treinamento contém duas categorias principais. Primeiro, o projeto foi projetado para adaptar os recursos visuais de um objeto visível com uma substância de um recurso de modelo maior. Na seção a seguir, o detector planeja coletivamente usando um modelo de idioma usando combinação de perdas e perda de palavras. Os dados utilizados para esse processo de treinamento foram incluídos em Coco, V3Det, GOLDG e LCS, para garantir que cada imagem seja definida com algumas descrições de baixa qualidade e altas. A construção é construída em Swin Transform Backbite, usando MM-Gdino como uma máquina de itens, incluindo as habilidades linguísticas. O modelo processa dois níveis: a definição das informações no nível da região sem instalar um sistema de linguagem de baixa qualidade durante o treinamento, a funcional computacional é armazenada à medida que o modelo de idioma é descartado de tempo.
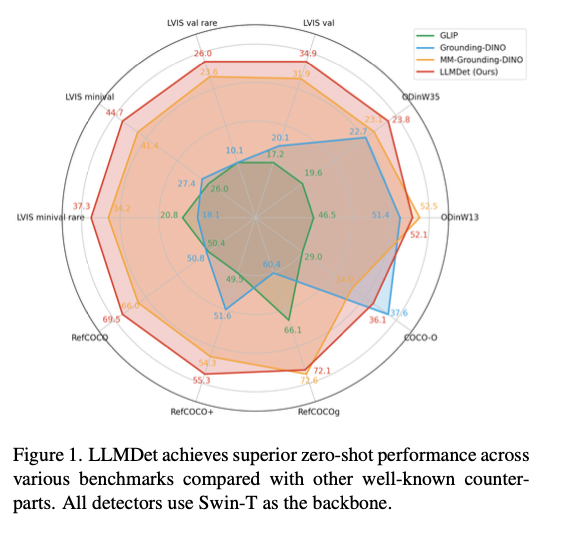
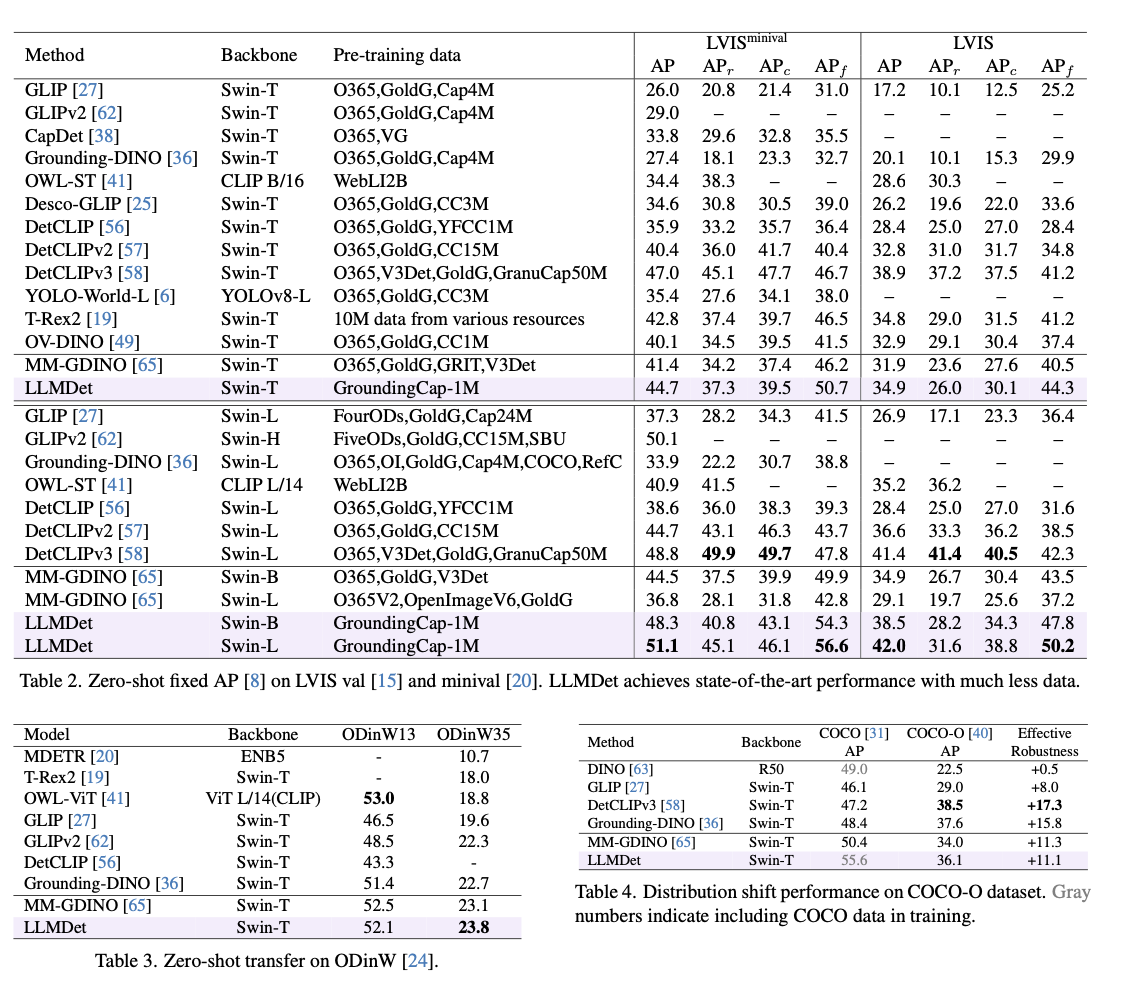
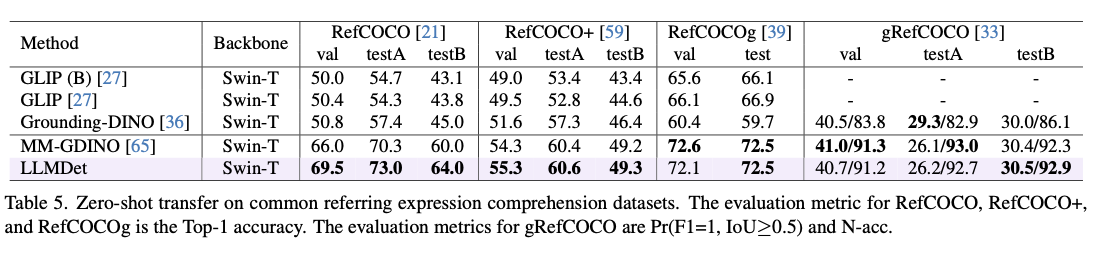
Este método recebe um desempenho de última geração sobre os benchmarks abertos de palavras abertas, com a precisão mais em desenvolvimento do recebimento, produção normal e estabilidade. Ele excede os modelos frontais em 3,3% -14,3% de AP em LVIS, com desenvolvimento claro na identificação de classes incomuns. No Odinw, o banco de aquisição de um item acima de diferentes antecedentes, indica a melhor transferência de zero shot. Dominar em transe de domínio também é garantido por seu desempenho avançado em Coco-O, equilibrando variações sob variação ambiental. Nas tarefas de entender o entendimento do entendimento, recebe a melhor precisão