
Os modelos de transformadores impulsionaram grandes avanços na inteligência artificial, permitindo aplicações em processamento de linguagem natural, visão computacional e reconhecimento de fala. Esses modelos são excelentes na compreensão e geração de dados sequenciais usando métodos como atenção multicabeças para capturar relacionamentos entre sequências de entrada. A ascensão de modelos de linguagem em larga escala (LLMs) construídos sobre transformadores expandiu essas capacidades, permitindo tarefas que vão desde o raciocínio complexo até a geração de conteúdo criativo.
No entanto, o tamanho crescente dos LLMs e a complexidade custam à eficiência computacional. Esses modelos dependem fortemente de camadas totalmente conectadas e tarefas de atenção com múltiplas cabeças, que exigem recursos significativos. Em muitas situações práticas, as camadas totalmente conectadas dominam a carga computacional, tornando um desafio dimensionar esses modelos sem incorrer em altos custos de energia e hardware. Esta ineficiência limita a sua acessibilidade e escalabilidade numa vasta gama de indústrias e aplicações.
Vários métodos foram propostos para lidar com restrições computacionais em modelos de transformadores. Técnicas como poda e ponderação de modelos melhoraram moderadamente o desempenho, reduzindo o tamanho e a precisão do modelo. O redesenho do mecanismo de atenção, como atenção de linha e flash, reduziu sua complexidade computacional de quadrática para linear em relação ao comprimento da sequência. Porém, esses métodos geralmente precisam prestar mais atenção à contribuição de camadas totalmente conectadas, deixando grande parte do cálculo sem correção.
Pesquisadores da Universidade de Pequim, Huawei Noah's Ark Lab e Huawei HiSilicon apresentaram o MemoryFormer. Essa estrutura de transformador elimina camadas computacionalmente caras totalmente conectadas, substituindo-as por camadas de memória. Essas camadas usam tabelas de pesquisa na memória e algoritmos de hashing sensíveis à localidade (LSH). MemoryFormer visa transformar a entrada incorporada recuperando representações vetoriais pré-computadas da memória em vez de realizar a multiplicação usual de matrizes.
