
Os Modelos de Grandes Idiomas (LLMs) revolucionaram a resposta a perguntas em textos longos (LCQA), uma tarefa complexa que requer pensar em textos extensos para fornecer respostas precisas. Embora os LLMs mais recentes com conteúdo longo, como Gemini e GPT4-128k, possam processar todos os documentos diretamente, eles enfrentam o fenômeno de “perda no meio”, onde informações importantes entre documentos geralmente levam a respostas pequenas ou incorretas. Os sistemas de geração aumentada de recuperação (RAG) tentam resolver isso usando técnicas de agregação de comprimento fixo, mas enfrentam suas limitações. Estes incluem a perturbação da estrutura contextual, informações incompletas sobre passagens e desafios com pouca evidência de congestionamento em documentos longos, onde o ruído pode interferir na capacidade dos LLMs de identificar com precisão informações importantes. Estas questões em conjunto dificultam o desenvolvimento de programas de LCQA credíveis.
Muitas abordagens surgiram para lidar com os desafios de responder a perguntas de textos longos. Os métodos LLM de contexto longo se enquadram em duas categorias: métodos baseados em treinamento, como Position Interpolation, YaRN e LongLoRA, que fornecem melhor desempenho, mas requerem recursos significativos, e métodos mal ajustados, como atenção limitada e compressão de contexto, que fornecem um plug. soluções -and-play a baixo custo. Os sistemas RAG tradicionais tentaram melhorar a qualidade das respostas dos LLMs utilizando fontes de informação externas, mas a sua inclusão directa de episódios devolvidos conduziu a informações incompletas e a ruído. Modelos RAG avançados introduziram soluções como filtragem das informações retornadas, uso de técnicas sem blocos para preservar a semântica e uso de métodos de recuperação eficientes. A configuração específica do local também surgiu como uma estratégia para melhorar os componentes do RAG, com foco na melhoria dos resultados de recuperação e na produção de resultados altamente personalizados.
