
Compreender documentos de várias páginas e vídeos de notícias é uma tarefa comum no cotidiano humano. Para lidar com tais situações, os Modelos Multimodais de Grandes Linguagens (MLLMs) devem ser equipados com a capacidade de compreender múltiplas imagens com informações textuais ricas que sejam visíveis no ambiente. No entanto, compreender as imagens dos documentos é mais desafiador do que as imagens naturais, pois requer uma visão mais clara para ver todos os documentos. Os métodos existentes adicionam um codificador de alta resolução ou cortam imagens de alta resolução em imagens menores de baixa resolução, ambos com limitações.
Pesquisadores anteriores tentaram resolver o desafio de compreender imagens de texto usando várias técnicas. Outros trabalhos são propostos para adicionar um codificador de alta resolução para melhor capturar as informações de texto refinado em imagens de documentos. Outros optaram por cortar imagens de alta resolução em imagens menores e de baixa resolução e deixar o modelo de macrolinguagem entender suas relações.
Embora estes métodos tenham alcançado um desempenho promissor, eles enfrentam um problema comum – um grande número de tokens visuais são necessários para representar uma única imagem de um documento. Por exemplo, o modelo InternVL 2 custa em média 3 mil tokens virtuais para um documento de página única ser compreendido no benchmark DocVQA. Essas longas sequências de tokens visuais não apenas resultam em longos tempos de decisão, mas também utilizam uma quantidade significativa de memória da GPU, limitando bastante seu uso em situações que envolvem a compreensão de documentos ou vídeos completos.
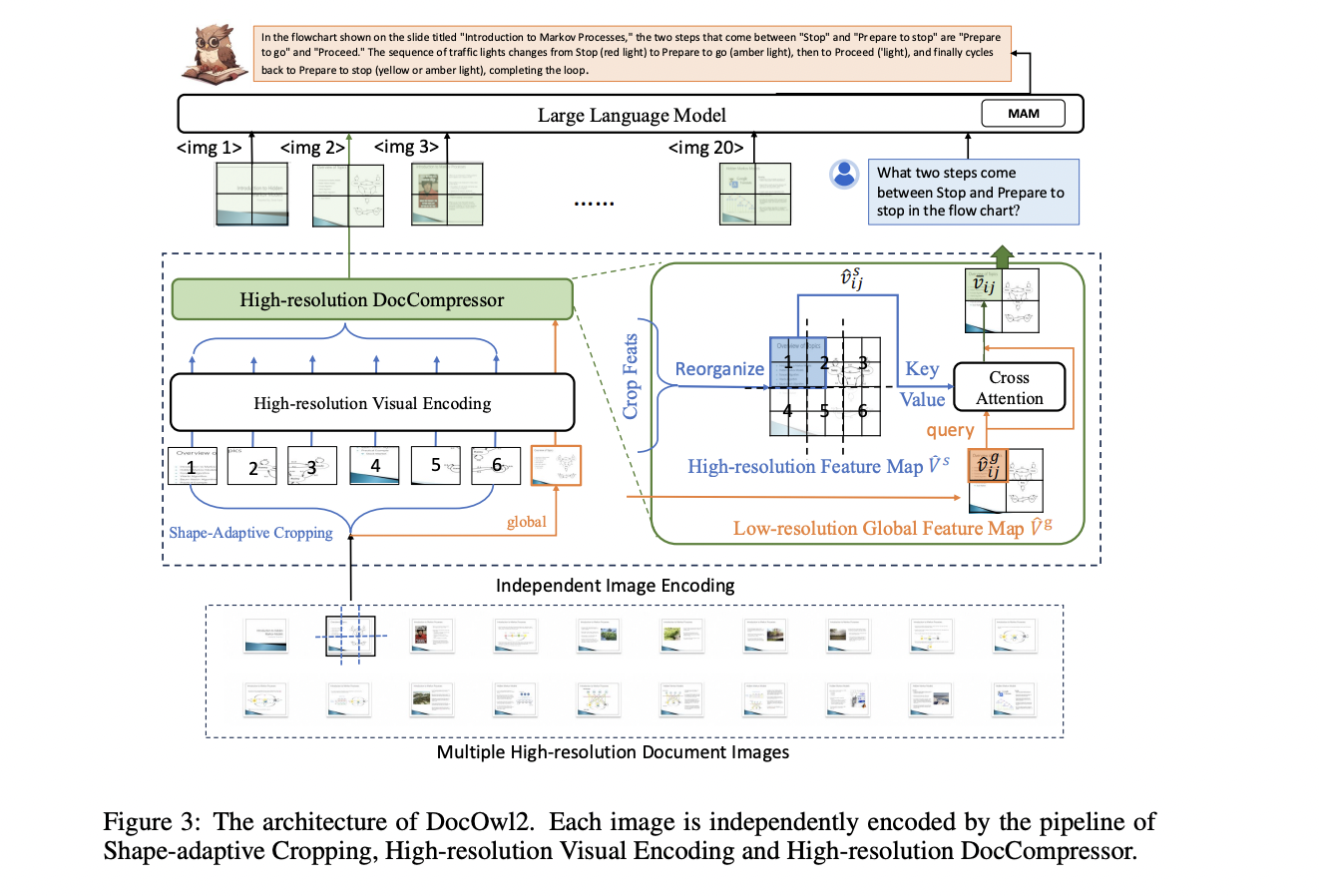
Pesquisadores do Grupo Alibaba e da Universidade Renmin da China propuseram uma construção robusta chamada DocCompressor de alta resolução. Este método utiliza os recursos visuais de uma imagem global de baixa resolução como um guia de compressão (consulta), uma vez que um mapa de recursos globais pode capturar efetivamente todas as informações estruturais de um documento.
Em vez de considerar todos os recursos de alta resolução, o DocCompressor de alta resolução coleta um conjunto de recursos de alta resolução que possuem as mesmas posições na imagem bruta que os recursos de compactação de cada consulta no mapa de recursos global. Este método de conhecer a estrutura ajuda a resumir melhor as informações do texto dentro de uma determinada área da estrutura.