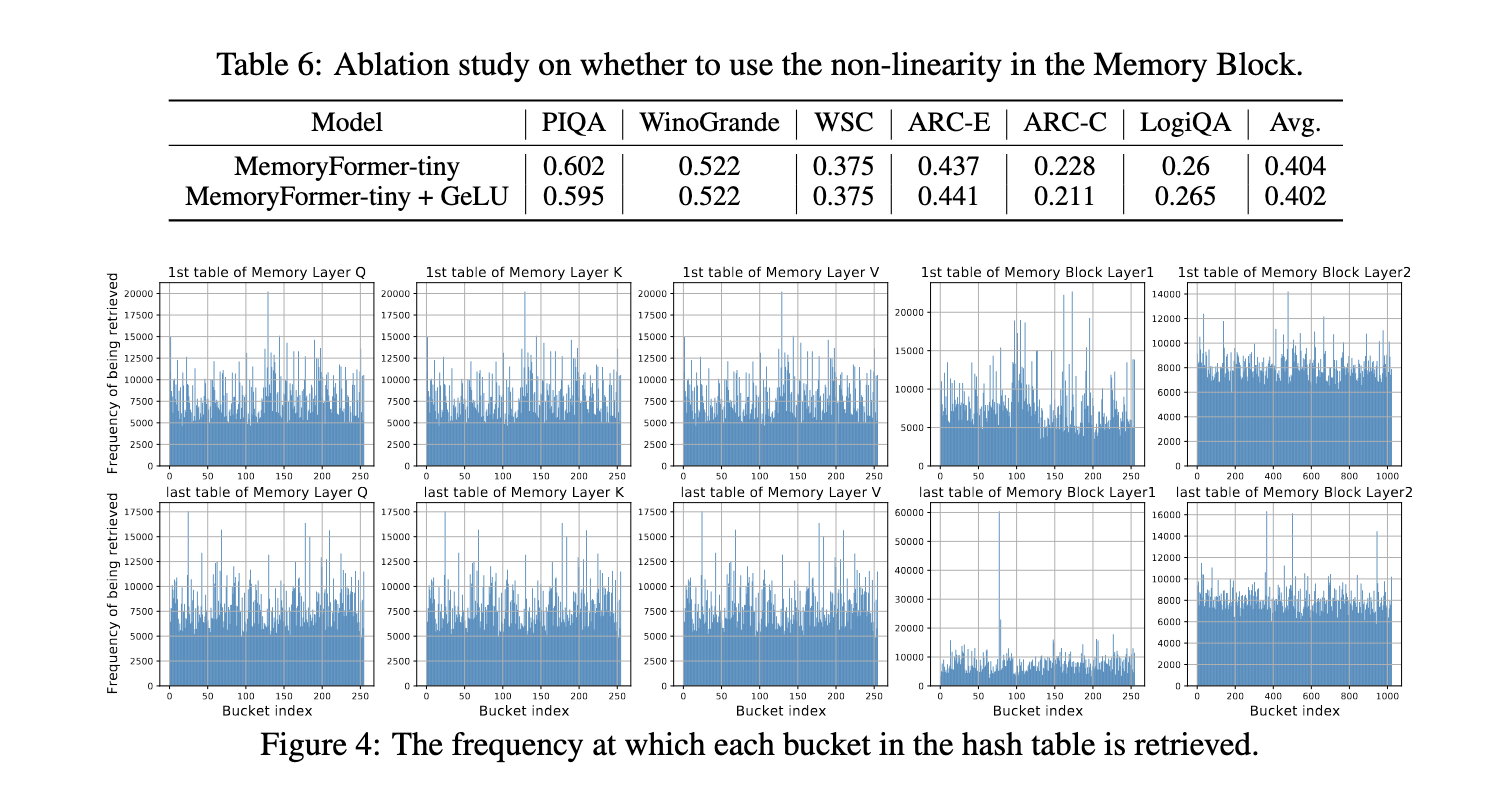
A principal inovação do MemoryFormer está no design da camada de memória. Em vez de fazer suposições lineares diretamente, a incorporação da entrada é acelerada usando um algoritmo de hash sensível à localização. Esta técnica mapeia os mesmos embeddings para os mesmos locais de memória, permitindo ao modelo recuperar vetores previamente armazenados que aproximam os resultados da multiplicação de matrizes. Ao quebrar o incorporado em pedaços menores e processá-los de forma independente, o MemoryFormer reduz os requisitos de memória e a carga de computação. A arquitetura também inclui vetores legíveis em tabelas hash, permitindo que o modelo seja treinado de ponta a ponta usando retropropagação. Esse design garante que o MemoryFormer possa lidar com uma variedade de tarefas enquanto mantém a eficiência.
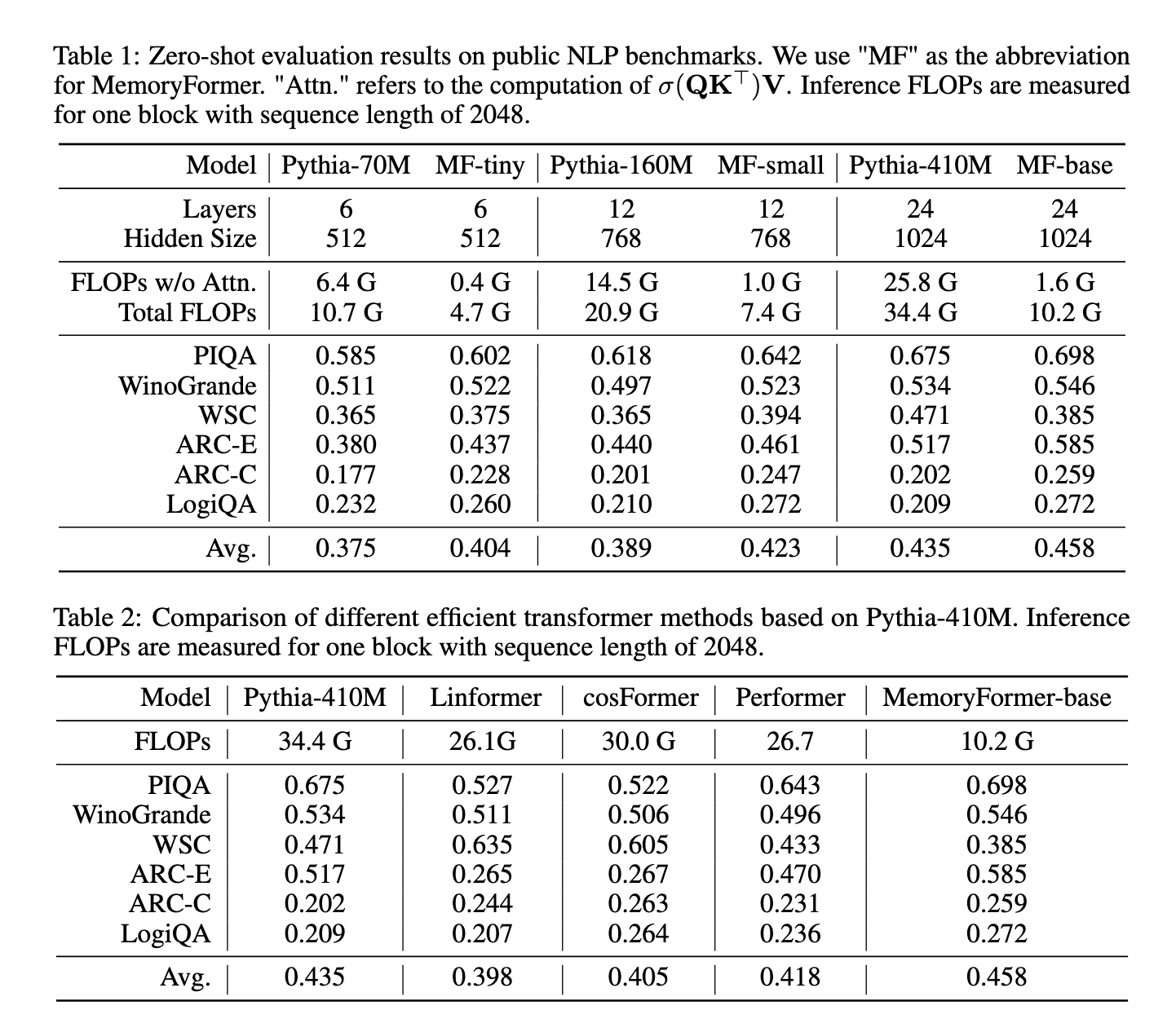
MemoryFormer demonstrou desempenho e eficiência excepcionais durante testes em vários benchmarks de PNL. Com um comprimento de sequência de 2.048 tokens, o MemoryFormer reduziu a complexidade computacional de camadas totalmente conectadas em mais de uma ordem de magnitude. Os FLOPs calculados do MemoryFormer foram reduzidos para apenas 19% dos requisitos de um bloco transformador convencional. Para algumas tarefas, como PIQA e ARC-E, o MemoryFormer alcançou pontuações de precisão de 0,698 e 0,585, respectivamente, superando os modelos básicos de transformadores. A precisão média geral para todas as funções testadas também melhorou, destacando a capacidade do modelo de manter ou melhorar o desempenho e, ao mesmo tempo, reduzir significativamente a sobrecarga computacional.