Pesquisadores do Instituto de Engenharia da Informação, Academia Chinesa de Ciências, Escola de Segurança Cibernética, Universidade da Academia Chinesa de Ciências, Universidade de Tsinghua e Zipu AI apresentaram LongRAGuma solução abrangente para o desafio LCQA usando um paradigma de sistema robusto e de visão dupla que inclui quatro componentes plug-and-play: um recuperador híbrido, um extrator de informações aumentadas por LLM, um filtro direcionado por CoT e um gerador aumentado por LLM . Uma abordagem de inovação de sistemas trata tanto da compreensão do contexto global quanto da identificação de insights autênticos. O gerador de contexto de longo prazo utiliza uma estratégia de mapeamento para transformar os segmentos retornados em um espaço semântico de alta dimensão, preservando as relações de contexto, enquanto o filtro guiado por CoT utiliza uma cadeia de raciocínio para fornecer pistas globais e filtrar com precisão informações irrelevantes. Essa abordagem de visão dupla melhora muito a capacidade do sistema de processar cenários longos e complexos, mantendo a precisão. A arquitetura do sistema é acoplada a um pipeline de dados de instruções automatizado para otimização, permitindo recursos robustos de “seguir as instruções” e fácil adaptação de domínio.
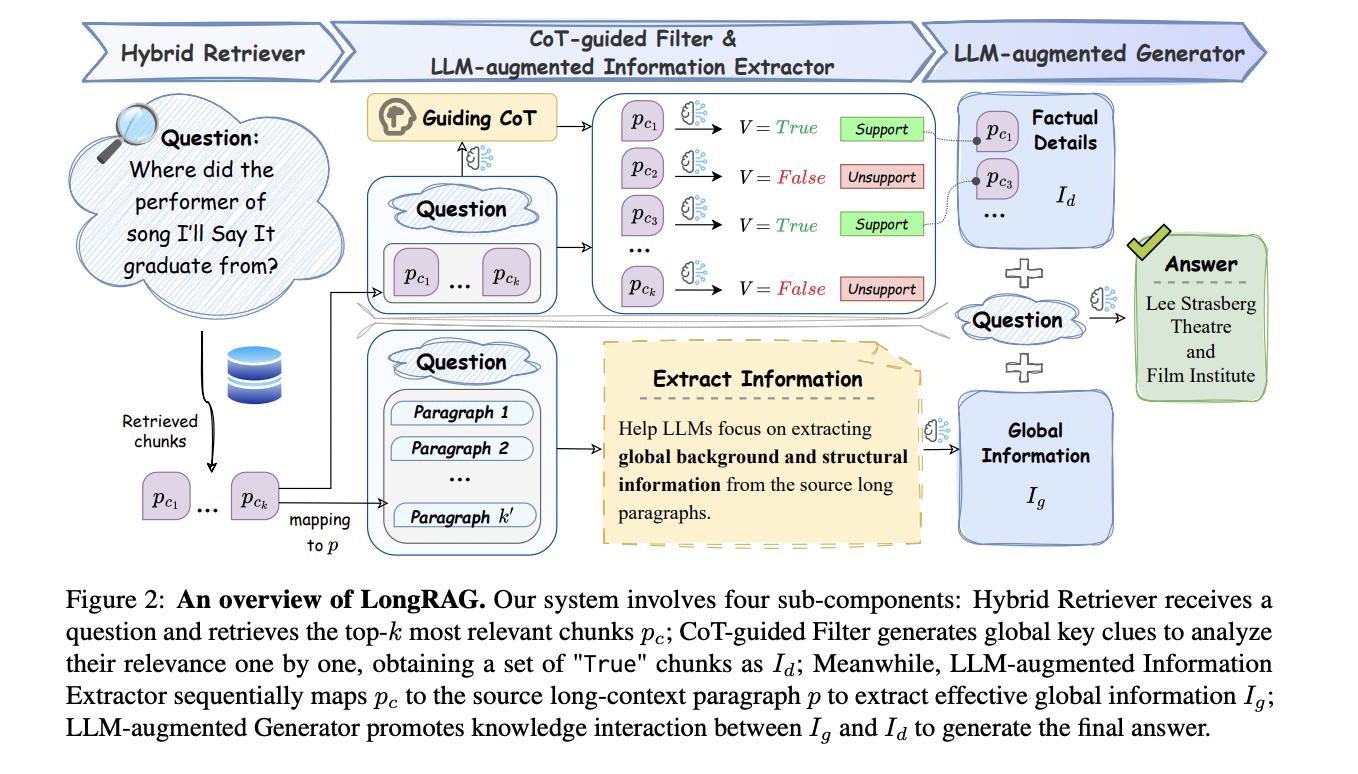
A estrutura LongRAG consiste em quatro componentes complexos que funcionam em harmonia. O detector integrado usa uma arquitetura de codificador duplo com janelas deslizantes para segmentação, incluindo recuperação rápida de caracteres grosseiros e interações semânticas ajustadas usando FAISS. O gerador de conhecimento aumentado pelo LLM aborda evidências distribuídas mapeando fragmentos recuperados de volta às categorias de origem usando uma função de mapa, preservando a ordem semântica e as relações contextuais. O filtro direcionado ao CoT utiliza uma estratégia de dois estágios: primeiro gera um conjunto de pensamentos de uma perspectiva global, depois utiliza essas informações para avaliar e filtrar os episódios com base em sua relevância para a consulta. Finalmente, o gerador aumentado de LLM combina conhecimento global e informações factuais filtradas para gerar respostas precisas. O desempenho do sistema é otimizado por instruções de programação usando 2.600 pontos de dados de alta qualidade do LRGinstruction, com modelos treinados usando técnicas avançadas como DeepSpeed e atenção flash.
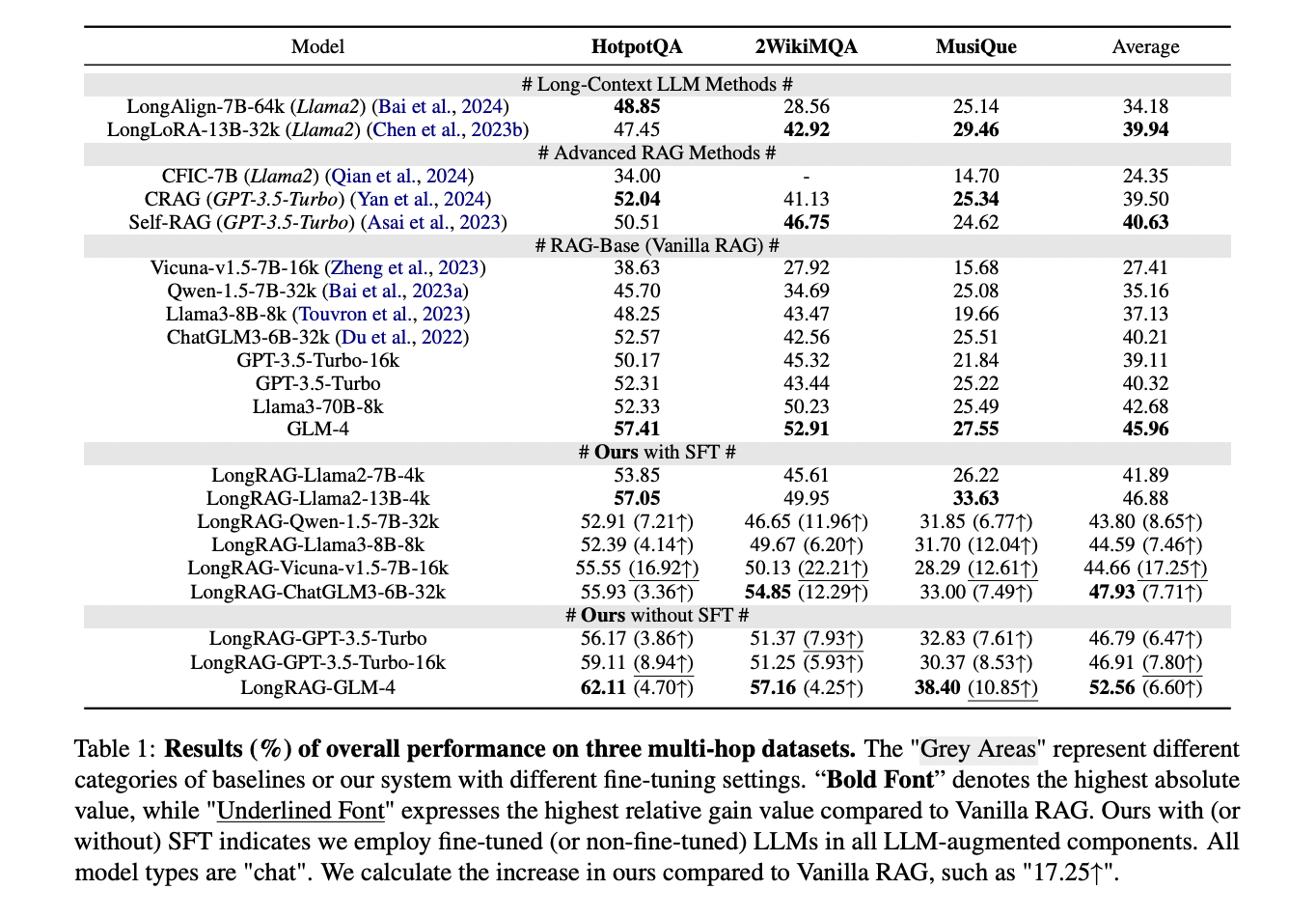