Além disso, os pesquisadores argumentam que a compactação dos recursos visuais após o módulo de visão para texto do Modelo Multimodal de Grande Linguagem pode preservar melhor a semântica do texto nas imagens do documento, pois é semelhante a resumir os textos no Processamento de Linguagem Natural. .
O modelo DocOwl2 usa um módulo de corte adaptável à forma e um codificador de visão de baixa resolução para combinar imagens de documentos de alta resolução. O módulo de corte adaptável à forma corta a imagem bruta em várias subimagens de baixa resolução, e um codificador de visão de baixa resolução é usado para codificar as subimagens e a imagem do mundo. O modelo então usa um módulo de visão para texto chamado H-Reducer para combinar os recursos visuais horizontais e combinar as dimensões dos recursos de visão com o Modelo de Linguagem Grande. Além disso, o DocOwl2 inclui um compressor de alta resolução, que é o principal componente do DocCompressor de alta resolução. Este compressor usa os recursos visuais da imagem global de baixa resolução como uma consulta e coleta um conjunto de recursos de alta resolução com posições semelhantes na imagem bruta como os elementos de compactação para cada consulta. Este método de conhecer a estrutura ajuda a resumir melhor as informações do texto dentro de uma determinada área da estrutura. Finalmente, os tokens visuais compactados de múltiplas imagens ou páginas são combinados com comandos textuais e inseridos em um grande modelo de linguagem para compreensão multimodal.
Os pesquisadores compararam o modelo DocOwl2 com modelos multimodais de linguagem grande de última geração em 10 benchmarks de compreensão de documentos de imagem única, 2 benchmarks de compreensão de documentos de várias páginas e 1 benchmark de compreensão de vídeo de texto. Eles consideraram o desempenho da resposta à consulta (medido pelo ANLS) e a latência do primeiro token (em segundos) para testar o desempenho de seu modelo. Para a tarefa de compreensão de um único documento de imagem, os pesquisadores dividiram a base em três grupos: (a) modelos sem Large Language Models como decodificadores, (b) LLMs multimodais com média de mais de 1.000 tokens visuais por imagem de documento, e ( c) A maioria dos LLMs tem menos de 1.000 tokens virtuais.
