
A geração de vídeo por LLMs é um campo emergente com uma trajetória de crescimento promissora. Embora os Modelos Autoregressivos de Grandes Linguagens (LLMs) tenham tido muito sucesso na geração de tokens sequenciais e longos no processamento de linguagem natural, seu uso na geração de vídeos é limitado a vídeos curtos de alguns segundos. Para resolver isso, os pesquisadores introduziram o Loong, um gerador de vídeo automatizado baseado em LLM, capaz de gerar vídeos de minutos de duração.
Treinar um modelo de produção de vídeo como Loong envolve um processo único. O modelo é treinado do zero, com tokens de texto e tokens de vídeo tratados como sequências concatenadas. Os pesquisadores propuseram um método de treinamento contínuo de curto a longo prazo e um esquema de redimensionamento de perdas para reduzir o problema de desequilíbrio de perdas em treinamentos de vídeo longos. Isso permite que Loong seja treinado em um vídeo de 10 segundos e depois expandido para produzir vídeos mais longos, em nível de minuto, com base em comandos de texto.
No entanto, a grande produção de vídeo é complexa e tem muitos desafios pela frente. Primeiro, existe o problema da perda desigual durante o treino. Quando treinado para fins de previsão do próximo token, prever tokens de quadros iniciais a partir de informações de texto é mais difícil do que prever tokens de quadros posteriores com base em quadros anteriores, resultando em perdas desiguais durante o treinamento. À medida que a duração do vídeo aumenta, a perda cumulativa dos tokens leves ofusca a perda dos tokens pesados, que dominam a direção do gradiente. Segunda vez, O modelo prevê o próximo token com base nos tokens de verdade, mas depende de sua previsão durante a previsão. Essa diferença provoca o acúmulo de erros, principalmente pela forte dependência de frames e múltiplos tokens de vídeo, o que leva à degradação da qualidade visual na direção de um vídeo longo.
Para reduzir o desafio de dificuldade de token de vídeo desigual, Os pesquisadores propuseram uma estratégia de treinamento de curto a longo prazo para perda de peso, que é mostrada a seguir:
Treinamento contínuo de curto a longo prazo
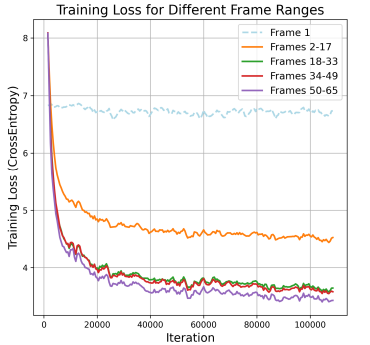
O treinamento é dividido em três etapas, que aumentam a duração do treinamento:
Seção 1: Um modelo pré-treinado realizando processamento de texto para imagem em um grande conjunto de dados de imagens estáticas ajuda o modelo a estabelecer uma base sólida para modelar a aparência de cada quadro.
Seção 2: Um modelo treinado em imagens e videoclipes curtos, onde o modelo aprende a capturar a dependência temporal de
Seção 3: O número de quadros de vídeo aumentou e o treinamento conjunto está em andamento
Loong projetou um sistema de duas partes, um token de vídeo que compacta vídeos em tokens e um decodificador e transformador que prevê os próximos tokens de vídeo com base em tokens de texto.
Loong usa uma arquitetura CNN 3D de tokenizadorinspirado em MAGViT2. O modelo trabalha com vídeos de baixa resolução e deixa alta resolução para pós-processamento. O Tokenizer pode compactar um vídeo de 10 segundos (65 quadros, resolução de 128*128) em uma sequência de 17*16*16 tokens separados. A geração de vídeo autoregressiva baseada em LLM converte quadros de vídeo em tokens discretos, permitindo que tokens de texto e vídeo formem uma sequência coerente. O processamento de texto para vídeo é modelado como previsão automática de tokens de vídeo com base em tokens de texto usando apenas transformadores decodificadores.
Modelos de linguagem maiores podem acomodar vídeos mais longos, mas exceder a duração treinada corre o risco de acumular erros e degradar a qualidade. Existem muitas maneiras de consertar isso:
- Recodificação de token de vídeo
- Estratégia de amostragem
- Super-resolução e refinamento
O modelo utiliza a arquitetura LLaMA, com tamanhos que variam de 700M A 7B de parâmetros. Os modelos são treinados do zero, sem pesos de texto pré-treinados. O vocabulário contém 32.000 tokens de texto, 8.192 tokens de vídeo e 10 tokens especiais (total de 40.202). O token de vídeo repete o MAGViT2, usando uma estrutura CNN 3D que é a causa do primeiro quadro de vídeo. A dimensão espacial é comprimida em 8x e a dimensão temporal em 4x. Clustering Vector Quantization (CVQ) é usado para quantização, melhorando o uso do livro de códigos em relação ao VQ padrão. Um token de vídeo possui parâmetros de 246 milhões.

O modelo Loong produz vídeos longos com aparência consistente, alta faixa dinâmica e transições naturais de cena. Loong é modelado em tokens de texto e tokens de vídeo em uma sequência integrada e supera os desafios do treinamento em vídeo longo com um programa de treinamento contínuo curto a longo e recuperação de perda de peso. O modelo pode ser distribuído para ajudar artistas visuais, produtores de filmes e fins de entretenimento. Mas, ao mesmo tempo, pode ser usado incorretamente para criar conteúdo falso e fornecer informações enganosas.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Interessado em promover sua empresa, produto, serviço ou evento para mais de 1 milhão de desenvolvedores e pesquisadores de IA? Vamos trabalhar juntos!
Nazmi Syed é estagiária de consultoria na MarktechPost e está cursando bacharelado em ciências no Instituto Indiano de Tecnologia (IIT) Kharagpur. Ele tem uma profunda paixão pela Ciência de Dados e está explorando ativamente a ampla aplicação da inteligência artificial em vários setores. Fascinada pelos avanços tecnológicos, a Nazmi está comprometida em compreender e aplicar inovações de ponta em situações do mundo real.