do refroco, refco +e refcocog, confirmando sua capacidade de alinhar a interpretação. O teste de ablação mostra que a imagem e a integração no nível da imagem fazem contribuições importantes na operação, especialmente nos ganhos de algo extraordinário. Mais uma vez, incluindo o detector instruído em modelos multimodais, promovendo o alinhamento da opinião, o acúmulo de prensagem e melhora a precisão de responder às perguntas visualizadas.
Ao usar grandes modelos de vocabulário, o LLMDET fornece um paradig de aprendizado formal e eficiente. Esse desenvolvimento de desenvolvimento dos feixes OVD existentes, através do funcionamento de alguns bancos do feijão e da aquisição da geração zero e da aquisição de categoria incomum. A integração do leitor de visão promove a configuração de domínio cruzado e aumenta muitas interações, o que indica uma promessa do idioma na aquisição do item.
Enquete o papel. Todo o crédito deste estudo é pesquisado para este projeto. Além disso, não se esqueça de seguir Sane e junte -se ao nosso Estação de telégrafo incluindo LinkedIn grtópico. Não se esqueça de se juntar ao nosso 75k + ml subreddit.
🚨 Recomendado para um código aberto de IA' (Atualizado)
Aswin AK é consultor em Marktechpost. Ele persegue seus dois títulos no Instituto Indiano de Tecnologia, Kharagpur. Você está interessado na leitura científica e científica e de máquinas, que traz uma forte formação e experiências educacionais para resolver os desafios reais de desenvolvimento de fundo.
✅ [Recommended] Junte -se ao nosso canal de telégrafo
: um novo método que melhora a precisão na geração de texto longo combinando memória de trabalho")

")