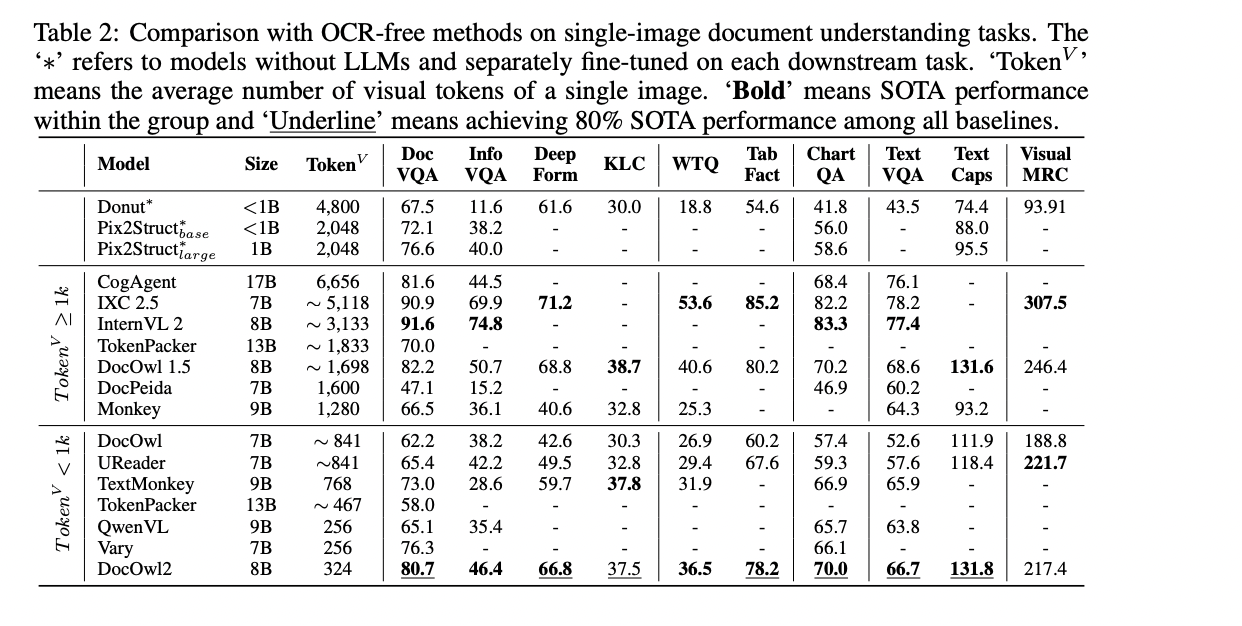
Os resultados mostram que, embora os modelos bem ajustados para cada conjunto de dados fluviais tenham um bom desempenho, os LLMs multimodais mostraram o poder para a compreensão geral do documento OCR gratuito. Comparado com outros LLMs multimodais com menos de 1.000 tokens virtuais, o modelo DocOwl2 obteve desempenho melhor ou comparável em 10 benchmarks. Notavelmente, com poucos tokens visíveis, DocOwl2 dos modelos mais eficientes como TextMonkey e TokenPacker, que também visa compactar tokens visíveis, mostrando o desempenho do DocCompressor de alta resolução.
