
Modelos de Linguagem em Grande Escala (LLMs) mostraram progresso notável em tarefas de processamento de linguagem natural, incentivando os pesquisadores a explorar abordagens semelhantes para integração de texto e imagem. Ao mesmo tempo, os modelos de distribuição tornaram-se o método dominante na produção visual. No entanto, as diferenças funcionais entre estas duas abordagens apresentam um grande desafio no estabelecimento de uma abordagem unificada para tarefas linguísticas e cognitivas. Desenvolvimentos recentes como o LlamaGen se aprofundaram na geração automática de imagens usando diferentes tokens de imagem; no entanto, é ineficiente devido ao grande número de tokens de imagem em comparação com tokens de texto. Surgiram métodos não automatizados, como MaskGIT e MUSE, reduzindo o número de etapas de decodificação, mas falhando em produzir imagens de alta qualidade e alta resolução.
Os esforços existentes para resolver os desafios da fusão texto-imagem concentram-se principalmente em duas abordagens: geração de imagens baseada em transmissão e geração de imagens baseada em tokens. Modelos de difusão, como Difusão Estável e SDXL, fizeram progressos significativos trabalhando em espaços ocultos comprimidos e introduzindo técnicas como microcondições e treinamento multifatorial. A integração de estruturas de transformadores, como visto em DiT e U-ViT, melhorou a potência dos modelos de distribuição. No entanto, estes modelos ainda enfrentam desafios na implementação e medição em tempo real. Métodos baseados em tokens, como MaskGIT e MUSE, introduziram modelagem de imagem latente (MIM) para superar as demandas computacionais de métodos automatizados.
Pesquisadores do Alibaba Group, Skywork AI, HKUST (GZ), HKUST, Zhejiang University e UC Berkeley propuseram Meissonic, uma nova abordagem para aumentar a fusão incontrolável de texto-imagem MIM a um nível comparável à difusão de última geração modelos como SDXL. A Meissonic usa uma ampla variedade de arquiteturas, técnicas avançadas de codificação espacial e condições avançadas de amostragem para melhorar o desempenho e a eficiência do MIM. O modelo usa dados de treinamento de alta qualidade, condições mínimas informadas por pontuações de preferência humana e inclui camadas de compressão para melhorar a fidelidade e resolução da imagem. Meissonic pode produzir imagens com resolução de 1024 × 1024 e muitas vezes supera os modelos existentes na produção de imagens de alta qualidade e alta resolução.
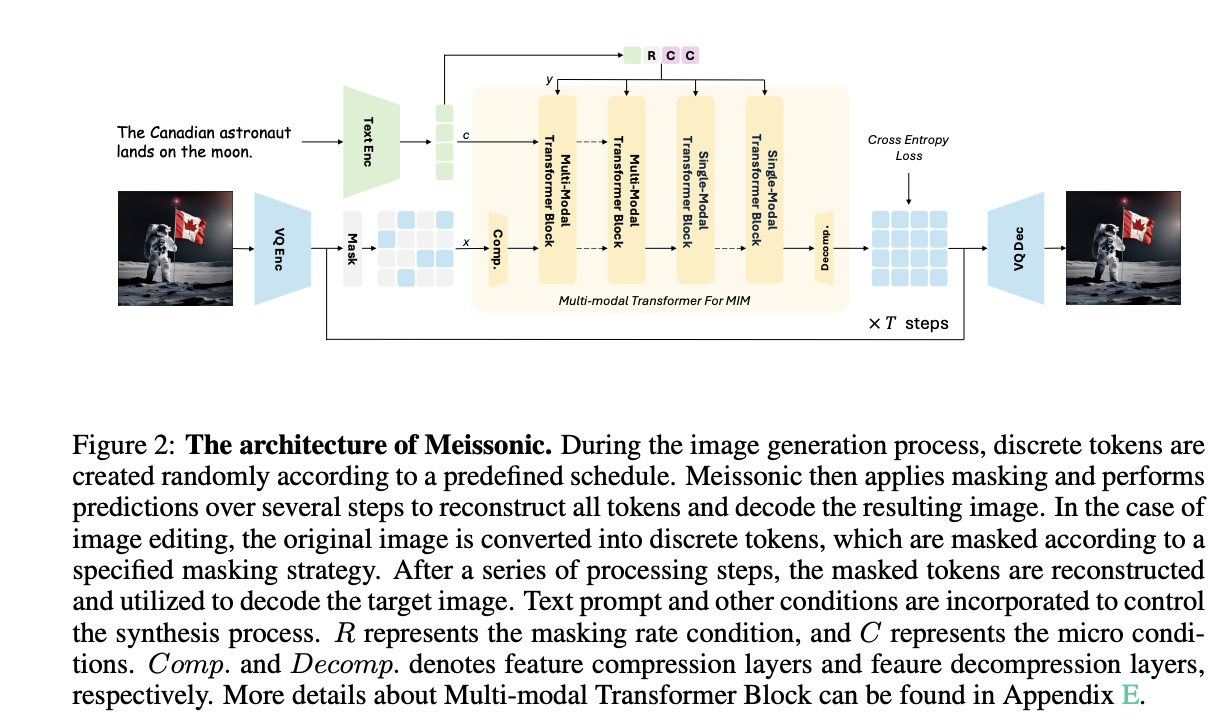
A arquitetura Meissonic inclui um codificador de texto CLIP, um codificador de imagem vetorial quantizado (VQ) e um núcleo Transformer multimodo para combinar o desempenho de texto para imagem:
- O modelo VQ-VAE converte pixels de imagem bruta em tokens semânticos discretos usando um livro de códigos aprendido.
- Um editor de texto CLIP bem ajustado com 1.024 dimensões ocultas é usado para alto desempenho.
- O núcleo do Transformer multimodo usa taxas de amostragem e Rotary Spatial Embedding para codificação espacial.
- Camadas de compactação de recursos são usadas para lidar muito bem com a reprodução de alta definição.
A arquitetura também inclui camadas QK-Norm e usa recorte de gradiente para melhorar a estabilidade do treinamento e reduzir problemas de perda de NaN durante o treinamento distribuído.
O Meissonic, desenvolvido com 1 bilhão de parâmetros, funciona perfeitamente em 8 GB de VRAM, facilitando a visualização e o ajuste. Comparações qualitativas demonstram a qualidade de imagem e as capacidades de alinhamento de texto para imagem da Meissonic. Testes humanos usando K-Sort Arena e GPT-4 mostram que Meissonic alcança desempenho comparável ao DALL-E 2 e SDXL em classificação humana e alinhamento de texto, com desempenho aprimorado. Meissonic foi comparado com modelos de última geração usando o conjunto de dados EMU-Edit para tarefas de edição de imagens, que inclui sete tarefas diferentes. O modelo mostrou flexibilidade tanto na edição direcionada quanto na edição sem máscara, alcançando bom desempenho sem treinamento especial em dados de edição de imagens ou conjuntos de dados instrucionais.
Concluindo, os pesquisadores apresentam o Meissonic, um método para propor síntese de texto MIM não automatizada. O modelo inclui novos recursos, como estrutura de transformador integrada, codificação espacial aprimorada e níveis de mascaramento variáveis para alcançar alto desempenho na reprodução de imagens de alta resolução. Apesar de seu tamanho compacto de parâmetro de 1B, a Meissonic supera modelos de distribuição maiores, permanecendo acessível para GPUs de consumo. Além disso, a Meissonic está alinhada com a tendência emergente de aplicativos offline de conversão de texto em imagem em dispositivos móveis, conforme demonstrado pelas inovações recentes do Google e da Apple. Ele melhora a experiência do usuário e a privacidade na tecnologia de imagem móvel, capacitando os usuários com ferramentas criativas e garantindo a segurança dos dados.
Confira Papel de novo Modelo. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso Mais de 50k ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] Melhor plataforma para modelos ajustados: mecanismo de inferência Predibase (avançado)

Sajjad Ansari se formou no último ano do IIT Kharagpur. Como entusiasta da tecnologia, ele examina as aplicações da IA com foco na compreensão do impacto das tecnologias de IA e suas implicações no mundo real. Seu objetivo é transmitir conceitos complexos de IA de maneira clara e acessível.