LongRAG mostra desempenho superior em todos os aspectos de comparações múltiplas. Comparado aos métodos LLM de contexto longo, como LongAlign e LongLoRA, o sistema atinge alto desempenho em todos os conjuntos de dados, especialmente na localização de informações factuais importantes que outros modelos muitas vezes perdem nos estágios intermediários do documento. Em comparação com esquemas RAG avançados, o LongRAG apresenta uma melhoria de 6,16% em relação aos seus principais concorrentes, como o Self-RAG, principalmente devido ao tratamento de informações autênticas e consultas complexas de vários saltos. Uma melhoria dramática do sistema é vista em comparação com o Vanilla RAG, que mostra um aumento de desempenho de 17,25%, devido à sua preservação superior do fundo paralelo de conteúdo distante da estrutura. Notavelmente, o desempenho do LongRAG se estende a todos os tipos de linguagens pequenas e grandes, com o ChatGLM3-6B-32k ajustado superando o GPT-3.5-Turbo não ajustado, mostrando uma arquitetura de sistema forte e capacidades eficazes de seguimento de comandos.
LongRAG surge como uma solução robusta no campo de consultas longas que são respondidas com sua dupla visão de informações. O sistema aborda eficazmente dois desafios principais que têm atormentado os métodos existentes: recolha incompleta de informações de conteúdo de longo alcance e identificação precisa de informações autênticas em ambientes ruidosos. Por meio de avaliação multidimensional abrangente, o LongRAG não apenas mostra desempenho superior aos LLMs com conteúdo longo, métodos RAG avançados e Vanilla RAG, mas também uma relação custo-benefício significativa. Os componentes do sistema plug-and-play alcançam melhores resultados do que o GPT-3.5-Turbo enquanto usam LLMs menores para tamanho de parâmetro, tornando-o uma solução eficiente para implantação local sem depender de recursos de API caros.
Confira Papel de novo GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[Trending] LLMWare apresenta Model Depot: uma coleção abrangente de modelos de linguagem pequena (SLMs) para PCs Intel
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.
Ouça nossos podcasts e vídeos de pesquisa de IA mais recentes aqui ➡️


 para tarefas como desduplicação difusa, paralelismo e padrão otimizado para CPU")