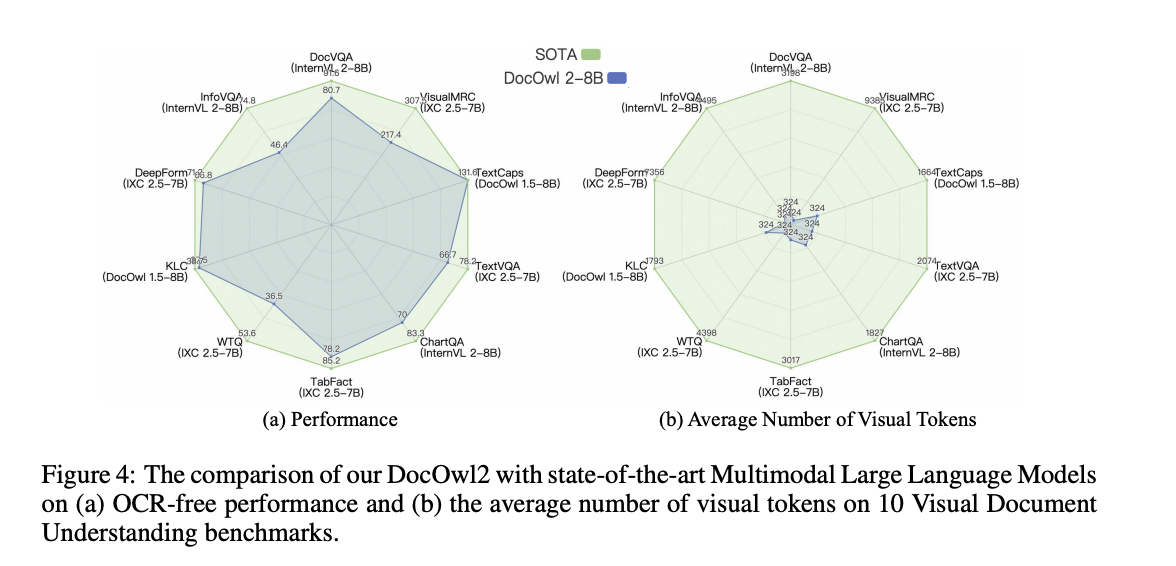
Além disso, em comparação com LLMs multimodais de última geração com mais de 1.000 tokens visuais, o modelo DocOwl2 alcançou mais de 80% de seu desempenho usando menos de 20% de tokens visuais. Para tarefas de compreensão de documentos de várias páginas e de vídeo rico em texto, o modelo DocOwl2 também mostrou alto desempenho e latência de primeiro token muito baixa em comparação com outros LLMs multimodais que podem alimentar mais de 10 imagens em uma única GPU A100-80G.
Esta pesquisa está chegando mPLUG-DocOwl2Um grande modelo de linguagem multimodal para compreensão eficiente de documentos de várias páginas sem OCR. A arquitetura robusta do DocCompressor de alta resolução compacta cada imagem de um documento de alta resolução em apenas 324 tokens usando atenção inversa com recursos visuais globais como diretriz. Em benchmarks de imagem única, o DocOwl2 supera os métodos de compactação existentes e corresponde aos MLLMs de última geração, usando menos tokens virtuais. Ele também obtém desempenho de OCR gratuito de última geração para documentos de várias páginas e funções de compreensão de vídeo rico em texto com latência muito baixa. Os pesquisadores enfatizam que usar milhares de tokens visuais para cada página de texto é muitas vezes impraticável e um desperdício de recursos computacionais. Eles esperam que o DocOwl2 chame a atenção para equilibrar a representação eficaz de imagens com a compreensão altamente eficiente de documentos.
Confira Papel e GitHub. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter de novo LinkedIn. Junte-se a nós Estação telefônica.
Se você gosta do nosso trabalho, você vai gostar do nosso jornal..
Não se esqueça de participar do nosso Mais de 50k ML SubReddit
Asjad é consultor estagiário na Marktechpost. Ele está cursando B.Tech em engenharia mecânica no Instituto Indiano de Tecnologia, Kharagpur. Asjad é um entusiasta do aprendizado de máquina e do aprendizado profundo que pesquisa regularmente a aplicação do aprendizado de máquina na área da saúde.
🐝 Participe do boletim informativo de pesquisa de IA de crescimento mais rápido, lido por pesquisadores do Google + NVIDIA + Meta + Stanford + MIT + Microsoft e muito mais…