Os pesquisadores compararam o MemoryFormer com métodos de conversão existentes que funcionam, incluindo Linformer, Performer e Cosformer. MemoryFormer superou consistentemente esses modelos em termos de eficiência computacional e precisão de benchmark. Por exemplo, comparado ao Performer e ao Linformer, que alcançaram uma precisão média de 0,418 e 0,398, respectivamente, o MemoryFormer atingiu 0,458 usando menos recursos. Tais resultados enfatizam o desempenho da Camada de Memória na melhoria das propriedades do transformador.
Concluindo, MemoryFormer aborda as limitações dos modelos de transformadores, reduzindo as demandas de computação usando novas camadas de memória. Os pesquisadores demonstraram uma maneira flexível de medir o desempenho e a eficiência, substituindo camadas totalmente conectadas por funções de memória. Essa arquitetura fornece uma maneira rápida de derivar modelos de linguagem em larga escala em uma variedade de aplicações, garantindo acessibilidade e estabilidade sem comprometer a precisão ou a potência.
Confira Papel. Todo o crédito deste estudo vai para os pesquisadores deste projeto. Além disso, não se esqueça de nos seguir Twitter e junte-se ao nosso Estação telefônica de novo LinkedIn Gracima. Se você gosta do nosso trabalho, você vai gostar do nosso jornal.. Não se esqueça de participar do nosso SubReddit de 55k + ML.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Conferência Virtual GenAI gratuita com. Meta, Mistral, Salesforce, Harvey AI e mais. Junte-se a nós em 11 de dezembro para este evento de visualização gratuito para aprender o que é necessário para construir grande com pequenos modelos de pioneiros em IA como Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face e muito mais.
Nikhil é consultor estagiário na Marktechpost. Ele está cursando dupla graduação em Materiais no Instituto Indiano de Tecnologia, Kharagpur. Nikhil é um entusiasta de IA/ML que pesquisa constantemente aplicações em áreas como biomateriais e ciências biomédicas. Com sólida formação em Ciência de Materiais, ele explora novos desenvolvimentos e cria oportunidades para contribuir.
🐝🐝 Leia este relatório de pesquisa de IA da Kili Technology 'Avaliação de vulnerabilidade de um modelo de linguagem grande: uma análise comparativa de métodos de passagem vermelha'


